The Intel 9th Gen Review: Core i9-9900K, Core i7-9700K and Core i5-9600K Tested
by Ian Cutress on October 19, 2018 9:00 AM EST- Posted in
- CPUs
- Intel
- Coffee Lake
- 14++
- Core 9th Gen
- Core-S
- i9-9900K
- i7-9700K
- i5-9600K
Gaming: Ashes Classic (DX12)
Seen as the holy child of DirectX12, Ashes of the Singularity (AoTS, or just Ashes) has been the first title to actively go explore as many of the DirectX12 features as it possibly can. Stardock, the developer behind the Nitrous engine which powers the game, has ensured that the real-time strategy title takes advantage of multiple cores and multiple graphics cards, in as many configurations as possible.

As a real-time strategy title, Ashes is all about responsiveness during both wide open shots but also concentrated battles. With DirectX12 at the helm, the ability to implement more draw calls per second allows the engine to work with substantial unit depth and effects that other RTS titles had to rely on combined draw calls to achieve, making some combined unit structures ultimately very rigid.
Stardock clearly understand the importance of an in-game benchmark, ensuring that such a tool was available and capable from day one, especially with all the additional DX12 features used and being able to characterize how they affected the title for the developer was important. The in-game benchmark performs a four minute fixed seed battle environment with a variety of shots, and outputs a vast amount of data to analyze.
For our benchmark, we run Ashes Classic: an older version of the game before the Escalation update. The reason for this is that this is easier to automate, without a splash screen, but still has a strong visual fidelity to test.
| AnandTech CPU Gaming 2019 Game List | ||||||||
| Game | Genre | Release Date | API | IGP | Low | Med | High | |
| Ashes: Classic | RTS | Mar 2016 |
DX12 | 720p Standard |
1080p Standard |
1440p Standard |
4K Standard |
|
Ashes has dropdown options for MSAA, Light Quality, Object Quality, Shading Samples, Shadow Quality, Textures, and separate options for the terrain. There are several presents, from Very Low to Extreme: we run our benchmarks at the above settings, and take the frame-time output for our average and percentile numbers.
All of our benchmark results can also be found in our benchmark engine, Bench.
| Ashes Classic | IGP | Low | Medium | High |
| Average FPS | 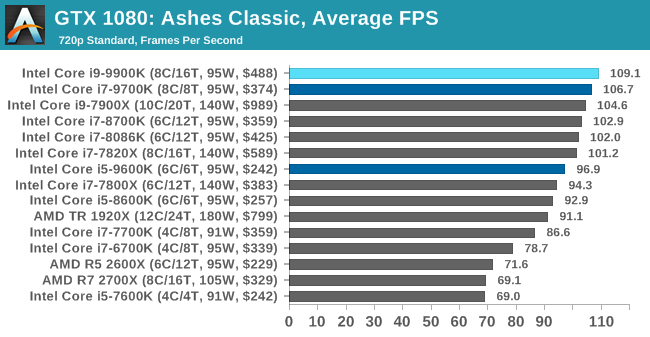 |
 |
 |
 |
| 95th Percentile | 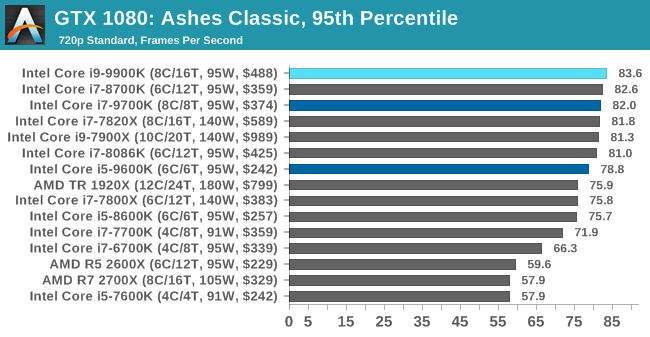 |
 |
 |
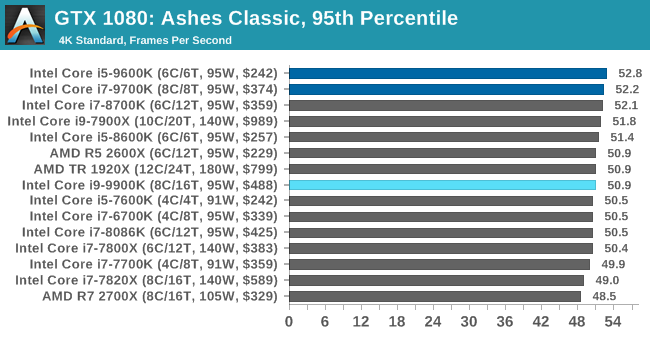 |
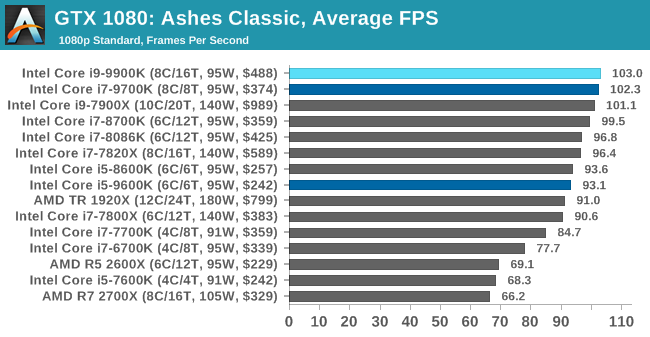
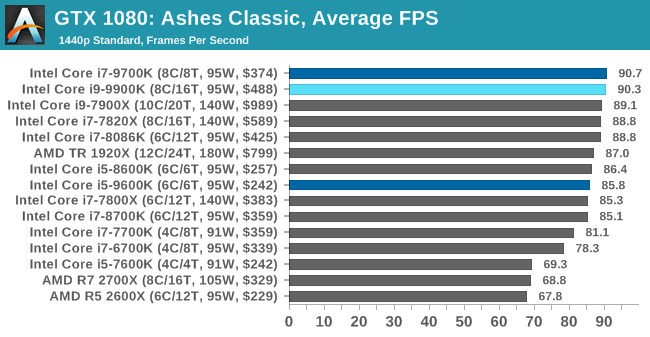
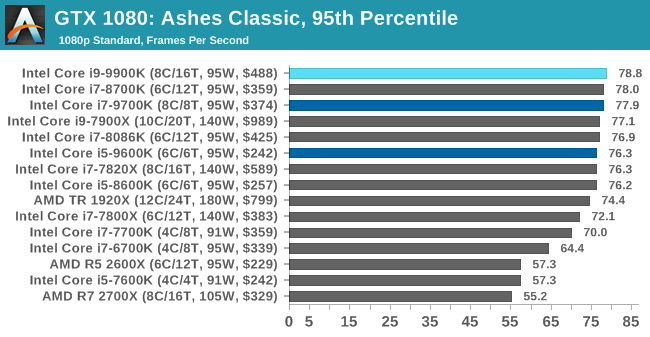
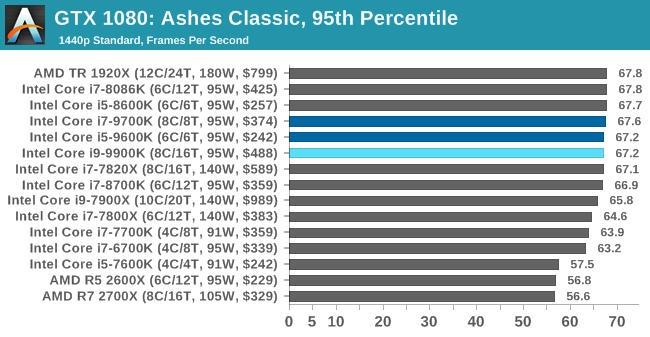
As a game that was designed from the get-go to punish CPUs and showcase the benefits of DirectX 12-style APIs, Ashes is one of our more CPU-sensitive tests. Above 1080p results still start running together due to GPU limits, but at or below that, we get some useful separation. In which case what we see is that the 9900K ekes out a small advantage, putting it in the lead and with the 9700K right behind it.
Notably, the game doesn’t scale much from 1080p down to 720p. Which leads me to suspect that we’re looking at a relatively pure CPU bottleneck, a rarity in modern games. In which case it’s both good and bad for Intel’s latest CPU; it’s definitely the fastest thing here, but it doesn’t do much to separate itself from the likes of the 8700K, holding just a 4% advantage at 1080p. This being despite its frequency and core count advantage. So assuming this is not in fact a GPU limit, then it means we may be encroaching on another bottleneck (memory bandwidth?), or maybe the practical frequency gains on the 9900K just aren’t all that much here.
But if nothing else, the 9900K and even the 9700K do make a case for themselves here versus the 9600K. Whether it’s the core or the clockspeeds, there’s a 10% advantage for the faster processors at 1080p.








274 Comments
View All Comments
Total Meltdowner - Sunday, October 21, 2018 - link
Those typoes.."Good, F U foreigners who want our superior tech."
muziqaz - Monday, October 22, 2018 - link
Same to you, who still thinks that Intel CPUs are made purely in USA :DHifihedgehog - Friday, October 19, 2018 - link
What do I think? That it is a deliberate act of desperation. It looks like it may draw more power than a 32-Core ThreadRipper per your own charts.https://i.redd.it/iq1mz5bfi5t11.jpg
AutomaticTaco - Saturday, October 20, 2018 - link
Revisedhttps://www.anandtech.com/show/13400/intel-9th-gen...
The motherboard in question was using an insane 1.47v
https://twitter.com/IanCutress/status/105342741705...
https://twitter.com/IanCutress/status/105339755111...
edzieba - Friday, October 19, 2018 - link
For the last decade, you've had the choice between "I want really fast cores!" and "I want lots of cores!". This is the 'now you can have both' CPU, and it's surprisingly not in the HEDT realm.evernessince - Saturday, October 20, 2018 - link
It's priced like HEDT though. It's priced well into HEDT. FYI, you could have had both of those when the 1800X dropped.mapesdhs - Sunday, October 21, 2018 - link
I noticed initially in the UK the pricing of the 9900K was very close to the 7820X, but now pricing for the latter has often been replaced on retail sites with CALL. Coincidence? It's almost as if Intel is trying to hide that even Intel has better options at this price level.iwod - Friday, October 19, 2018 - link
Nothing unexpected really. 5Ghz with "better" node that is tuned for higher Frequency. The TDP was the real surprise though, I knew the TDP were fake, but 95 > 220W? I am pretty sure in some countries ( um... EU ) people can start suing Intel for misleading customers.For the AVX test, did the program really use AMD's AVX unit? or was it not optimised for AMD 's AVX, given AMD has a slightly different ( I say saner ) implementation. And if they did, the difference shouldn't be that big.
I continue to believe there is a huge market for iGPU, and I think AMD has the biggest chance to capture it, just looking at those totally playable 1080P frame-rate, if they could double the iGPU die size budget with 7nm Ryzen it would be all good.
Now we are just waiting for Zen 2.
GreenReaper - Friday, October 19, 2018 - link
It's using it. You can see points increased in both cases. But AMD implemented AVX on the cheap. It takes twice the cycles to execute AVX operations involving 256-bit data, because (AFAIK) it's implemented using 128-bit registers, with pairs of units that can only do multiplies or adds, not both.That may be the smart choice; it probably saves significant space and power. It might also work faster with SSE[2/3/4] code, still heavily used (in part because Intel has disabled AVX support on its lower-end chips). But some workloads just won't perform as well vs. Intel's flexible, wider units. The same is true for AVX-512, where the workstation chips run away with it.
It's like the difference between using a short bus, a full-sized school bus, and a double decker - or a train. If you can actually fill the train on a regular basis, are going to go a long way on it, and are willing to pay for the track, it works best. Oh, and if developers are optimizing AVX code for *any* CPU, it's almost certainly Intel, at least first. This might change in the future, but don't count on it.
emn13 - Saturday, October 20, 2018 - link
Those AVX numbers look like they're measuing something else; not just AVX512. You'd expect performance to increase (compared to AVX256) by around 50%, give or take quite a margin of error. It should *never* be more than a factor 2 faster. So ignore AMD; their AVX implementation is wonky, sure - but those intel numbers almost have to be wrong. I think the baseline isn't vectorized at all, or something like that - that would explain the huge jump.Of course, AVX512 is fairly complicated, and it's more than just wider - but these results seem extraordinary; and there' just not enough evidence the effect is real, not just some quirk of how the variations were compiled.