HiSilicon Kirin 970 - Android SoC Power & Performance Overview
by Andrei Frumusanu on January 22, 2018 9:15 AM ESTAn Introduction to Neural Network Processing
AI is currently the big buzzword when talking about consumer electronics. While marketing departments all over are trying to embrace the term, when we’re talking about the current use of AI in computing terms we’re specifically talking about machine learning. More precisely when talking about the latest generations of silicon IPs, we’re talking about the implementation of specialized hardware block which are optimized to run convolutional neural networks (CNNs).
While explaining how convolutional neural networks work in detail is far beyond this piece, they have been a research topic since the 1980’s. The idea is to try to simulate the behaviour of the human brain’s neurons. The keyword here again is simulation; no the various neural network IP’s hardware implementations do not mimic the human brain structure. While the field of neural networks in academia has been around for a long time, it’s only been in the last decade with the introduction software implementations that are able to run on GPUs that things have literally accelerated to become a lot more interesting. Via breakthroughs over the last half-decade, we’ve seen researchers iterate and develop CNN models that improve in terms of accuracy and efficiency.
Looking under the hood, it turns out that CNNs map pretty well to highly threaded execution models. The work itself has minimal branching or other "complex" behavior that requires a general purpose processor (CPU), and instead can typically be broken up into discrete, semi-independent threads. Furthermore the required computational accuracy is not all that high – running fully developed networks can be done via low-precision integers in some cases – again simplifying the scope of the problem. As a result, CNN research & development hit its stride earlier this decade when GPUs began shipping with the necessary compute features and the overall performance to resolve complex CNN execution in a reasonable-by-human-standards timeframe.
Of course, while GPUs have been the most adapted to running them, GPUs are not the only kind of highly parallel processor out there. As the field is evolving and companies want to commercialize their use in actual use-cases, we saw the need for much higher performance requirements as well as consideration for power efficiency. At this point we started seeing the move towards more specialized processing units whose architecture is built with machine learning in mind. Google was the first to announce such hardware with the announcement of the TPU back in 2016. More specialized hardware loses some flexibility, but in turn it gains power and area (die space) efficiency by only including the hardware and features necessary for the task.

There are two key aspect to actually running NN workloads: first you have to have a trained model which contains the actual information that describes the data that the model is later meant to be run on. The training of models is rather processor intensive – not only is it a lot of work to begin with, but it has to be done with greater levels of precision than the execution of those models, which is to say that efficient neural network training requires more powerful and complex hardware than executing neural networks. Consequently, the idea is that the bulk of models will be trained by high performance hardware, such as server-class GPUs and specialized hardware such a Google’s TPUs on servers in the cloud.
The second aspect of NN is the execution the models; taking the completed models, feeding them new data, and generating results based on what the model perceives. The execution of a neural network model with input data to get an output result is called inferencing. And not unlike the conceptual differences between training and inferencing, the compute requirements for inferencing are quite a bit different as well. The name of the game is still highly parallel compute, but it can be done with lower precision computations and the overall amount of performance required for timely execution is lower as well. Which means that inference can be done on cheaper hardware in many more locations and scenarios.
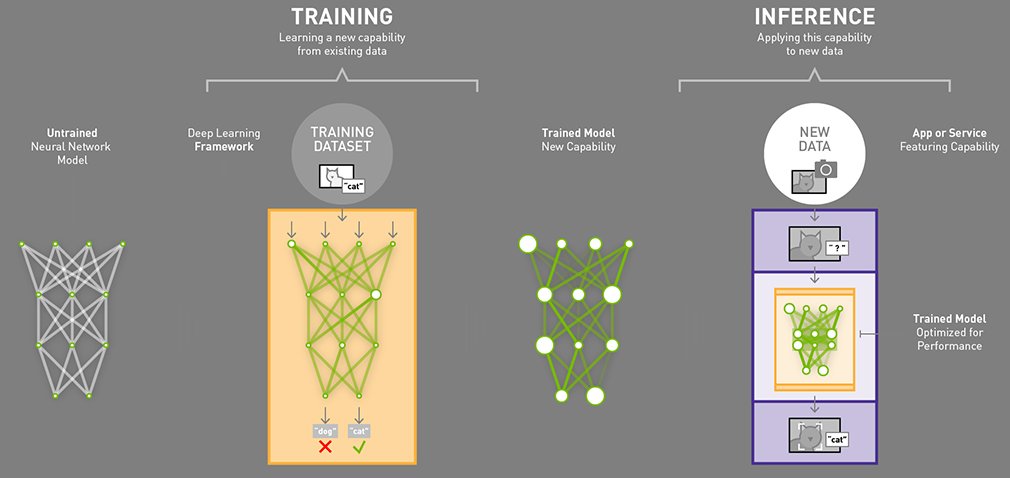
Graphic source: Nvidia Blog
This in turn has caused the industry to move towards inferencing on edge devices (consumer devices) because it’s a much more performant and power efficient. If you have your trained model on your device locally you can just use the processing power of the device to run the inference and avoid having to upload data to the cloud and have a server do it. This alleviates issues such as latency, bandwidth, and power consumption but also eliminates privacy concerns as the input data never leaves your device.
With the goal of running neural network inferencing locally on an edge device, we have the choice of running the implementation on various different processing blocks on devices such as a smartphone. CPU, GPU and even DSPs are all able to run inferencing tasks, however there are vast efficiency differences between them. General purpose CPUs are the least suited for the task as they are not designed with massive parallelised execution in mind. GPUs and DSPs are much better choices but even then there’s much room for improvement. It is here were we see a new class of processing accelerator like the NPU on the Kirin 970.
As these new IP blocks are still new the industry hasn’t had time to agree on a common nomenclature. HiSilicon/Huawei have coined the term NPU/neural processing unit while Apple publicly uses NE/neural engine. Other IP providers such as Cadence/Tensilica just outright call their implementation a neural network DSP (Vision C5), Imagination Technologies (Series 2NX) uses the term NNA/neural network accelerator and CEVA’s NeuPro settled on the marketing friendly “AI processor”. In the sense of simplicity I’ll just continue to refer to them as neural network IPs.
In the case of the Kirin 970 the NPU is provided by a new Chinese IP provider called Cambricon. The Kirin 970 NPU however isn’t a straight off-the-shelf offering but rather a co-development between Cambricon and HiSilicon optimized to HiSilicon’s requirements. Huawei quotes 2 TeraOPS FP16 performance on the IP, however this metric is misleading as the performance figure quotes sparse equivalent peak data, meaning the 8-bit quantized throughput. At this point in time we should largely shy away from theoretical performance figures of the neural network IPs as they don’t necessarily correlate to actual performance and there’s less understood architectural characteristics of the IPs that can play larger roles for the resulting end-performance.
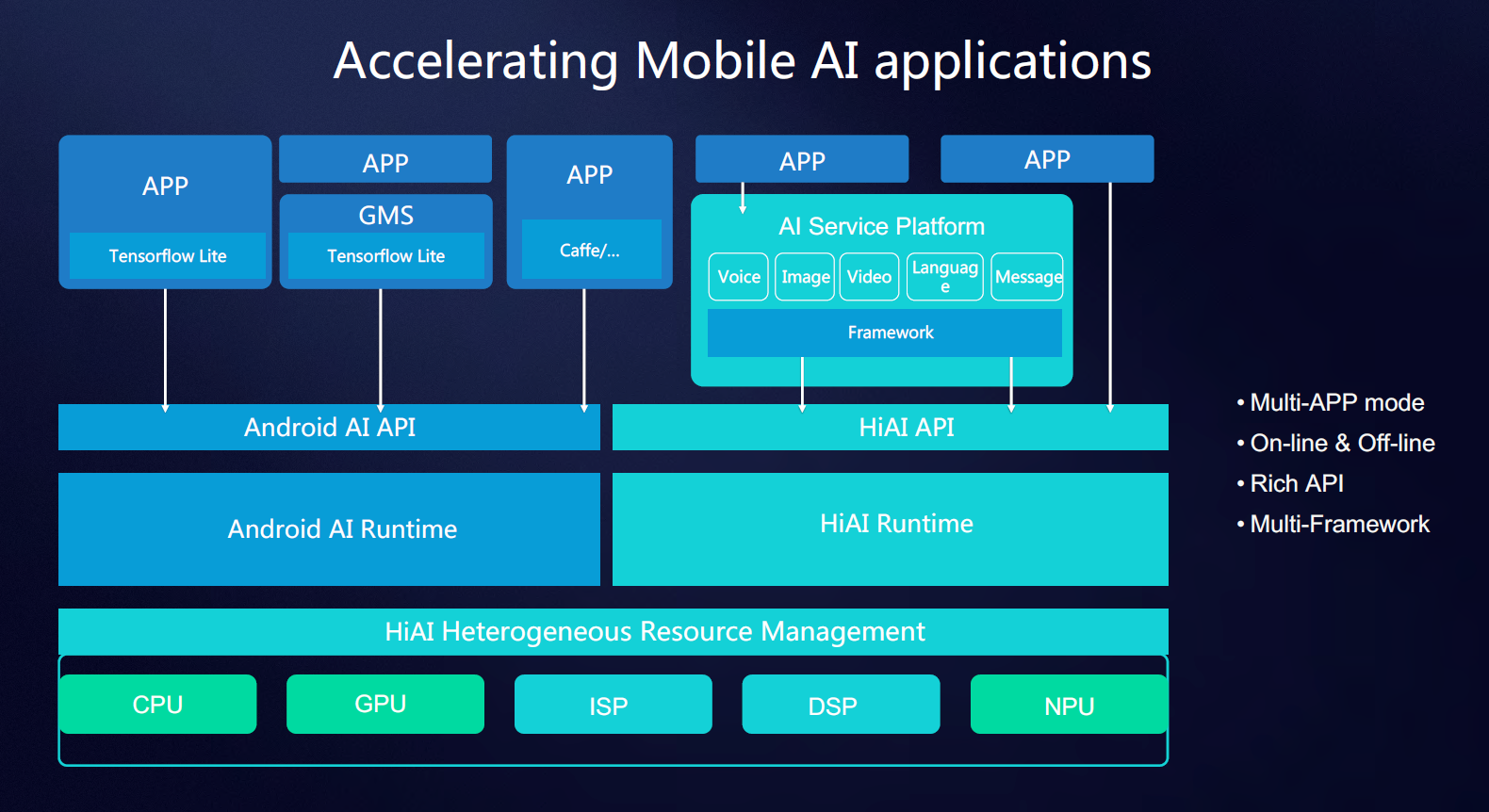
The first hurdle to using a neural network on a hardware block other than the CPU is to make use of the proper APIs to access that block. The SoC and IP vendors all currently ship proprietary APIs and SDKs to enable application development for using hardware acceleration for neural networks. In the case of HiSilicon they offer the HiAI API which can manage the workloads between CPU, GPU and NPU. The API is currently not publicly available as it’s still under development, but developers which reach out to HiSilicon can get early access before the public release later in the year. Vendors such as Qualcomm make available the SNPE (Snapdragon Neural Processing Engine) SDK which does the equivalent task of enabling app developers to tap into resources of the GPU and DSP for neural network processing workloads. Other IP vendors of course have their own SDKs for their respective IPs.
However vendor-specific APIs may end up being a temporary quirk of the present time; the goal in the future is to have a common universal API alongside the respective vendor’s IPs. Google has already been working on this and the NN API introduced in Android 8.1 is already actively shipping on Pixel 2 devices. One note that I’ve been made aware of is that currently the NN API only supports a subset of features that is available to IP like the NPU, so for developers to take full advantage of the hardware and extract maximum performance Huawei still sees application developers targeting the various proprietary APIs while using the NN API as a fall-back method.








116 Comments
View All Comments
GreenReaper - Thursday, January 25, 2018 - link
If it can do 2160p60 Decode then I'd imagine that of course it can do 2160p30 Decode, just as it can do 1080p60/30 decode. You list the maximum in a category.yhselp - Tuesday, January 23, 2018 - link
What a wonderful article: a joy to read, thoughtful, and very, very insightful. Thank you, Andrei. Here's to more coverage like that in the future.It looks like the K970 could be used in smaller form factors. If Huawei were to make a premium, bezel-less ~ 4.8" 18:9 model power by K970, it would be wonderful - a premium, Android phone about the size of the iPhone SE.
Even though Samsung and Qualcomm (S820) have custom CPUs, it feels like their designs are much closer to stock ARM than Apple's CPUs. Why are they not making wider designs? Is it a matter of inability or unwillingness?
Raqia - Tuesday, January 23, 2018 - link
Props for a nice article with data rich diagrams filled with interesting metrics as well as the efforts to normalize tests now and into the future w/ LLVM + SPECINT 06. (Adding the units after the numbers in the chart and "avg. watts" to the rightward pointing legend at the bottom would have helped me grok faster...) Phones are far from general purpose compute devices and their CPUs are mainly involved in directing program flow rather than actual computation, so leaning more heavily into memory operations with the larger data sets of SPECINT is a more appropriate CPU test than Geekbench. The main IPC uplift from OoOE comes from the prefetching and execution in parallel of the highest latency load and store operations and a good memory/cache subsystem does wonders for IPC in actual workloads. Qualcomm's Hexagon DSP hasIt would be interesting to see the 810 here, but its CPU figures would presumably blow off the chart. A modem or wifi test would also be interesting (care for a donation toward the aforementioned harness?), but likely a blowout in the good direction for the Qualcomm chipsets.
Andrei Frumusanu - Friday, January 26, 2018 - link
Apologies for the chart labels, I did them in Excel and it doesn't allow for editing the secondary label position (watts after J/spec).The Snapdragon 810 devices wouldn't have been able to sustain their peak performance states for SPEC so I didn't even try to run it.
Unless your donation is >$60k, modem testing is far beyond the reach of AT because of the sheer cost of the equipment needed to do this properly.
jbradfor - Wednesday, January 24, 2018 - link
Andrei, two questions on the Master Lu tests. First, is there a chance you could run it on the 835 GPU as well and compare? Second, do these power number include DRAM power, or are they SoC only? If they do not include DRAM power, any chance you could measure that as well?Andrei Frumusanu - Friday, January 26, 2018 - link
The Master Lu uses the SNPE framework and currently doesn't have the option to chose computing target on the SoC. The GPU isn't any or much faster than the DSP and is less efficient.The power figures are the active power of the whole platform (total power minus idle power) so they include everything.
jbradfor - Monday, January 29, 2018 - link
Thanks. Do you have the capability of measuring just the SoC power separately from the DRAM power?ReturnFire - Wednesday, January 24, 2018 - link
Great article Andrei. So glad there is new mobile stuff on AT. Fingers crossed for more 2018 flagship / soc articles!KarlKastor - Thursday, January 25, 2018 - link
"AnandTech is also partly guilty here; you have to just look at the top of the page: I really shouldn’t have published those performance benchmarks as they’re outright misleading and rewarding the misplaced design decisions made by the silicon vendors. I’m still not sure what to do here and to whom the onus falls onto."That is pretty easy. Post sustained performace values and not only peak power. Just run the benchmarks ten times in a row, it's not that difficult.
If in every review sustained performance is shown, the people will realize this theater.
And it is a big problem. Burst GPU performance is useless. No one plays a game for half a minute.
Burst CPU performance ist perhaps a different matter. It helps to optimize the overall snappiness.
Andrei Frumusanu - Friday, January 26, 2018 - link
I'm planning to switch to this in future reviews.