Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Java Performance
The SPECjbb 2015 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
Note that we upgraded from SPECjbb version 1.0 to 1.01.
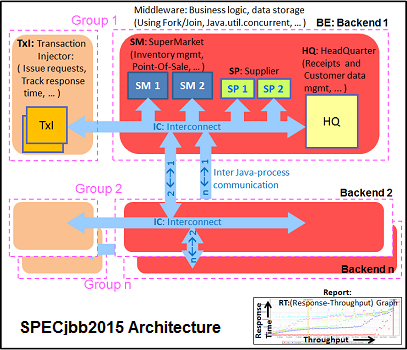
We tested SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice, especially on these 100+ threads servers. The Java version was OpenJDK 1.8.0_161.
Each time we publish SPECjbb numbers, several people tell us that our numbers are too low. So we decided to spend a bit more time and attention on the various settings.
However, it is important to understand that the SPECJbb numbers published by the hardware vendors are achieved with the following settings, which are hardly suitable for a production environment:
- Fiddling around with kernel settings like the timings of the task scheduler, page cache flushing
- Disabling energy saving features, manually setting c-state behavior
- Setting the fans at maximum speed, thus wasting a lot of energy for a few extra performance points
- Disabling RAS features (like memory scrub)
- Using a massive amount of Java tuning parameters. That is unrealistic because it means that every time an application is run on a different machine (which happens quite a bit in a cloud environment) expensive professionals have to revise these settings, which may potentially cause the application to halt on a different machine.
- Setting very SKU-specific NUMA settings and CPU bindings. Migrating between 2 different SKUs in the same cluster may cause serious performance problems.
We welcome constructive feedback, but in most production environments tuning should be simple and preferably not too machine-specific. To that end we applied two kinds of tuning. The first one is very basic tuning to measure "out of the box" performance, while aiming to fit everything inside a server with 128 GB of RAM:
For the second tuning, we went searching for the best throughput score, playing around with "-XX:+AlwaysPreTouch", "-XX:-UseBiasedLocking", and "specjbb.forkjoin.workers". "+AlwaysPretouch" zeroes out all of the memory pages before starting up, lowering the performance impact of touching new pages. "-UseBiasedLockin" disables biased locking, which is otherwise enabled by default. Biased locking gives the thread that already has loaded the contended data in the cache priority. The trade-off for using biased locking is some additional bookkeeping within the system, which in turn incurs a small performance hit overall if that strategy was not the right one.
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test.
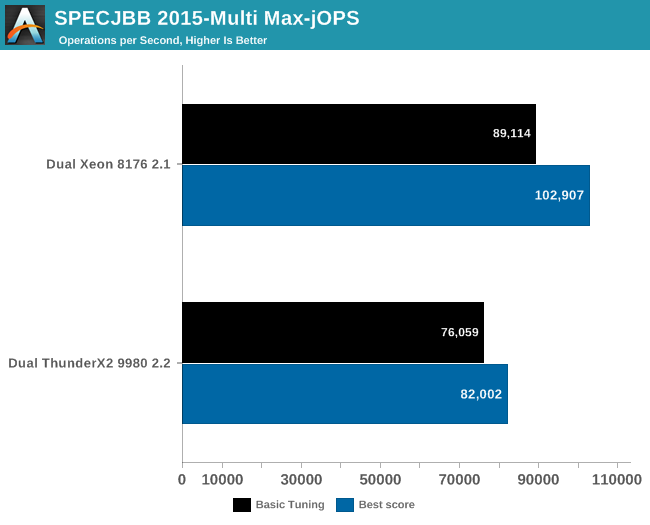
The ThunderX2 achieves 80& to 85% of the performance of the Xeon 8176. That should be high enough to beat the Xeon 6148. Interestingly, the top scores are achieved in different ways between the Intel and Cavium systems. In case of the Dual ThunderX2, we used:
Whereas the Intel system achieved best performance by leaving biased locking on (the default). We noticed that the Intel system – probably due to the relatively "odd" thread count – has a slightly lower average CPU load (a few percent) and a larger L3-cache, making biased locking a good strategy for the that architecture.
Finally, we have Critical-jOPS, which measures throughput under response time constraints.
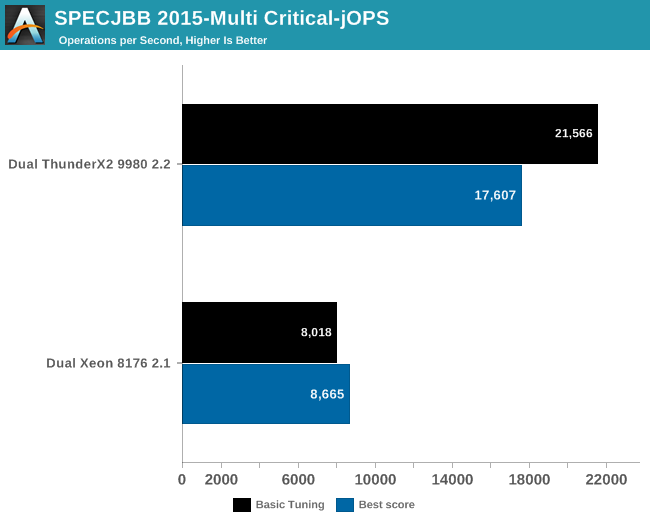
With this many threads active, you can get much higher Critical-jOPS by significantly increasing the RAM allocation per JVM. However, it really surprising to see that the Dual ThunderX2 system – with its higher thread count and lower clockspeed – has a much easier time delivering high throughputs while still keeping the 99th percentile response time under a certain limit.
Increasing the heap size helps Intel to close the gap somewhat (up to x2), but at the expense of the throughput numbers (-20% to -25%). So it seems that the Intel chip needs more tuning than the ARM one. To investigate this further, we turned to "Transparant Huge Pages" (THP).








97 Comments
View All Comments
Gunbuster - Wednesday, May 23, 2018 - link
Because it's hard to explain the critical line of business software or database is having some unknown edge case issue because you thought look at me I'm so smart and saved 1% of the project cost using unproven low penetration hardware.daanno2 - Wednesday, May 23, 2018 - link
I'm guessing you've never dealt with expensive enterprise software before. They are mostly licensed per-core, so getting the absolute best performance per core, even if the CPU is 2-3x more expensive, is worth it. At the end of the day, the CPUs might be <5% of the total cost.SirPerro - Wednesday, May 23, 2018 - link
You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try.If your hardware makes up for 5% of the cost, saving a 3% of the total budget is not worth the risk of migration.
FunBunny2 - Thursday, May 24, 2018 - link
"You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try."the EOL of today's machines, the amortization schedules must be draconian. only if a 'different' server pays off in dozens of months, not years, will it have chance. to the extent that enterprise software is a C/C++ and *nix codebase, porting won't be onerous. but, I'm willing to guess, even Oracle code isn't all that parallel, so throwing a truckload of teeny cpu at it won't necessarily work.
name99 - Thursday, May 24, 2018 - link
The bigger problem here is the massive uncertainty around the meaning of the word "server" and thus the target for these new ARM CPUs.Some people seem to think "server" means primarily boxes that run SAP or ORACLE, but I think it's clear that the ARM ecosystem has little interest in that, at least right now.
What's of much more interest is racks on racks of CPUs running commodity (LAMP) or homegrown software, ie data warehouses and HPC. I'm not even sure the Java benchmarks being run are of much interest to this market. The things that matter are the sorts of things Cloudflare was measuring when they tested Centriq -- memcached, nginx, transforming one type of data into another (compression/decompression, encrypt/decrypt, transcode,...) at massive throughput.
That's where I'd expect to see the big sales of the ARM "server" cores -- to Cloudflare, Baidu, Google, and so on.
Also now that Marvell is in the game, will be interesting to see the extent to which they pull this downward, into their traditional sorts of markets like infrastructure network and storage control (eg to go into network appliances and NAS boxes).
Ed469546 - Wednesday, June 13, 2018 - link
Some of the commercial software you pay per core. Intel had the best single threaded performance mening power license costs.Interesting question is how the Thunderx2 cores are counted in this case: one core can run 4 threads.
andrewaggb - Wednesday, May 23, 2018 - link
I wonder what workloads they are targeting? High throughput with poor single threaded results is somewhat limiting.peevee - Wednesday, May 23, 2018 - link
Web app servers. VM servers. Hadoop/Spark nodes. All benefit more from having more threads running in parallel instead of each request waiting or switching contexts.If you are concerned about single-thread performance on 256-thread server (as 2-CPU server with this CPU will provide) AT ALL, you choose outrageously wrong hardware for the task to begin with. Go buy a 2-core i3. Practically the only test in this article which matters is Critical jOPS (assuming the used quality of service metric was configured realistically).
GeekyMcGeekface - Friday, May 25, 2018 - link
I’m building a cluster now with a few hundred Raspberry Pi’s because scale up is expensive and stupid. By distributing across a pool of clusters, I can handle far more memory bandwidth and compute. Consider 100 Raspberry PIs have 400 64-bit cores and 100GB of RAM. Total cost $3500 + power, mounting and switches.Running three clusters of those with Kubernetes, Couchbase and Azure Functions provides 1200 64-bit cores, about 100GB of extremely high performance storage, incredible failover and a map-reduce environment to die for.
Add some 64GB MicroSD cards and an object storage system to the cluster and there’s 12TB of cold storage (4TB when made redundant).
Pay a service fee to some sweatshop in the Eastern Block to do the labor intensive bits and you can build a massively parallel, almost impossible to crash, CI/CD friendly, multi-tenant, infinitely scalable PaaS... for less than the cost of the RAM for a single one of the servers here.
The only expensive bits in the design are the Netscalers.
Oh... and the power foot print is about the same as one of these servers.
I honestly have no idea what I what I would use a server like these in a new design for.
jospoortvliet - Wednesday, May 30, 2018 - link
single-core performance with your pi's is considerably lower, as is inter-core bandwidth. If your tasks require little inter-process communication you're good but with highly interdependent compute it won't perform well. But for specific tasks, yes, it might be very cost effective.