The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTHEDT Benchmarks: Encoding Tests
With the rise of streaming, vlogs, and video content as a whole, encoding and transcoding tests are becoming ever more important. Not only are more home users and gamers needing to convert video files into something more manageable, for streaming or archival purposes, but the servers that manage the output also manage around data and log files with compression and decompression. Our encoding tasks are focused around these important scenarios, with input from the community for the best implementation of real-world testing.
Handbrake 1.1.0: Streaming and Archival Video Transcoding
A popular open source tool, Handbrake is the anything-to-anything video conversion software that a number of people use as a reference point. The danger is always on version numbers and optimization, for example the latest versions of the software can take advantage of AVX-512 and OpenCL to accelerate certain types of transcoding and algorithms. The version we use here is a pure CPU play, with common transcoding variations.
We have split Handbrake up into several tests, using a Logitech C920 1080p60 native webcam recording (essentially a streamer recording), and convert them into two types of streaming formats and one for archival. The output settings used are:
- 720p60 at 6000 kbps constant bit rate, fast setting, high profile
- 1080p60 at 3500 kbps constant bit rate, faster setting, main profile
- 1080p60 HEVC at 3500 kbps variable bit rate, fast setting, main profile
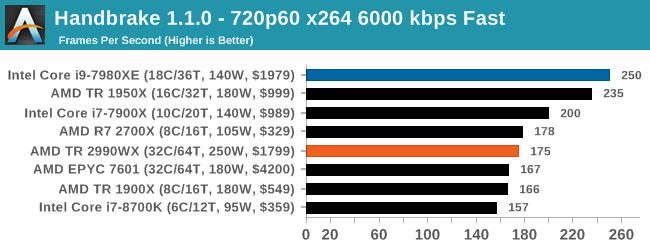
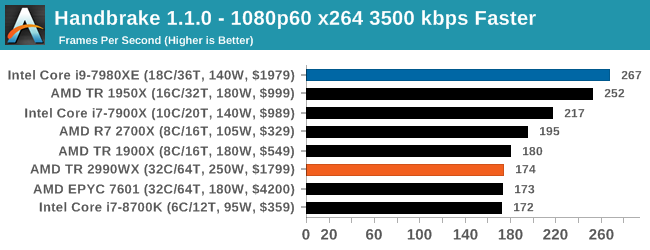
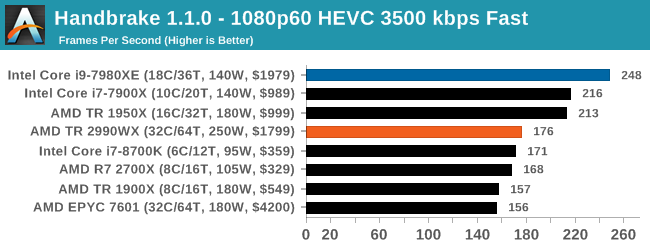
Video encoding is always an interesting mix of multi-threading, memory latency, and compute. The Core i9, with AVX2 instructions, sets a commanding lead in all three tests. The AMD processors seem to fluctuate a bit, with the 1950X and 2700X being the best of the bunch. Unfortunately we didn’t get 2950X results in our initial runs, but I would expect it to be competitive with the Core i9 for sure, given where the 1950X is. However the 2990WX does fall behind a bit.
7-zip v1805: Popular Open-Source Encoding Engine
Out of our compression/decompression tool tests, 7-zip is the most requested and comes with a built-in benchmark. For our test suite, we’ve pulled the latest version of the software and we run the benchmark from the command line, reporting the compression, decompression, and a combined score.
It is noted in this benchmark that the latest multi-die processors have very bi-modal performance between compression and decompression, performing well in one and badly in the other. There are also discussions around how the Windows Scheduler is implementing every thread. As we get more results, it will be interesting to see how this plays out.
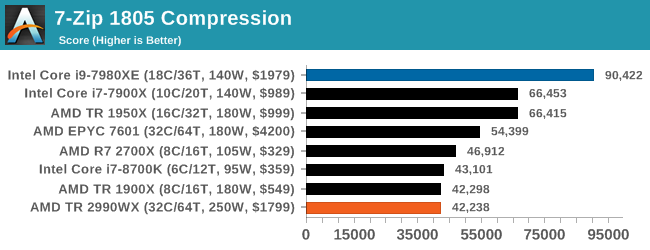
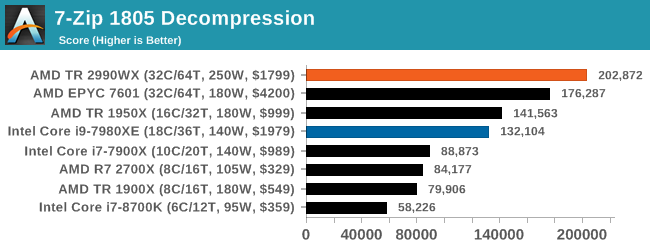
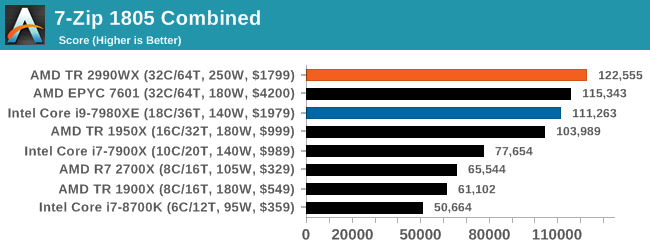
Oh boy, this was an interesting set of tests. When we initially published this review, without commentary, the compression graph with the 2990WX at the bottom was shared around social media like crazy, trying to paint a picture of why AMD performance isn’t great. It was also used in conjuction with Phoronix’s tests, that showed a much better picture on Linux.
But what confuses me is that almost no-one also posted the decompression graph. Here AMD’s 32-core processors take a commanding lead, with the 16/18-core parts being the best of the rest.
If you plan to share out the Compression graph, please include the Decompression one. Otherwise you’re only presenting half a picture.
WinRAR 5.60b3: Archiving Tool
My compression tool of choice is often WinRAR, having been one of the first tools a number of my generation used over two decades ago. The interface has not changed much, although the integration with Windows right click commands is always a plus. It has no in-built test, so we run a compression over a set directory containing over thirty 60-second video files and 2000 small web-based files at a normal compression rate.
WinRAR is variable threaded but also susceptible to caching, so in our test we run it 10 times and take the average of the last five, leaving the test purely for raw CPU compute performance.
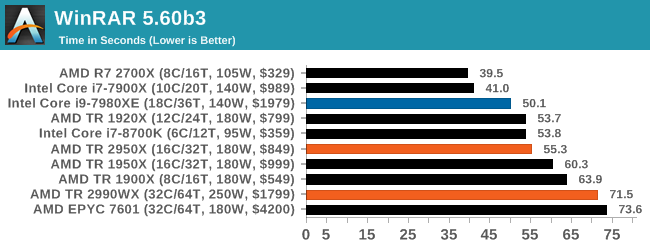
A set of high frequency cores and good memory is usually beneficial, but sometimes some more memory bandwidth and lower latency helps. At the top is AMD’s R7 2700X, with the Intel 10-core just behind. I’m surprised not to see the 8700K in there, perhaps its six cores is not enough. But the higher core count AMD parts struggle to gain traction here, with the 32-core parts taking some sweet time to finish this test.
AES Encryption: File Security
A number of platforms, particularly mobile devices, are now offering encryption by default with file systems in order to protect the contents. Windows based devices have these options as well, often applied by BitLocker or third-party software. In our AES encryption test, we used the discontinued TrueCrypt for its built-in benchmark, which tests several encryption algorithms directly in memory.
The data we take for this test is the combined AES encrypt/decrypt performance, measured in gigabytes per second. The software does use AES commands for processors that offer hardware selection, however not AVX-512.
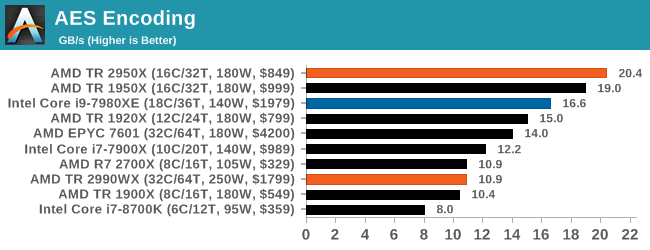
Normally we see this test go very well when there are plenty of cores, but it would seem that the bi-modal nature of the cores and memory controllers in the 2990WX gives a poor result. The EPYC 7601, with eight memory controllers, does a better job, however the 1950X wins here. The 2950X, where all cores have a similar access profile, scores top here, well above Intel’s 18-core Core i9.








171 Comments
View All Comments
T1beriu - Monday, August 13, 2018 - link
> We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. [...]It seems that Tomshardware says the opposite:
>AMD continues working with Microsoft to route threads to the die with direct-attached memory first, and then spill remaining threads over to the compute dies. Unfortunately, the scheduler currently treats all dies as equal, operating in Round Robin mode. [...] According to AMD, Microsoft has not committed to a timeline for updating its scheduler.
Ian Cutress - Monday, August 13, 2018 - link
Yeah, Paul and I were discussing this. It is a round robin mode, but it's weighted based on available resources, thermal performance, proximity of busy threads, etc.JoeyJoJo123 - Monday, August 13, 2018 - link
Maybe just user error, but all the article pages between Test Setup and Comparison Results to Going up Against Epyc, just have the text "Still writing...". I'm unsure if the article is actually still being written and was supposed to be published in this partial manner or if possible something was lost between writing and upload.In any case, kind of crazy how the infinity fabric is consuming so much power. The cores look super-efficient, but if the uncore can get efficiency improvements, that can help the Zen architecture stay even more efficient under load. Intel's uncore consumes a fraction of the wattage, but doesn't scale as well for multiple threads.
Ian Cutress - Monday, August 13, 2018 - link
Still being written. See my comment at the top. Unfortunately travel back and forth from UK to SF bit me over the weekend and I lost a couple of days testing, along with having to take a full benchmark set up with me to SF to test in the hotel room.JoeyJoJo123 - Monday, August 13, 2018 - link
I understand, take your rest. You don't need to reply to me, I actually saw the reason after I posted.compilerdev2 - Monday, August 13, 2018 - link
Hi Ian,I have some questions about the Chromium compilation benchmark, since I was hoping to get the 2990WX for compiling large C++ apps. What version of Chromium is used? Is the compiler being used Clang-CL or Visual C++? Is the build in debug or release (optimized) mode? If it's release mode with Visual C++, does it use LTCG? (link-time code generation, the equivalent of LTO of gcc/clang). For example, if the build is Visual C++ LTCG, the entire code optimization, code generation and linking is by default limited to 4 threads. Thanks!
Ian Cutress - Monday, August 13, 2018 - link
It's the standard Windows walkthrough available online. So we use a build of Chrome 62 (it was relevant when we pulled), VC++, build in release. It's done in the command line via ninja, and yes it does use LTCG.Destructions are here. They might be updated a little from when I wrote the benchmark. Out test is automated to keep consistency.
https://chromium.googlesource.com/chromium/src/+/m...
compilerdev2 - Monday, August 13, 2018 - link
With LTCG those strange results make sense - it's spending a lot of time on just 4 threads - actually majority of the time is on one thread for the Chromium case, it hits some current limitations of the VC++ compiler regarding CPU/memory usage that makes scaling worse for Chromium (but not for smaller programs or with non-LTCG builds). Increasing the number of threads from the default of 4 is possible, but will not help here. The frontend (parsing) work is well parallelized by Ninja, it's probably the reason why the Threadrippers do end up ahead of the faster single-core Intel CPUs. It would be interesting to see the benchmarks without LTCG, or even better, more compilation benchmarks, since these CPUs are really great for C/C++/Rust programmers.Nexus-7 - Monday, August 13, 2018 - link
Cool write-up on the uncore power usage! I especially enjoyed that part of the article.johnny_boy - Monday, August 13, 2018 - link
The Phoronix articles are more telling for the sort of workloads a 64 thread count would be used for.