Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Java Performance
The SPECjbb 2015 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
Note that we upgraded from SPECjbb version 1.0 to 1.01.
We tested SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice, especially on these 100+ threads servers. The Java version was OpenJDK 1.8.0_161.
Each time we publish SPECjbb numbers, several people tell us that our numbers are too low. So we decided to spend a bit more time and attention on the various settings.
However, it is important to understand that the SPECJbb numbers published by the hardware vendors are achieved with the following settings, which are hardly suitable for a production environment:
- Fiddling around with kernel settings like the timings of the task scheduler, page cache flushing
- Disabling energy saving features, manually setting c-state behavior
- Setting the fans at maximum speed, thus wasting a lot of energy for a few extra performance points
- Disabling RAS features (like memory scrub)
- Using a massive amount of Java tuning parameters. That is unrealistic because it means that every time an application is run on a different machine (which happens quite a bit in a cloud environment) expensive professionals have to revise these settings, which may potentially cause the application to halt on a different machine.
- Setting very SKU-specific NUMA settings and CPU bindings. Migrating between 2 different SKUs in the same cluster may cause serious performance problems.
We welcome constructive feedback, but in most production environments tuning should be simple and preferably not too machine-specific. To that end we applied two kinds of tuning. The first one is very basic tuning to measure "out of the box" performance, while aiming to fit everything inside a server with 128 GB of RAM:
For the second tuning, we went searching for the best throughput score, playing around with "-XX:+AlwaysPreTouch", "-XX:-UseBiasedLocking", and "specjbb.forkjoin.workers". "+AlwaysPretouch" zeroes out all of the memory pages before starting up, lowering the performance impact of touching new pages. "-UseBiasedLockin" disables biased locking, which is otherwise enabled by default. Biased locking gives the thread that already has loaded the contended data in the cache priority. The trade-off for using biased locking is some additional bookkeeping within the system, which in turn incurs a small performance hit overall if that strategy was not the right one.
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test.
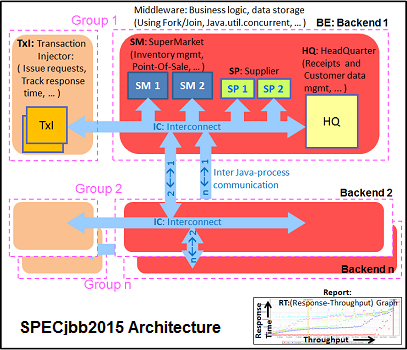
The ThunderX2 achieves 80& to 85% of the performance of the Xeon 8176. That should be high enough to beat the Xeon 6148. Interestingly, the top scores are achieved in different ways between the Intel and Cavium systems. In case of the Dual ThunderX2, we used:
Whereas the Intel system achieved best performance by leaving biased locking on (the default). We noticed that the Intel system – probably due to the relatively "odd" thread count – has a slightly lower average CPU load (a few percent) and a larger L3-cache, making biased locking a good strategy for the that architecture.
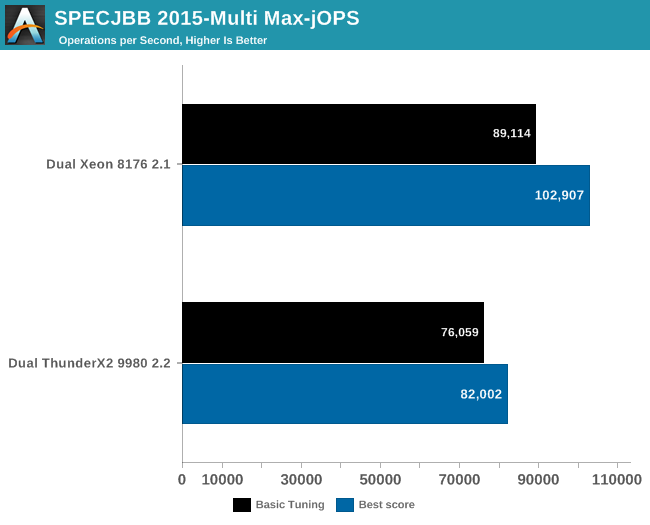
Finally, we have Critical-jOPS, which measures throughput under response time constraints.
With this many threads active, you can get much higher Critical-jOPS by significantly increasing the RAM allocation per JVM. However, it really surprising to see that the Dual ThunderX2 system – with its higher thread count and lower clockspeed – has a much easier time delivering high throughputs while still keeping the 99th percentile response time under a certain limit.
Increasing the heap size helps Intel to close the gap somewhat (up to x2), but at the expense of the throughput numbers (-20% to -25%). So it seems that the Intel chip needs more tuning than the ARM one. To investigate this further, we turned to "Transparant Huge Pages" (THP).








97 Comments
View All Comments
JohanAnandtech - Thursday, May 24, 2018 - link
I have been trouble shooting a Java problem for the last 3 weeks now - for some reason our specific EPYC test system has some serious performance issues after we upgraded to kernel 4.13. This might be a hardware/firmware... issue. I don't know. I just know that the current tests are not accurate.junky77 - Thursday, May 24, 2018 - link
What? A 2.5GHZ ARM core is around 60-70% of a 3.8GHZ Skylake core?? For 3.8GHZ, the ARM is probably at least as fast?Wilco1 - Thursday, May 24, 2018 - link
Probably around 90% since performance doesn't scale linearly with frequency. Note these are throughput parts so won't clock that high. However a 7nm version might well reach 3GHz.AJ_NEWMAN - Thursday, May 24, 2018 - link
If Caviums tweaked 16nm hits 3GHz - it would to be unreasonable to aim for 4GHz for a 7nm part.With 2.3 times as many transistors available - it will be interesting to see what else they beef up?
HIgher IPC? 64 cores? 16 memory controllers? CCIX - or perhaps they will compete with Fujitsu and add some Supercomputer centric hardware?
AJ
meta.x.gdb - Thursday, May 31, 2018 - link
Wonder why the VASP code limped along on ThunderX2 while OpenFOAM saw such gains. I'm pretty familiar with both codes. VASP is mostly doing density functional theory, which is FFT-heavy...Meteor2 - Tuesday, June 26, 2018 - link
All I want to say (all I can say) is that Anandtech has some of the best writers and commenters in this field. Fantastic article, and fantastic discussion.paldU - Saturday, July 7, 2018 - link
A typo in Page 2. "it terms of performance per dollar" should be " in terms of performance per dollar".