Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
ThunderX: From Small & Simple to Wide & Complex
As a brief recap, the original ThunderX was an improved version of the Octeon III: a dual-issue in-order CPU core with two short pipelines.
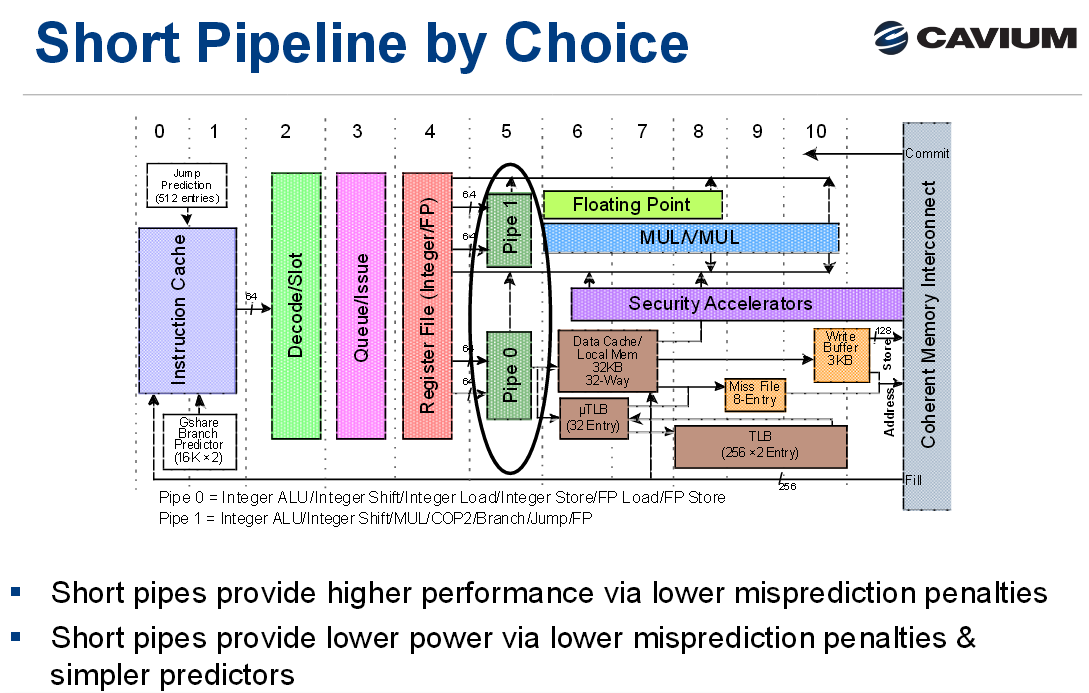
The advantage of the original ThunderX design is that such a simple core can be very energy efficient, especially for "low ILP" (instruction level parallelism) workloads such as web servers and most database servers. Of course, such a short pipeline limits the clockspeed, and such a simple in-order design offers low single threaded performance in medium and high ILP workloads, whereas more advanced out-of-order processors can extract significant parallelism.
Cavium's "New" Core: Vulcan
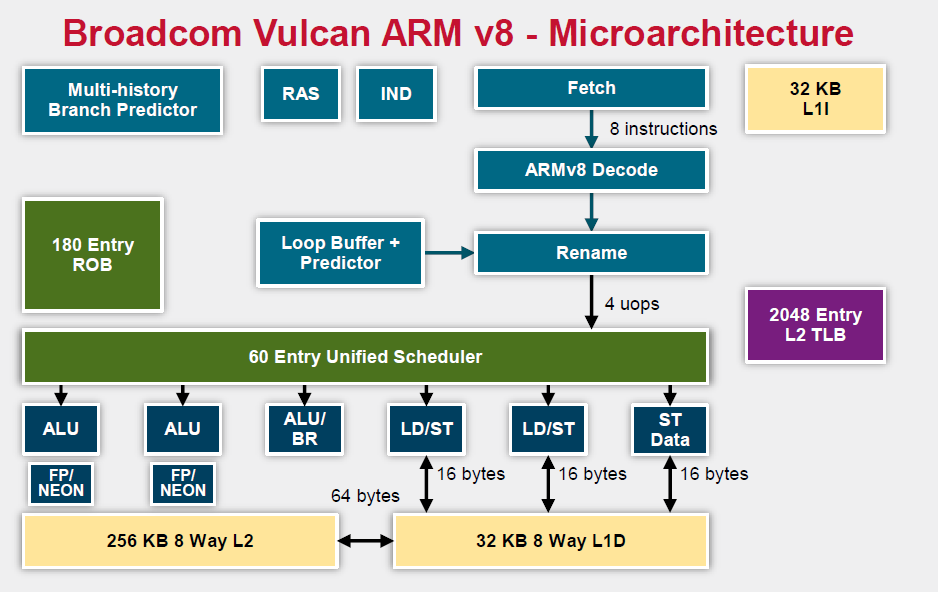
Relative to the original ThunderX, the Vulcan core of the ThunderX2 is an entirely different beast. Announced in 2014 by Broadcom, it is a relatively wide core that runs 4 simultaneous threads (SMT4). As a result, the wide back end should be quite busy even when running low-ILP server workloads.
To make sure that all 4 SMT threads can be sustained, the ThunderX2 front-end can fetch up to 64 bytes from the 8-way set associative 32 KB instruction cache, which is outfitted with a simple next line prefetcher. However, fetching 8 instructions is only possible if there is no taken branch inside those 64 bytes. In that case, the fetch breaks off at the taken branch.
That means that in branch intensive code (databases, AI...) the fetcher will get +/- 5 instructions per clock cycle on average, as one out of 5 instructions is a branch. The fetched instructions are then sent to a smoothing buffer – a buffer where the fetched instructions are held for decoding.
The decoder will then work on a bundle of 4 instructions. Between the decoder and the rename phase each thread has "skid buffer" which consists of 8 bundles. So between the 4 threads up to 32 bundles (128 instructions) can be skid buffered at any one time..
Those 4 instructions – a bundle – travel together through the pipeline until they reach the unified issue queue of the scheduler. Just like Intel has implemented in Nehalem, there is also a loop buffer and predictor, which Intel used to call a "Loop Stream Detector". This loop buffer avoids branch mispredictions and contains decoded µops, which "shortens" the pipeline and reduces the amount of power spent on decoding.
Overall, up to 6 instructions can be executed at the same time. This is divided into 2 ALU/FP/NEON slots, 1 ALU/branch slot, 2 load/store slots (16 bytes), and 1 pure store slot that sends 16 bytes to the D-cache. There is a small (Cavium would not disclose how small) L1 TLB for zero latency translation from Virtual to physical addresses. There is no hardware prefetcher for the L1 D-cache, but the L2 cache has a rather complex hardware prefetcher which is able to recognize patterns (besides being able to stride or fetching the next line).
This is enough to feed the back-end, which can sustain 4 instructions per cycle from 4 different threads.
Micro Architecture Differences
Ultimately Cavium has only published a limited amount of information on the ThunderX2 cores, so there are some limits to our knowledge. But we've gone ahead and summarized some of the key specifications of the different CPU architectures below.
| Feature | Cavium ThunderX2 |
Qualcomm Centriq "Falkor" |
Intel "Skylake"-SP |
AMD EPYC "Zen" |
| L1-I cache Associativity |
32 KB 8-way |
64KB 8-way (+ 24 KB L0) |
32 KB 8-way |
64KB 4-way |
| L1-D cache Associativity |
32 KB 8-way |
32 KB 8-way* |
32 KB 8-way |
32 KB 8-way |
| Load Bandwith | 2x 16B | 2x 16B | 2x 32B | 2x 16B |
| L2-cache | 256 KB 8-way |
256 KB 8-way |
1 MB 16-way |
512 KB 8-way |
| Fetch Width | 8 instructions | 4 instructions | 16 bytes (+/- 4-5 x86) | 32 bytes (+/- 6-8 x86) |
| Issue Queue | 60 | 76 | 97 unified | 6x14 |
| Sustainable Instructions/cycle | 4 | 4 | 5-6 | 4-5 |
| Instructions in Flight | 180 (ROB) | 128 | 224 (ROB) | 192 |
| Int. Pipeline Length |
? |
15 stages | 19 stages 14 stage from µop cache |
19 stages? |
| TLB Instructions TLB Data |
"Small L1" + 2048 unified L2 | ? 64+512 |
128 64 +1536 Unified |
8+64+512 64+1532 |
A detailed analysis is out of the scope of this article. But you can read Ian's analyses of the Falkor, Skylake and Zen architectures here at AnandTech. We limit ourselves to the most obvious differences.
It is pretty clear that Intel's single-threaded performance remains unchallenged: the Skylake core is the widest core, keeps the most instructions in flight, and most importantly runs at the highest clockspeed. The ThunderX2 core is the one that fetches the most instructions per cycle, as it has to be able to keep 4 threads running. The fetch unit will grab 8 instructions from one thread, than grab 8 from the second thread and it will keep cycling between threads. A bad prediction could thus lower the performance of single thread significantly.








97 Comments
View All Comments
Eris_Floralia - Wednesday, May 23, 2018 - link
The L2$ for SKX should be 1MB (256+768KiB), 16-way.Ryan Smith - Wednesday, May 23, 2018 - link
Right you are. Thanks!danjme - Wednesday, May 23, 2018 - link
Mental.Duncan Macdonald - Wednesday, May 23, 2018 - link
The CPU may be much cheaper than the equivalent Intel CPU - however on the price of a complete server there would be almost no difference as the vast majority of the price of a server is in other items (RAM, storage, network, software etc). To take a significant share, the performance needs to be better than Intel CPUs on both a per thread and a per socket basis. Potential users will look at this CPU - see that it is not faster than Intel on a per thread basis and is also not X86-64 compatible and turn away with a shrug. A price difference of under 5% for a complete server is not enough to justify the risks of going from x86-64 to ARM.BurntMyBacon - Thursday, May 24, 2018 - link
Perhaps you are correct and the lack of per thread performance will not allow Cavium to take a "significant' share of the market from Intel. However, at this point, getting even a small amount of market penetration in the server market is a significant achievement for an ARM vendor. This processor doesn't need to take a "significant" share from Intel to be successful. It just needs to establish a solid foothold. Given the data, I think it has a good chance of succeeding in that.The bigger question in my mind is how Intel will respond. They already have the ability to make a many lite core accelerator as demonstrated by the Xeon Phi line. Will they bring this tech to their CPU lineup, create a new accelerator based on this tech to handle applications that use many light threads, create a new many small core CPU based on Goldmont Plus (or Tremont), or will they consider the ARM threat insignificant enough to ignore.
boeush - Wednesday, May 23, 2018 - link
"(*) EPYC and Xeon E5 V4 are older results, run on Kernel 4.8 and a slightly older Java 1.8.0_131 instead of 1.8.0_161. Though we expect that the results would be very similar on kernel 4.13 and Java 1.8.0_161"What about Spectre/Meltdown mitigation patches? Were they in effect for 'older' results?
boeush - Wednesday, May 23, 2018 - link
To elaborate: if those numbers really are from July 2017, then they don't reflect true performance in a server context any longer (servers are where Spectre/Meltdown patches would be applied most.). Since the performance impact of Spectre/Meltdown is greatest on speculative execution and memory loads/prefetching, I'd guess those super-aggressive memory subsystem performance numbers, as well as single thread IPC advantages that Intel's CPUs claim in your benchmarks, are not really entirely applicable any longer.HStewart - Wednesday, May 23, 2018 - link
Spectre has been proved to effect other CPU's than Intel and even effects ARM and AMD.,Image on this article states that this CPU supports Fully Out of Order execution. So with my understanding of Spectre that this CPU also has issues.
To be honest I not sure how much the whole Spectre/Meltdown stuff is in this real world. It probably cause more harm in the computer industry than help.
Manch - Thursday, May 24, 2018 - link
Commentor: Blah Blah Blah Spectre?HStewart: Shill Shill Shill must defend Intel by any means...
lmcd - Thursday, May 24, 2018 - link
Commentor: reasonable position takenManch: *banned for unreasonable, offensive comments*