Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
What We Can Conclude: So Far
Wrapping things up, our SPECInt analyses show that the ThunderX2 cores still has some weaknesses. Our first impression is that branch intensive code – especially in combination with regular L3-cache misses (high DRAM latency) – run quite a bit slower. So there will be corner cases where the ThunderX2 is not the best choice.
However, other than some niche markets, we are pretty confident that the ThunderX2 will be a solid performer. For example, the performance measurements done by our colleagues at the University of Bristol confirm our suspicion that memory intensive HPC workloads such as OpenFoam (CFD) and NAMD.run really well on the ThunderX2
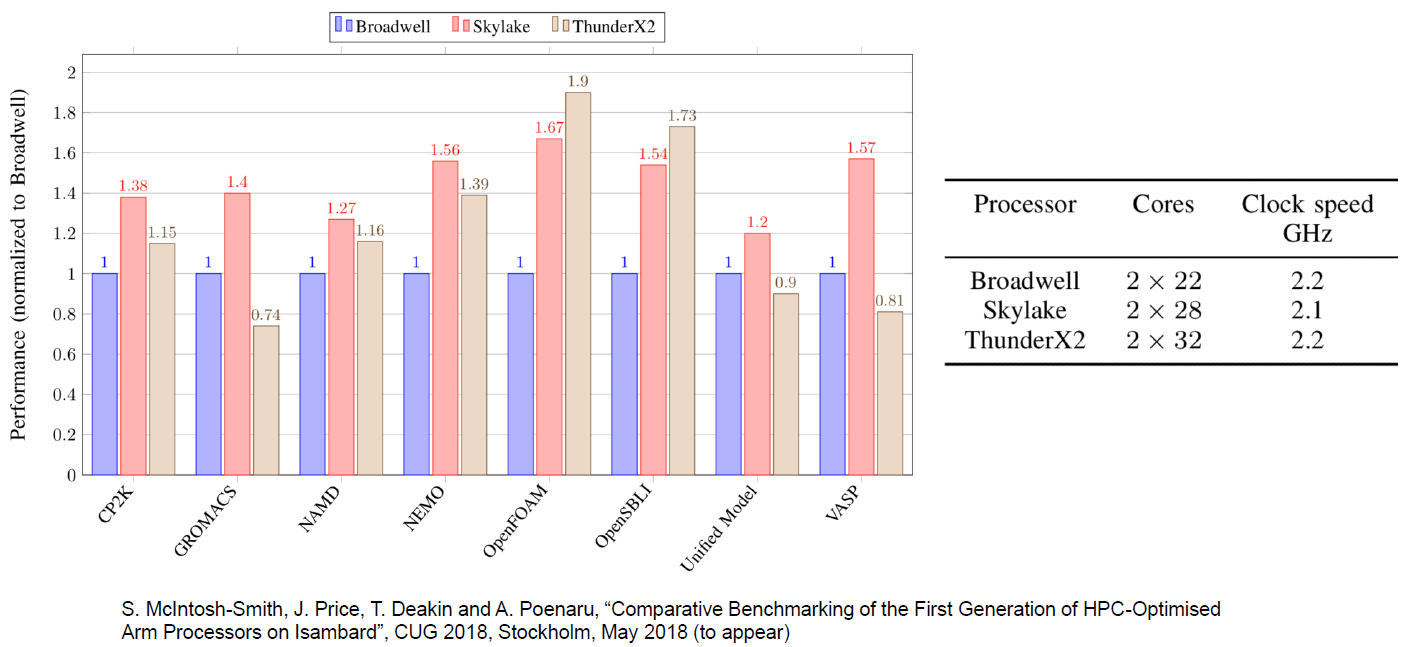
From the early server software testing we have done so far, we can only be pleasantly surprised. The performance-per-dollar of the ThunderX2 in both Java Server (SPECJbb) and Big Data processing is – right now – by far the best in the server market. We have to retest AMD's EPYC server CPU and a Gold version of the current generation (Skylake) Xeon to be absolutely sure, but delivering 80-90% of the performance of the 8176 at one fourth of the cost is going to very hard to beat.

As an added benefit to Cavium and the ThunderX2, here in 2018 the Arm Linux ecosystem is now mature; specialized Linux kernels and other tools are no longer necessary. You just install Ubuntu Server, Red Hat, or Suse, and you can automate your deployments and software installation from the standard repositories. That is a massive improvement compared to what we experienced back when the ThunderX was launched. Back in 2016, simply installing from the regular Ubuntu repositories could cause problems.
So all in all, the ThunderX2 is a very potent contender. It might even be more dangerous to AMD's EPYC than to Intel's Skylake Xeon thanks to the fact that both Cavium and AMD are competing for much of the same pool of customers considering switching away from Intel. This is because the customers who have invested in expensive enterprise software (Oracle, SAP) are less sensitive to cost on the hardware side, so they are much less likely to change to a new hardware platform. And those people have been investing the past 5 years in Intel as it was the only option.
That in turn means that those who are more agile and cost sensitive, such as hosting and cloud providers, will now be able to choose an Arm server CPU alternative with an excellent performance-per-dollar ratio. And with HP, Cray, Pengiun computing, Gigabyte, Foxconn, and Inventec all offering systems based upon the ThunderX2, there isn't a shortage of quality vendors.
In short, the ThunderX2 is the first SoC that is able to compete with Intel and AMD in the general purpose server CPU market. And that is a pleasant surprise: at last, an Arm server solution that delivers!








97 Comments
View All Comments
name99 - Thursday, May 24, 2018 - link
For crying out loud!At the very least, if you want to pursue this obsession regarding vectors, look at ARM's SVE (Scalable Vector Extensions). THAT is where ARM is headed in the vector space.
Fujitsu is implementing these for the cores of its next HPC machines, and they will likely roll out into other ARM cores (maybe Apple first? but who can be sure?) over the next few years.
To the extent that Cavium has any interest in competing in HPC, if/when they choose to do so it will be on the basis of an SVE implementation, not on the basis of NEON.
Meanwhile ARMv8 NEON is very much the equivalent of SSE. Not AVX, no, but SSE (in all its versions) yes.
tuxRoller - Thursday, May 24, 2018 - link
Nice comment.BTW, centriq (rip) only supports(ed) aarch64. I've no idea how much die space that saved, though.
Wilco1 - Thursday, May 24, 2018 - link
There is Cortex-A35, smallest AArch64 core so far with FP and Neon.However there are still big differences between RISC and CISC. For example it's not feasible for CISC to get anywhere near the same size/perf/power. The mobile Atom debacle has clearly shown it's not feasible to match small and efficient RISCs even with a better process and many billions of dollars...
peevee - Thursday, May 24, 2018 - link
It is not 8.2.lmcd - Wednesday, January 23, 2019 - link
Necro but worth for historic reasons: A35 is AArch32 but ARMv8ZolaIII - Thursday, May 24, 2018 - link
It would took them a same. AVX is a SIMD FP extension to the prime architectural instruction set same as NEON and cetera. The strict difference between CISC and RISC architecture is long gone and today's one's are combined & further more implement IVIL SIMDs and more & more of DSP components as MAC's. The train only starts on prime integer instruction set (where by the way ARM is stellar) and then switches it's worker's to FP extensions and accelerated blocks of different kinds. The same way lintel grow up AVX to 512 bit in current use NEON can be scaled up & beyond. Fuitsu worked with ARM on 1024 & 2048 NEON SIMD blocks couple of years ago. Still if you think how FP is a best way to do it you are wrong, DSP's use CP and it's much more efficient power & performance wise but less scalable.On what would you like server's to be compared? Almost 90% of enterprise servers run on Linux, even Microsoft is earning more money this day's on Linux than from selling Windows desktop & server's combined.
You are very ignorant person. Why do you coment about the things you don't know anything about?
Ryan Smith - Thursday, May 24, 2018 - link
"I really think Anandtech needs to branch into different websites. Its very strange and unappealing to certain users to have business/consumer/random reviews/phone info all bunched together."Although I appreciate the feedback, I must admit that we enjoy doing a variety of things. There are a lot of cool things happening in the technology world, not all of which are in the consumer space. So rare articles like these - and we only publish a few a year - let us keep tabs on what's going on in some of those other markets.
HStewart - Wednesday, May 23, 2018 - link
I would think that a lot of this depends what type of applications are running on server. Highly mathematical and especially any with Vectors will be likely different. Also there is no support for Windows based servers which limits which applications can be done - so my guess this will be useless if desiring a VMWave server.But it is interesting that it takes a 4SMT to compete with x86 based servers from Intel and AMD and with more cores 32 vs 22/28 depending on version.
Wilco1 - Wednesday, May 23, 2018 - link
You're right, on floating point and vectors the results are different. To be precise - even more impressive. See the last page for example where it soundly beats Skylake on OpenFoam and a few other HPC benchmarks. Hence the huge interest from all the HPC companies.Note Windows has been running on Arm for quite some time. Microsoft runs Windows Server both on Centriq and ThunderX2. See eg. https://www.youtube.com/watch?v=uF1B5FfFLSA for more info.
HStewart - Wednesday, May 23, 2018 - link
Windows on ARM is DOA,