Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Apache Spark 2.x Benchmarking
Last, but not least, we have Apache Spark. Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
To get better scaling, we run with 4 executors. Researcher Esli Heyvaert reconfigured the Spark benchmark so it could run on Apache Spark 2.1.1.
Here are the results:
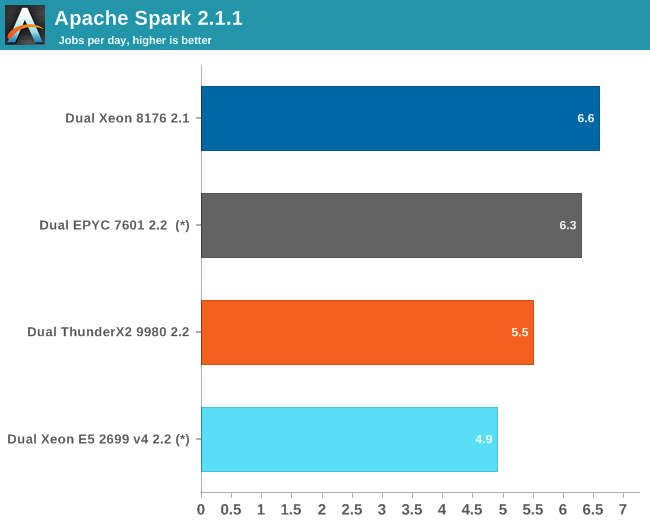
(*) EPYC and Xeon E5 V4 are older results, run on Kernel 4.8 and a slightly older Java 1.8.0_131 instead of 1.8.0_161. Though we expect that the results would be very similar on kernel 4.13 and Java 1.8.0_161, as we did not see much difference on the Skylake Xeon between those two setups.
Data processing is very parallel and extremely CPU intensive, but the shuffle phases require a lot of memory interactions. The time spent on storage I/O is negligible. The ALS phase does not scale well over many threads, but is less than 4% of the total testing time.
The ThunderX2 delivers 87% of the performance of the twice as expensive EPYC 7601. Since this benchmark scales well with the number of cores, we can estimate that the Xeon 6148 will score around 4.8. So while the ThunderX2 can not really threaten the Xeon Platinum 8176, it gives the Gold 6148 and its ilk a run for their money.








97 Comments
View All Comments
JohanAnandtech - Thursday, May 24, 2018 - link
I have been trouble shooting a Java problem for the last 3 weeks now - for some reason our specific EPYC test system has some serious performance issues after we upgraded to kernel 4.13. This might be a hardware/firmware... issue. I don't know. I just know that the current tests are not accurate.junky77 - Thursday, May 24, 2018 - link
What? A 2.5GHZ ARM core is around 60-70% of a 3.8GHZ Skylake core?? For 3.8GHZ, the ARM is probably at least as fast?Wilco1 - Thursday, May 24, 2018 - link
Probably around 90% since performance doesn't scale linearly with frequency. Note these are throughput parts so won't clock that high. However a 7nm version might well reach 3GHz.AJ_NEWMAN - Thursday, May 24, 2018 - link
If Caviums tweaked 16nm hits 3GHz - it would to be unreasonable to aim for 4GHz for a 7nm part.With 2.3 times as many transistors available - it will be interesting to see what else they beef up?
HIgher IPC? 64 cores? 16 memory controllers? CCIX - or perhaps they will compete with Fujitsu and add some Supercomputer centric hardware?
AJ
meta.x.gdb - Thursday, May 31, 2018 - link
Wonder why the VASP code limped along on ThunderX2 while OpenFOAM saw such gains. I'm pretty familiar with both codes. VASP is mostly doing density functional theory, which is FFT-heavy...Meteor2 - Tuesday, June 26, 2018 - link
All I want to say (all I can say) is that Anandtech has some of the best writers and commenters in this field. Fantastic article, and fantastic discussion.paldU - Saturday, July 7, 2018 - link
A typo in Page 2. "it terms of performance per dollar" should be " in terms of performance per dollar".