Intel Server Roadmap: 14nm Cooper Lake in 2019, 10nm Ice Lake in 2020
by Ian Cutress & Anton Shilov on August 8, 2018 12:57 PM EST- Posted in
- Servers
- Xeon
- Ice Lake
- Cascade Lake
- Cooper Lake

At its Data-Centric Innovation Summit in Santa Clara today, Intel unveiled its official Xeon roadmap for 2018 – 2019. As expected, the company confirmed its upcoming Cascade Lake, Cooper Lake-SP and Ice Lake-SP platforms.
Later this year Intel will release its Cascade Lake server platform, which will feature CPUs that bring support for hardware security mitigations against side-channel attacks through partitioning. In addition, the new Cascade Lake chips will also support AVX512_VNNI instructions for deep learning (originally expected to be a part of the Ice Lake-SP chips, but inserted into an existing design a generation earlier).
Moving on to the next gen. Intel's Cooper Lake-SP will be launched in 2019, several quarters ahead of what was reported several weeks ago. Cooper Lake processors will still be made using a 14 nm process technology, but will support some functional improvements, including the BFLOAT16 feature. By contrast, the Ice Lake-SP platform is due in 2020, just as expected.

One thing to note about Intel’s Xeon launch schedules is that the Cascade Lake will ship in Q4 2018, several months from now. Normally, Intel does not want to create internal competition and release new server platforms too often. That said, it sounds like we should expect Cooper Lake-SP to launch in late 2019 and Ice Lake-SP to hit the market in late 2020. To make it clear: Intel has not officially announced launch timeframes for its CPL and ICL Xeon products and the aforementioned periods should be considered as educated guesses.
| Intel's Server Platform Cadence | ||||
| Platform | Process Node | Release Year | ||
| Haswell-E | 22nm | 2014 | ||
| Broadwell-E | 14nm | 2016 | ||
| Skylake-SP | 14nm+ | 2017 | ||
| Cascade Lake-SP | 14nm++? | 2018 | ||
| Cooper Lake-SP | 14nm++? | 2019 | ||
| Ice Lake-SP | 10nm+ | 2020 | ||
While the Cascade Lake will largely rely on the Skylake-SP hardware platform introduced last year (albeit with some significant improvements when it comes to memory support), the Cooper Lake and Ice Lake will use a brand-new hardware platform. As discovered a while back, that Cooper Lake/Ice Lake server platform will use LGA4189 CPU socket and will support an eight-channel per-socket memory sub-system.
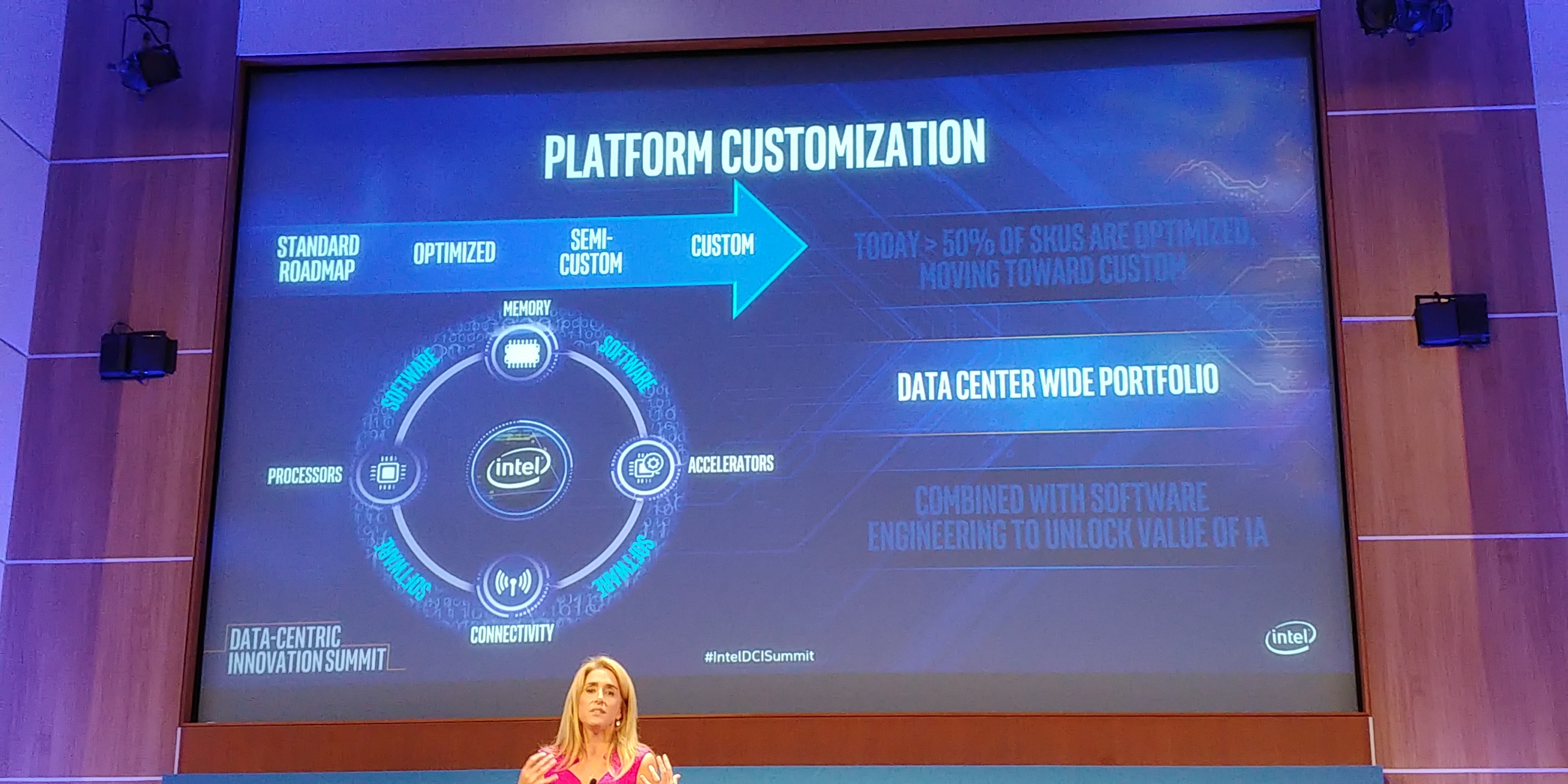
Intel has long understood that one size does not fit all, and that many of its customers need customized/optimized Xeon chips to run their unique applications and algorithms. Google was the first company to get a semi-custom Xeon back in 2008, and today over a half of Intel Xeon processors are customized for particular workloads at particular customers. That said, many of Intel’s future Xeons will feature unique capabilities only available to select clients. In fact, the latter want to keep their IP confidential, so these chips will be kept off Intel’s public roadmap. Meanwhile, as far as Intel’s CPUs and platforms are concerned, both should be ready for various ways of customization whether it is silicon IP, binning for extra speed, or adding discrete special-purpose accelerators.
Overall there are several key elements to the announcement.
Timeline and Competition
What is not clear is timeline. Intel has historically been on a 12-18 month cadence when it comes to new server processor families. As it stands, we expect Cascade Lake to hit in Q4 2018. If Cooper Lake is indeed in 2019, then even if we went on the lower bound of at 12-18 month gap then we would still be looking at Q4 2019. Step forward to Ice Lake, which Intel has listed as 2020. Again, this sounds like another 12 month jump, on the edge of that 12-18 month typical gap. This tells us two things:
Firstly, Intel is pushing the server market to update and update quickly. Typical server markets have a slow update cycle, so Intel is expected to push its new products hoping to offer something special above the previous generation. Aside from the options listed below, and depending on how the product stack looks like, there is nothing listed about the silicon which should drive that updates.
Secondly, if Intel wants to keep revenues high, it would have to increase prices for those that can take advantage of the new features. Some media have reported that the price of the new parts will be increased to compensate the fewer reasons to upgrade to keep overall revenue high.
Security Mitigations
This is going to be a big question mark. With the advent of Spectre and Meltdown, and other side channel attacks, Intel and Microsoft have scrambled to fix the issues mostly through software. The downside of these software fixes is that sometimes they cause performance slowdowns – in our recent Xeon W using Skylake-SP cores, we saw up to a 3-10% performance decreases. At some point we are expecting the processors to implement hardware fixes, and one of the questions will be on the effect on performance that these fixes give.
The fact that the slide mentions security mitigations is confusing – are they hardware or software? (Confirmed hardware) What is the performance impact? (None to next-to-none) Will this require new chipsets to enable? Will this harden against future side channel attacks? (Hopefully) What additional switches are in the firmware for these?
Updated these questions with answers from our interview with Lisa Spelman. Our interview with Lisa will be posted next week (probably).
New Instructions
Running in line with new instructions will be VNNI for Cascade Lake and bfloat16 for Cooper Lake. It is likely that Ice Lake will have new instructions too, but those are not mentioned at this time.
VNNI, or Variable Length Neural Network Instructions, is essentially the ability to support 8-bit INT using the AVX-512 units. This will be one step towards assisting machine learning, which Intel cited as improving performance (along with software enhancements) of 11x compared to when Skylake-SP was first launched. VNNI4, a variant of VNNI, was seen in Knights Mill, and VNNI was meant to be in Ice Lake, but it would appear that Intel is moving this into Cascade Lake. It does make me wonder exactly what is needed to enable VNNI on Cascade compared to what wasn’t possible before, or whether this was just part of Intel’s expected product segmentation.
Also on the cards is the support for bfloat16 in Cooper Lake. bfloat16 is a data format, used most recently by Google, like a 16-bit float but in a different way. The letter ‘b’ in this case stands for brain, with the data format expected for deep learning. How it differs regarding a standard 16-bit float is in how the number is defined.
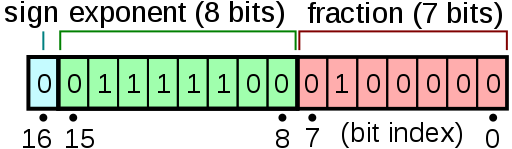
A standard float has the bits split into the sign, the exponent, and the fraction. This is given as:
- <sign> * 1 + <fraction> * 2<exponent>
For a standard IEEE754 compliant number, the standard for computing, there is one bit for the sign, five bits for the exponent, and 10 bits for the fraction. The idea is that this gives a good mix of precision for fractional numbers but also offer numbers large enough to work with.
What bfloat16 does is use one bit for the sign, eight bits for the exponent, and 7 bits for the fraction. This data type is meant to give 32-bit style ranges, but with reduced accuracy in the fraction. As machine learning is resilient to this type of precision, where machine learning would have used a 32-bit float, they can now use a 16-bit bfloat16.
These can be represented as:
| Data Type Representations | ||||||
| Type | Bits | Exponent | Fraction | Precision | Range | Speed |
| float32 | 32 | 8 | 23 | High | High | Slow |
| float16 | 16 | 5 | 10 | Low | Low | 2x Fast |
| bfloat16 | 16 | 8 | 7 | Lower | High | 2x Fast |

This is a breaking news that will be updated as we receive more information.
Related Reading:
- Intel 10nm Production Update: Systems on Shelves For Holiday 2019
- Intel’s Xeon Scalable Roadmap Leaks: Cooper Lake-SP, Ice Lake-SP Due in 2020
- Power Stamp Alliance Exposes Ice Lake Xeon Details: LGA4189 and 8-Channel Memory
- Intel’s High-End Cascade Lake CPUs to Support 3.84 TB of Memory Per Socket
- Intel Documents Point to AVX-512 Support for Cannon Lake Consumer CPUs
- Intel Begins EOL Plan for Xeon Phi 7200-Series ‘Knights Landing’ Host Processors
- Intel Shows Xeon Scalable Gold 6138P with Integrated FPGA, Shipping to Vendors
- Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?








51 Comments
View All Comments
wumpus - Wednesday, August 8, 2018 - link
Note: 32 bit floating point can't be called "high precision".Ok, it might be "high precision" when the numbers go in and you might be fooled into thinking they are when they come out, but any kind of heavy math simulation will need 64 bit numbers. 32 bit numbers might also be overkill for graphics, but they use them anyway.
- If you don't believe me, try doing a 32k point FFT on some audio (which is only 16 bit) and back in single point. The audio won't have 10 bits of accuracy when you are done, and each point was only involved in ~15 operations.
hpvd - Thursday, August 9, 2018 - link
Since LGA4189 is coming relatively soon, what do you think: will there be DDR5 support or do we have to wait for the next platform in 2021+ ?wow&wow - Thursday, August 9, 2018 - link
At least, starting from Cascade Lake, there won't be OS kernel relocation, such a JOKE in the processor industry!!!iwod - Thursday, August 9, 2018 - link
New socket for CooperLake? And 8 memory channel? Now that is some competition. I assume Intel may want to bump the core count o 32 to combat AMD.Which makes me slightly worry for AMD, if the price between EPYC 2 and CooperLake is within 20% I don't think many will be choosing EPYC.
NikosD - Friday, August 10, 2018 - link
EPYC 2 will start at 48C/96T and later 64C/128T.Nothing to compete here for Intel.
AMD will exceed 20% server market share at the end of 2019.
rahvin - Friday, August 10, 2018 - link
Lets not forget Intel is raising prices again to keep their revenue the same while AMD takes marketshare. The top end Xeon Platinum is going from $13K to $20K where the AMD Rome that's comparable (Rome will be faster) will be 40% of that price.Intel has some long dark days ahead of it that will be comparable to what they experienced with Pentium 4. They emptied their bench to stay competitive with Epyc and Threadripper and they've got nothing going for the future because of the process blowup. Instead they are going to respin at 14nm essentially the same thing they've got now while Rome is sampling right now and should be in production by years end. Intel won't be able to get legs back under them until 2020 at the earliest and AMD is likely to be so far ahead at that point that it'll probably be till 2022 before they can catch up. That will definitely make this worse than P4.
The hope is that this competition will force Intel to cut prices and drive down consumer prices. Let us pray.
TomWomack - Saturday, August 11, 2018 - link
Yes, AMD will put four dice onto a large hot MCM, linked by slightly drier string than last time. Still not playing in the same league as Xeon Gold, and much larger manufacturing costs.Dr. Swag - Wednesday, August 15, 2018 - link
Ah yes, it costs more to put together a few smaller dies than using one larger one. Because that's how yields work /sSanX - Thursday, August 9, 2018 - link
Why ARM keeps mum distancing from this ultrahigh margin market of server/supercomputer chips where prices are already almost 2 orders of magnitude from production cost?TomWomack - Saturday, August 11, 2018 - link
Because ARM doesn't manufacture chips - it has the skills to, but not the enormous capital requirements, and if it tried then its chip-manufacturing partners would suddenly stop being its partners.Intel has an amazing reputation in server chips: a competitor would have to sell their chips at a third the price of Intel's (at least, Cavium and Qualcomm have both placed them at that sort of price point), and Intel is in a good position to drop their price 30% and remove the competitor's profit margin.
Fujitsu is showing off its ARM supercomputer chip at Hot Chips 30 on 21st August.