Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Java Performance: Huge Pages Investigated
Since experience tells us that it is quite rare for one CPU to beat another in a benchmark by a factor 3, we investigated the matter further. The most obvious candidate was Huge Pages, or as everybody besides the Linux community calls it: "Large Pages".
Every modern CPU caches the virtual-to-physical memory mappings in their TLBs. The "normal" size of a page is 4 KB, so with 1536 entries, the Skylake core can only cache about 6 MB per core. Consequently, as DRAM capacity has grown the past 15 years from a few GB to hundreds of GBs, TLB misses have become more and more of a concern. A TLB miss is quite expensive – costing several memory accesses in total – as you need to read out several tables to finally find the physical address.
All modern CPU support larger pages. In the x86-64 (Intel & AMD) a 2 MB large page is the most popular option, while a 1 GB page is also available. Meanwhile a large page on the ThunderX2 is no less than 0.5 GB. Using large pages reduces the number of TLB misses (although the number of entries in the TLB is typically much lower for large pages), and also they reduce the number of memory accesses needed if a TLB miss occurs.
However, it took a while before Linux supported this feature in an easy to handle way. Memory fragmentation, conflicting and hard to configure settings, incompatibilities, and especially very confusing names caused a lot of trouble. In fact, many software vendors still advise server admins to disable large pages. So while it was quickly embraced for benchmarks, the software community as a whole is still hesitant.
To that end, let's see what happens if we enable Transparent Huge Pages and keep the best settings we discussed on the previous page.
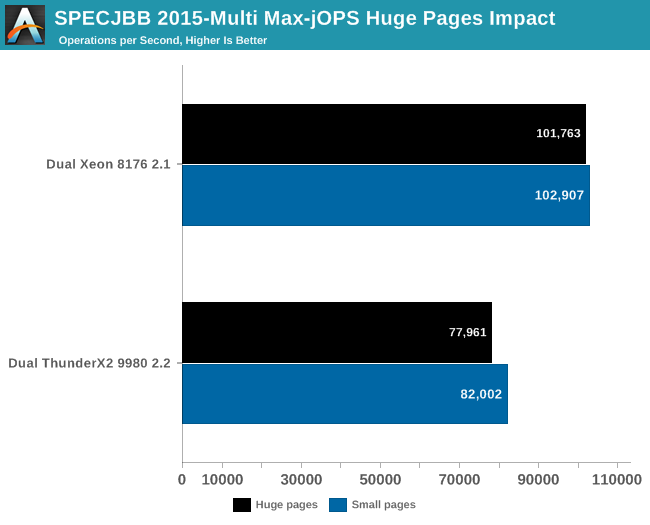
Overall, for Max-jOPs the performance impact is nothing spectaculair; in fact it's a slight regression. The Xeon loses about 1% of its throughput, the ThunderX2 about 5%.
Moving on, let's check out the Critical-jOPS metric, where throughput is measured with a 99 percentile response time constraint.
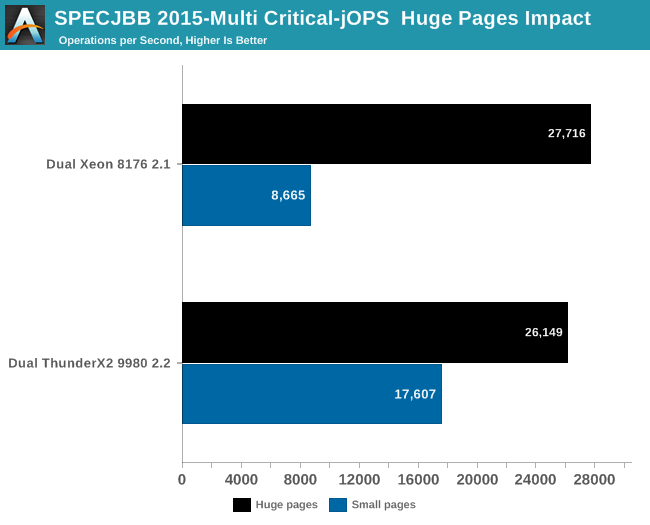
A massive difference! Instead of taking a massive beating, the Intel setup edges out the ThunderX2. Still, it must be said that performance with 4 KB pages seems to be a major weakness with Intel's architecture.








97 Comments
View All Comments
Eris_Floralia - Wednesday, May 23, 2018 - link
The L2$ for SKX should be 1MB (256+768KiB), 16-way.Ryan Smith - Wednesday, May 23, 2018 - link
Right you are. Thanks!danjme - Wednesday, May 23, 2018 - link
Mental.Duncan Macdonald - Wednesday, May 23, 2018 - link
The CPU may be much cheaper than the equivalent Intel CPU - however on the price of a complete server there would be almost no difference as the vast majority of the price of a server is in other items (RAM, storage, network, software etc). To take a significant share, the performance needs to be better than Intel CPUs on both a per thread and a per socket basis. Potential users will look at this CPU - see that it is not faster than Intel on a per thread basis and is also not X86-64 compatible and turn away with a shrug. A price difference of under 5% for a complete server is not enough to justify the risks of going from x86-64 to ARM.BurntMyBacon - Thursday, May 24, 2018 - link
Perhaps you are correct and the lack of per thread performance will not allow Cavium to take a "significant' share of the market from Intel. However, at this point, getting even a small amount of market penetration in the server market is a significant achievement for an ARM vendor. This processor doesn't need to take a "significant" share from Intel to be successful. It just needs to establish a solid foothold. Given the data, I think it has a good chance of succeeding in that.The bigger question in my mind is how Intel will respond. They already have the ability to make a many lite core accelerator as demonstrated by the Xeon Phi line. Will they bring this tech to their CPU lineup, create a new accelerator based on this tech to handle applications that use many light threads, create a new many small core CPU based on Goldmont Plus (or Tremont), or will they consider the ARM threat insignificant enough to ignore.
boeush - Wednesday, May 23, 2018 - link
"(*) EPYC and Xeon E5 V4 are older results, run on Kernel 4.8 and a slightly older Java 1.8.0_131 instead of 1.8.0_161. Though we expect that the results would be very similar on kernel 4.13 and Java 1.8.0_161"What about Spectre/Meltdown mitigation patches? Were they in effect for 'older' results?
boeush - Wednesday, May 23, 2018 - link
To elaborate: if those numbers really are from July 2017, then they don't reflect true performance in a server context any longer (servers are where Spectre/Meltdown patches would be applied most.). Since the performance impact of Spectre/Meltdown is greatest on speculative execution and memory loads/prefetching, I'd guess those super-aggressive memory subsystem performance numbers, as well as single thread IPC advantages that Intel's CPUs claim in your benchmarks, are not really entirely applicable any longer.HStewart - Wednesday, May 23, 2018 - link
Spectre has been proved to effect other CPU's than Intel and even effects ARM and AMD.,Image on this article states that this CPU supports Fully Out of Order execution. So with my understanding of Spectre that this CPU also has issues.
To be honest I not sure how much the whole Spectre/Meltdown stuff is in this real world. It probably cause more harm in the computer industry than help.
Manch - Thursday, May 24, 2018 - link
Commentor: Blah Blah Blah Spectre?HStewart: Shill Shill Shill must defend Intel by any means...
lmcd - Thursday, May 24, 2018 - link
Commentor: reasonable position takenManch: *banned for unreasonable, offensive comments*