The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTHEDT Benchmarks: Rendering Tests
Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice.
Corona 1.3: Performance Render
An advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand.
The Corona benchmark website can be found at https://corona-renderer.com/benchmark
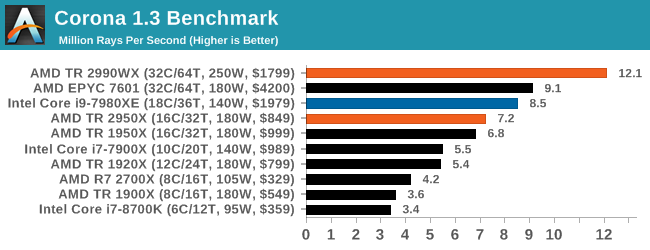
So this is where AMD broke our graphing engine. Because we report Corona in rays per second, having 12 million of them puts eight digits into our engine, which it then tries to interpret as a scientific number (1.2 x 10^7), which it can’t process in a graph. We had to convert this graph into millions of rays per second to get it to work.
The 2990WX hits out in front with 32 cores, with its higher frequency being the main reason it is so far ahead of the EPYC processor. The EPYC and Core i9 are close together, however the TR2950X at half the cost comes reasonably close.
Blender 2.79b: 3D Creation Suite
A high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render.
Blender can be downloaded at https://www.blender.org/download/
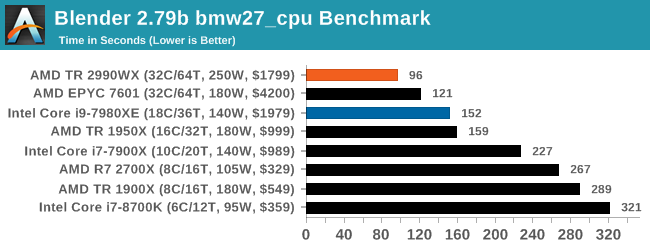
The additional cores on the 2990WX puts it out ahead of the EPYC and Core i9, with the 2990WX having an extra 58% throughput over the Core i9. That is very substantial indeed.
LuxMark v3.1: LuxRender via Different Code Paths
As stated at the top, there are many different ways to process rendering data: CPU, GPU, Accelerator, and others. On top of that, there are many frameworks and APIs in which to program, depending on how the software will be used. LuxMark, a benchmark developed using the LuxRender engine, offers several different scenes and APIs.
Taken from the Linux Version of LuxMark
In our test, we run the simple ‘Ball’ scene on both the C++ and OpenCL code paths, but in CPU mode. This scene starts with a rough render and slowly improves the quality over two minutes, giving a final result in what is essentially an average ‘kilorays per second’.
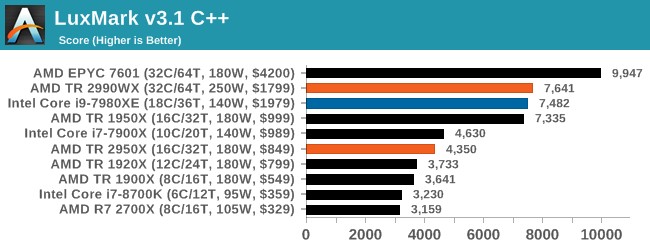
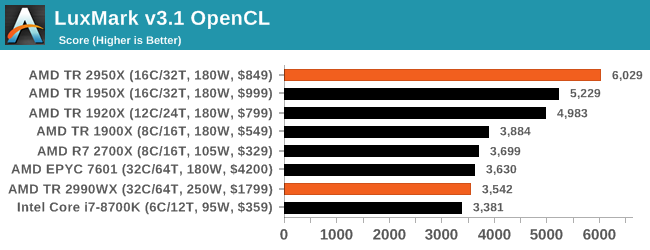
Intel’s Skylake-X processors seem to fail our OpenCL test for some reason, but in the C++ test the extra memory controllers on EPYC sets it ahead of both TR2 and Core i9. The 2990WX and Core i9 are almost equal here.
POV-Ray 3.7.1: Ray Tracing
The Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line.
POV-Ray can be downloaded from http://www.povray.org/
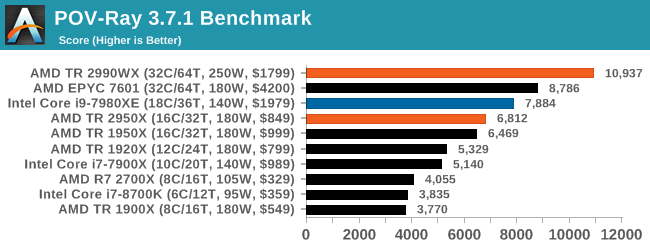
This test is another that loves the cores and frequency of the 2990WX, finishing the benchmark in almost 20 seconds. It might be time for a bigger built-in benchmark.








171 Comments
View All Comments
T1beriu - Monday, August 13, 2018 - link
> We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. [...]It seems that Tomshardware says the opposite:
>AMD continues working with Microsoft to route threads to the die with direct-attached memory first, and then spill remaining threads over to the compute dies. Unfortunately, the scheduler currently treats all dies as equal, operating in Round Robin mode. [...] According to AMD, Microsoft has not committed to a timeline for updating its scheduler.
Ian Cutress - Monday, August 13, 2018 - link
Yeah, Paul and I were discussing this. It is a round robin mode, but it's weighted based on available resources, thermal performance, proximity of busy threads, etc.JoeyJoJo123 - Monday, August 13, 2018 - link
Maybe just user error, but all the article pages between Test Setup and Comparison Results to Going up Against Epyc, just have the text "Still writing...". I'm unsure if the article is actually still being written and was supposed to be published in this partial manner or if possible something was lost between writing and upload.In any case, kind of crazy how the infinity fabric is consuming so much power. The cores look super-efficient, but if the uncore can get efficiency improvements, that can help the Zen architecture stay even more efficient under load. Intel's uncore consumes a fraction of the wattage, but doesn't scale as well for multiple threads.
Ian Cutress - Monday, August 13, 2018 - link
Still being written. See my comment at the top. Unfortunately travel back and forth from UK to SF bit me over the weekend and I lost a couple of days testing, along with having to take a full benchmark set up with me to SF to test in the hotel room.JoeyJoJo123 - Monday, August 13, 2018 - link
I understand, take your rest. You don't need to reply to me, I actually saw the reason after I posted.compilerdev2 - Monday, August 13, 2018 - link
Hi Ian,I have some questions about the Chromium compilation benchmark, since I was hoping to get the 2990WX for compiling large C++ apps. What version of Chromium is used? Is the compiler being used Clang-CL or Visual C++? Is the build in debug or release (optimized) mode? If it's release mode with Visual C++, does it use LTCG? (link-time code generation, the equivalent of LTO of gcc/clang). For example, if the build is Visual C++ LTCG, the entire code optimization, code generation and linking is by default limited to 4 threads. Thanks!
Ian Cutress - Monday, August 13, 2018 - link
It's the standard Windows walkthrough available online. So we use a build of Chrome 62 (it was relevant when we pulled), VC++, build in release. It's done in the command line via ninja, and yes it does use LTCG.Destructions are here. They might be updated a little from when I wrote the benchmark. Out test is automated to keep consistency.
https://chromium.googlesource.com/chromium/src/+/m...
compilerdev2 - Monday, August 13, 2018 - link
With LTCG those strange results make sense - it's spending a lot of time on just 4 threads - actually majority of the time is on one thread for the Chromium case, it hits some current limitations of the VC++ compiler regarding CPU/memory usage that makes scaling worse for Chromium (but not for smaller programs or with non-LTCG builds). Increasing the number of threads from the default of 4 is possible, but will not help here. The frontend (parsing) work is well parallelized by Ninja, it's probably the reason why the Threadrippers do end up ahead of the faster single-core Intel CPUs. It would be interesting to see the benchmarks without LTCG, or even better, more compilation benchmarks, since these CPUs are really great for C/C++/Rust programmers.Nexus-7 - Monday, August 13, 2018 - link
Cool write-up on the uncore power usage! I especially enjoyed that part of the article.johnny_boy - Monday, August 13, 2018 - link
The Phoronix articles are more telling for the sort of workloads a 64 thread count would be used for.