Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Java Performance
The SPECjbb 2015 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
Note that we upgraded from SPECjbb version 1.0 to 1.01.
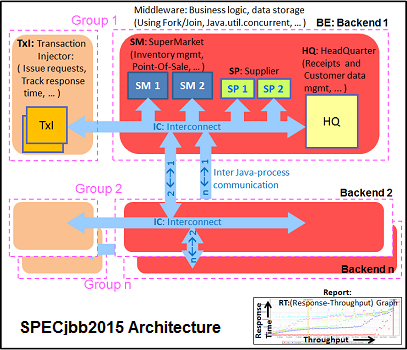
We tested SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice, especially on these 100+ threads servers. The Java version was OpenJDK 1.8.0_161.
Each time we publish SPECjbb numbers, several people tell us that our numbers are too low. So we decided to spend a bit more time and attention on the various settings.
However, it is important to understand that the SPECJbb numbers published by the hardware vendors are achieved with the following settings, which are hardly suitable for a production environment:
- Fiddling around with kernel settings like the timings of the task scheduler, page cache flushing
- Disabling energy saving features, manually setting c-state behavior
- Setting the fans at maximum speed, thus wasting a lot of energy for a few extra performance points
- Disabling RAS features (like memory scrub)
- Using a massive amount of Java tuning parameters. That is unrealistic because it means that every time an application is run on a different machine (which happens quite a bit in a cloud environment) expensive professionals have to revise these settings, which may potentially cause the application to halt on a different machine.
- Setting very SKU-specific NUMA settings and CPU bindings. Migrating between 2 different SKUs in the same cluster may cause serious performance problems.
We welcome constructive feedback, but in most production environments tuning should be simple and preferably not too machine-specific. To that end we applied two kinds of tuning. The first one is very basic tuning to measure "out of the box" performance, while aiming to fit everything inside a server with 128 GB of RAM:
For the second tuning, we went searching for the best throughput score, playing around with "-XX:+AlwaysPreTouch", "-XX:-UseBiasedLocking", and "specjbb.forkjoin.workers". "+AlwaysPretouch" zeroes out all of the memory pages before starting up, lowering the performance impact of touching new pages. "-UseBiasedLockin" disables biased locking, which is otherwise enabled by default. Biased locking gives the thread that already has loaded the contended data in the cache priority. The trade-off for using biased locking is some additional bookkeeping within the system, which in turn incurs a small performance hit overall if that strategy was not the right one.
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test.
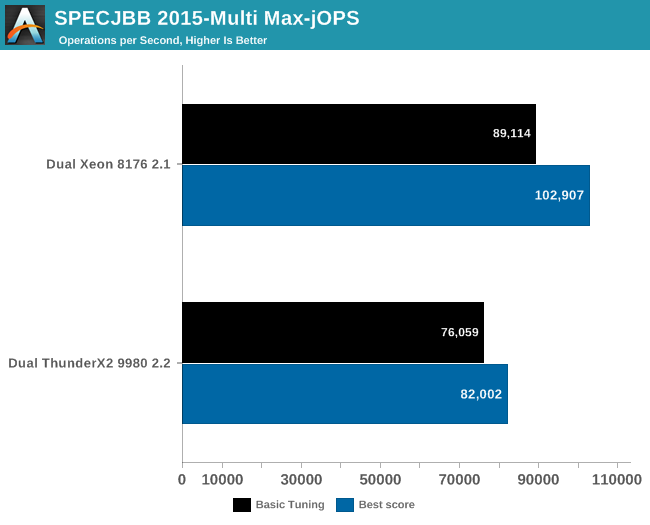
The ThunderX2 achieves 80& to 85% of the performance of the Xeon 8176. That should be high enough to beat the Xeon 6148. Interestingly, the top scores are achieved in different ways between the Intel and Cavium systems. In case of the Dual ThunderX2, we used:
Whereas the Intel system achieved best performance by leaving biased locking on (the default). We noticed that the Intel system – probably due to the relatively "odd" thread count – has a slightly lower average CPU load (a few percent) and a larger L3-cache, making biased locking a good strategy for the that architecture.
Finally, we have Critical-jOPS, which measures throughput under response time constraints.
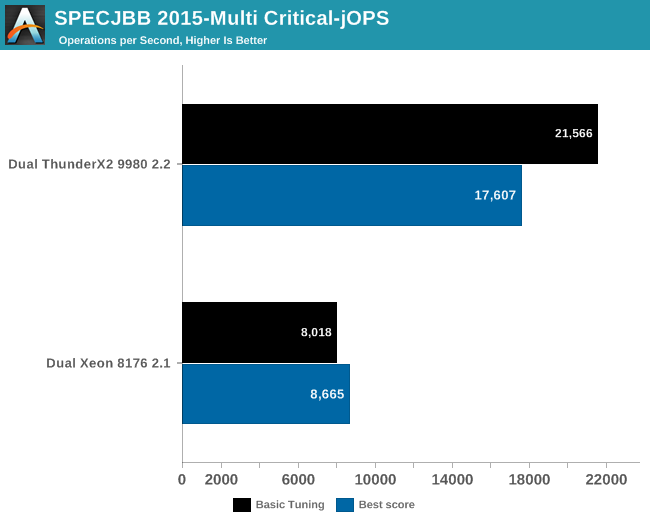
With this many threads active, you can get much higher Critical-jOPS by significantly increasing the RAM allocation per JVM. However, it really surprising to see that the Dual ThunderX2 system – with its higher thread count and lower clockspeed – has a much easier time delivering high throughputs while still keeping the 99th percentile response time under a certain limit.
Increasing the heap size helps Intel to close the gap somewhat (up to x2), but at the expense of the throughput numbers (-20% to -25%). So it seems that the Intel chip needs more tuning than the ARM one. To investigate this further, we turned to "Transparant Huge Pages" (THP).








97 Comments
View All Comments
name99 - Thursday, May 24, 2018 - link
For crying out loud!At the very least, if you want to pursue this obsession regarding vectors, look at ARM's SVE (Scalable Vector Extensions). THAT is where ARM is headed in the vector space.
Fujitsu is implementing these for the cores of its next HPC machines, and they will likely roll out into other ARM cores (maybe Apple first? but who can be sure?) over the next few years.
To the extent that Cavium has any interest in competing in HPC, if/when they choose to do so it will be on the basis of an SVE implementation, not on the basis of NEON.
Meanwhile ARMv8 NEON is very much the equivalent of SSE. Not AVX, no, but SSE (in all its versions) yes.
tuxRoller - Thursday, May 24, 2018 - link
Nice comment.BTW, centriq (rip) only supports(ed) aarch64. I've no idea how much die space that saved, though.
Wilco1 - Thursday, May 24, 2018 - link
There is Cortex-A35, smallest AArch64 core so far with FP and Neon.However there are still big differences between RISC and CISC. For example it's not feasible for CISC to get anywhere near the same size/perf/power. The mobile Atom debacle has clearly shown it's not feasible to match small and efficient RISCs even with a better process and many billions of dollars...
peevee - Thursday, May 24, 2018 - link
It is not 8.2.lmcd - Wednesday, January 23, 2019 - link
Necro but worth for historic reasons: A35 is AArch32 but ARMv8ZolaIII - Thursday, May 24, 2018 - link
It would took them a same. AVX is a SIMD FP extension to the prime architectural instruction set same as NEON and cetera. The strict difference between CISC and RISC architecture is long gone and today's one's are combined & further more implement IVIL SIMDs and more & more of DSP components as MAC's. The train only starts on prime integer instruction set (where by the way ARM is stellar) and then switches it's worker's to FP extensions and accelerated blocks of different kinds. The same way lintel grow up AVX to 512 bit in current use NEON can be scaled up & beyond. Fuitsu worked with ARM on 1024 & 2048 NEON SIMD blocks couple of years ago. Still if you think how FP is a best way to do it you are wrong, DSP's use CP and it's much more efficient power & performance wise but less scalable.On what would you like server's to be compared? Almost 90% of enterprise servers run on Linux, even Microsoft is earning more money this day's on Linux than from selling Windows desktop & server's combined.
You are very ignorant person. Why do you coment about the things you don't know anything about?
Ryan Smith - Thursday, May 24, 2018 - link
"I really think Anandtech needs to branch into different websites. Its very strange and unappealing to certain users to have business/consumer/random reviews/phone info all bunched together."Although I appreciate the feedback, I must admit that we enjoy doing a variety of things. There are a lot of cool things happening in the technology world, not all of which are in the consumer space. So rare articles like these - and we only publish a few a year - let us keep tabs on what's going on in some of those other markets.
HStewart - Wednesday, May 23, 2018 - link
I would think that a lot of this depends what type of applications are running on server. Highly mathematical and especially any with Vectors will be likely different. Also there is no support for Windows based servers which limits which applications can be done - so my guess this will be useless if desiring a VMWave server.But it is interesting that it takes a 4SMT to compete with x86 based servers from Intel and AMD and with more cores 32 vs 22/28 depending on version.
Wilco1 - Wednesday, May 23, 2018 - link
You're right, on floating point and vectors the results are different. To be precise - even more impressive. See the last page for example where it soundly beats Skylake on OpenFoam and a few other HPC benchmarks. Hence the huge interest from all the HPC companies.Note Windows has been running on Arm for quite some time. Microsoft runs Windows Server both on Centriq and ThunderX2. See eg. https://www.youtube.com/watch?v=uF1B5FfFLSA for more info.
HStewart - Wednesday, May 23, 2018 - link
Windows on ARM is DOA,