Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Java Performance: Huge Pages Investigated
Since experience tells us that it is quite rare for one CPU to beat another in a benchmark by a factor 3, we investigated the matter further. The most obvious candidate was Huge Pages, or as everybody besides the Linux community calls it: "Large Pages".
Every modern CPU caches the virtual-to-physical memory mappings in their TLBs. The "normal" size of a page is 4 KB, so with 1536 entries, the Skylake core can only cache about 6 MB per core. Consequently, as DRAM capacity has grown the past 15 years from a few GB to hundreds of GBs, TLB misses have become more and more of a concern. A TLB miss is quite expensive – costing several memory accesses in total – as you need to read out several tables to finally find the physical address.
All modern CPU support larger pages. In the x86-64 (Intel & AMD) a 2 MB large page is the most popular option, while a 1 GB page is also available. Meanwhile a large page on the ThunderX2 is no less than 0.5 GB. Using large pages reduces the number of TLB misses (although the number of entries in the TLB is typically much lower for large pages), and also they reduce the number of memory accesses needed if a TLB miss occurs.
However, it took a while before Linux supported this feature in an easy to handle way. Memory fragmentation, conflicting and hard to configure settings, incompatibilities, and especially very confusing names caused a lot of trouble. In fact, many software vendors still advise server admins to disable large pages. So while it was quickly embraced for benchmarks, the software community as a whole is still hesitant.
To that end, let's see what happens if we enable Transparent Huge Pages and keep the best settings we discussed on the previous page.
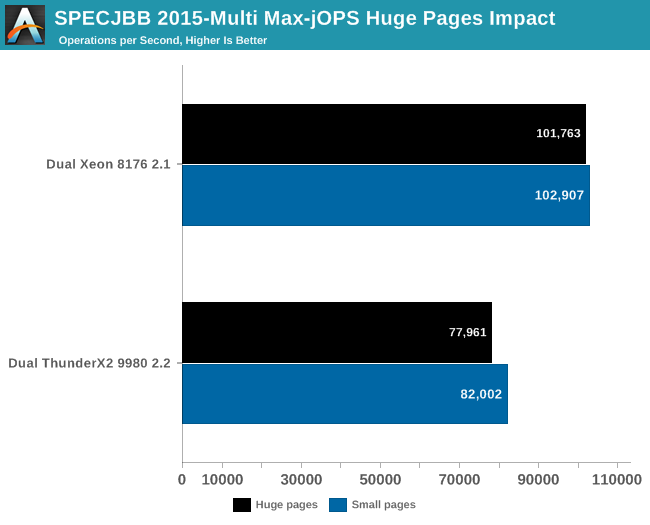
Overall, for Max-jOPs the performance impact is nothing spectaculair; in fact it's a slight regression. The Xeon loses about 1% of its throughput, the ThunderX2 about 5%.
Moving on, let's check out the Critical-jOPS metric, where throughput is measured with a 99 percentile response time constraint.
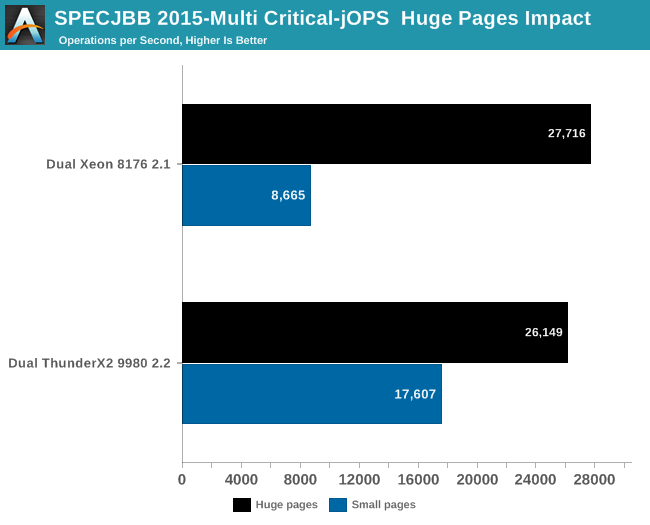
A massive difference! Instead of taking a massive beating, the Intel setup edges out the ThunderX2. Still, it must be said that performance with 4 KB pages seems to be a major weakness with Intel's architecture.








97 Comments
View All Comments
Gunbuster - Wednesday, May 23, 2018 - link
Because it's hard to explain the critical line of business software or database is having some unknown edge case issue because you thought look at me I'm so smart and saved 1% of the project cost using unproven low penetration hardware.daanno2 - Wednesday, May 23, 2018 - link
I'm guessing you've never dealt with expensive enterprise software before. They are mostly licensed per-core, so getting the absolute best performance per core, even if the CPU is 2-3x more expensive, is worth it. At the end of the day, the CPUs might be <5% of the total cost.SirPerro - Wednesday, May 23, 2018 - link
You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try.If your hardware makes up for 5% of the cost, saving a 3% of the total budget is not worth the risk of migration.
FunBunny2 - Thursday, May 24, 2018 - link
"You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try."the EOL of today's machines, the amortization schedules must be draconian. only if a 'different' server pays off in dozens of months, not years, will it have chance. to the extent that enterprise software is a C/C++ and *nix codebase, porting won't be onerous. but, I'm willing to guess, even Oracle code isn't all that parallel, so throwing a truckload of teeny cpu at it won't necessarily work.
name99 - Thursday, May 24, 2018 - link
The bigger problem here is the massive uncertainty around the meaning of the word "server" and thus the target for these new ARM CPUs.Some people seem to think "server" means primarily boxes that run SAP or ORACLE, but I think it's clear that the ARM ecosystem has little interest in that, at least right now.
What's of much more interest is racks on racks of CPUs running commodity (LAMP) or homegrown software, ie data warehouses and HPC. I'm not even sure the Java benchmarks being run are of much interest to this market. The things that matter are the sorts of things Cloudflare was measuring when they tested Centriq -- memcached, nginx, transforming one type of data into another (compression/decompression, encrypt/decrypt, transcode,...) at massive throughput.
That's where I'd expect to see the big sales of the ARM "server" cores -- to Cloudflare, Baidu, Google, and so on.
Also now that Marvell is in the game, will be interesting to see the extent to which they pull this downward, into their traditional sorts of markets like infrastructure network and storage control (eg to go into network appliances and NAS boxes).
Ed469546 - Wednesday, June 13, 2018 - link
Some of the commercial software you pay per core. Intel had the best single threaded performance mening power license costs.Interesting question is how the Thunderx2 cores are counted in this case: one core can run 4 threads.
andrewaggb - Wednesday, May 23, 2018 - link
I wonder what workloads they are targeting? High throughput with poor single threaded results is somewhat limiting.peevee - Wednesday, May 23, 2018 - link
Web app servers. VM servers. Hadoop/Spark nodes. All benefit more from having more threads running in parallel instead of each request waiting or switching contexts.If you are concerned about single-thread performance on 256-thread server (as 2-CPU server with this CPU will provide) AT ALL, you choose outrageously wrong hardware for the task to begin with. Go buy a 2-core i3. Practically the only test in this article which matters is Critical jOPS (assuming the used quality of service metric was configured realistically).
GeekyMcGeekface - Friday, May 25, 2018 - link
I’m building a cluster now with a few hundred Raspberry Pi’s because scale up is expensive and stupid. By distributing across a pool of clusters, I can handle far more memory bandwidth and compute. Consider 100 Raspberry PIs have 400 64-bit cores and 100GB of RAM. Total cost $3500 + power, mounting and switches.Running three clusters of those with Kubernetes, Couchbase and Azure Functions provides 1200 64-bit cores, about 100GB of extremely high performance storage, incredible failover and a map-reduce environment to die for.
Add some 64GB MicroSD cards and an object storage system to the cluster and there’s 12TB of cold storage (4TB when made redundant).
Pay a service fee to some sweatshop in the Eastern Block to do the labor intensive bits and you can build a massively parallel, almost impossible to crash, CI/CD friendly, multi-tenant, infinitely scalable PaaS... for less than the cost of the RAM for a single one of the servers here.
The only expensive bits in the design are the Netscalers.
Oh... and the power foot print is about the same as one of these servers.
I honestly have no idea what I what I would use a server like these in a new design for.
jospoortvliet - Wednesday, May 30, 2018 - link
single-core performance with your pi's is considerably lower, as is inter-core bandwidth. If your tasks require little inter-process communication you're good but with highly interdependent compute it won't perform well. But for specific tasks, yes, it might be very cost effective.