The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTBenchmarking Performance: CPU Rendering Tests
Rendering tests are a long-time favorite of reviewers and benchmarkers, as the code used by rendering packages is usually highly optimized to squeeze every little bit of performance out. Sometimes rendering programs end up being heavily memory dependent as well - when you have that many threads flying about with a ton of data, having low latency memory can be key to everything. Here we take a few of the usual rendering packages under Windows 10, as well as a few new interesting benchmarks.
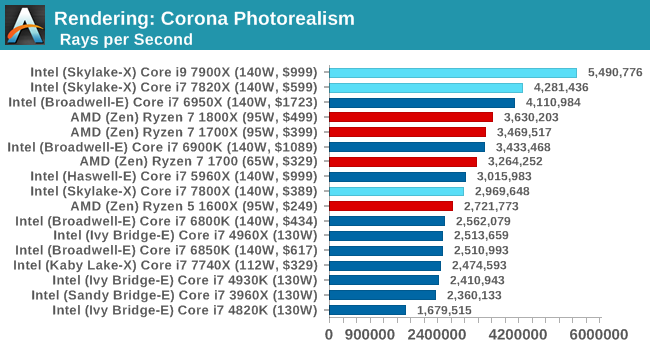
Corona 1.3
Corona is a standalone package designed to assist software like 3ds Max and Maya with photorealism via ray tracing. It's simple - shoot rays, get pixels. OK, it's more complicated than that, but the benchmark renders a fixed scene six times and offers results in terms of time and rays per second. The official benchmark tables list user submitted results in terms of time, however I feel rays per second is a better metric (in general, scores where higher is better seem to be easier to explain anyway). Corona likes to pile on the threads, so the results end up being very staggered based on thread count.
Blender 2.78
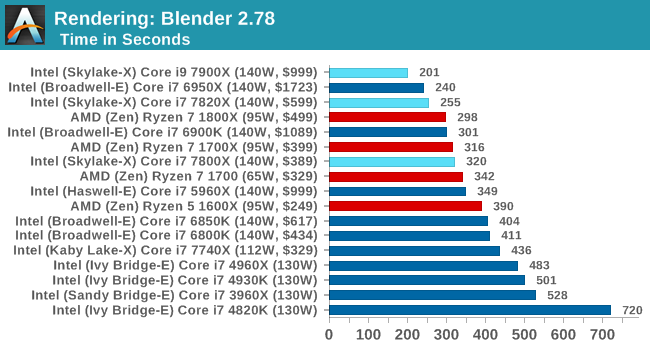
For a render that has been around for what seems like ages, Blender is still a highly popular tool. We managed to wrap up a standard workload into the February 5 nightly build of Blender and measure the time it takes to render the first frame of the scene. Being one of the bigger open source tools out there, it means both AMD and Intel work actively to help improve the codebase, for better or for worse on their own/each other's microarchitecture.
LuxMark
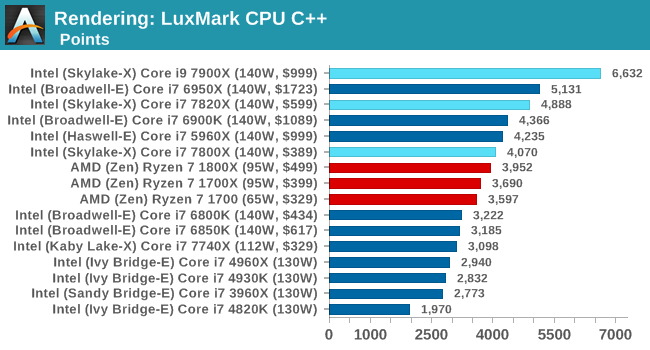
As a synthetic, LuxMark might come across as somewhat arbitrary as a renderer, given that it's mainly used to test GPUs, but it does offer both an OpenCL and a standard C++ mode. In this instance, aside from seeing the comparison in each coding mode for cores and IPC, we also get to see the difference in performance moving from a C++ based code-stack to an OpenCL one with a CPU as the main host.
POV-Ray 3.7b3
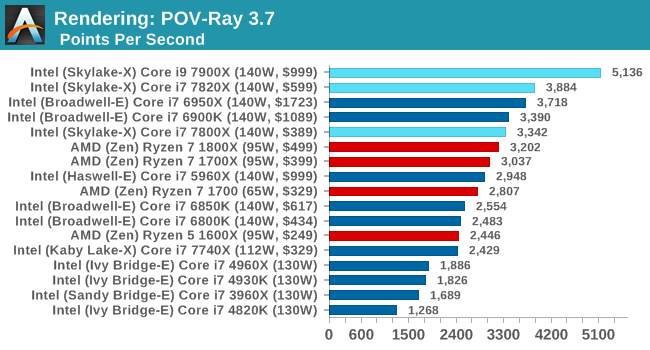
Another regular benchmark in most suites, POV-Ray is another ray-tracer but has been around for many years. It just so happens that during the run up to AMD's Ryzen launch, the code base started to get active again with developers making changes to the code and pushing out updates. Our version and benchmarking started just before that was happening, but given time we will see where the POV-Ray code ends up and adjust in due course.
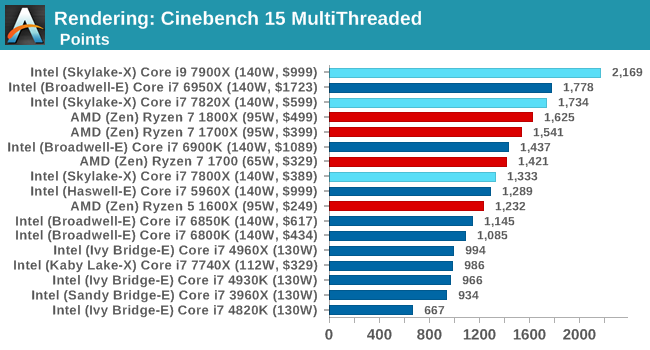
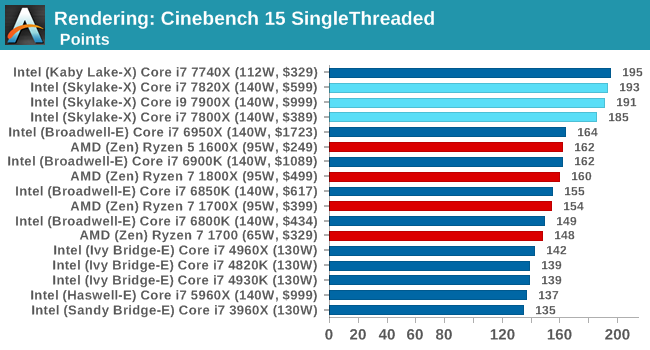
Cinebench R15
The latest version of CineBench has also become one of those 'used everywhere' benchmarks, particularly as an indicator of single thread performance. High IPC and high frequency gives performance in ST, whereas having good scaling and many cores is where the MT test wins out.








264 Comments
View All Comments
Tephereth - Tuesday, June 20, 2017 - link
"For each of the GPUs in our testing, these games (at each resolution/setting combination) are run four times each, with outliers discarded. Average frame rates, 99th percentiles and 'Time Under x FPS' data is sorted, and the raw data is archived."So... where the hell are the games benchmarks in this review?
beck2050 - Tuesday, June 20, 2017 - link
The possibility of the 18 core beast in the upcoming Mac Pro is really exciting for music pros.That is a tremendous and long overdue leap for power users.
drajitshnew - Tuesday, June 20, 2017 - link
"... and only three PCIe 3.0 x4 drives can use the in-built PCIe RAID"I would like to know which raid level you would use. I can't see 3 m2 drives in raid 1, and raid 5 would require access to the cpu for parity calculations. Then raid 0 it is. Now, which drives will you use for raid 0, which do not saturate the DMI link for sequential reads? And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
PeterCordes - Tuesday, June 20, 2017 - link
Standard motherboard RAID controllers are software raid anyway, where the OS drivers queue up writes to each drive separately, instead of sending the data once over the PCIe bus to a hardware RAID controller which queues writes to two drives.What makes it a "raid controller" is that you can boot from it, thanks to BIOS support. Otherwise it's not much different from Linux or Windows pure-software RAID.
If the drivers choose to implement RAID5, that can give you redundancy on 3 drives with the capacity of 2.
However, RAID5 on 3 disks is not the most efficient way. A RAID implementation can get the same redundancy by just storing two copies of every block, instead of generating parity. That avoids a ton of RAID5 performance problems, and saves CPU time. Linux md software RAID implements this as RAID10. e.g. RAID10f2 stores 2 copies of every block, striped across as many disks as you have. It works very well with 3 disks. See for example https://serverfault.com/questions/139022/explain-m...
IDK if Intel's mobo RAID controllers support anything like that or not. I don't use the BIOS to configure my RAID; I just put a boot partition on each disk separately and manage everything from within Linux. IDK if other OSes have soft-raid that supports anything similar either.
> And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
That's a silly question. RAID0, RAID1, and RAID5 over 3 disks should all have 3x the random read throughput of a single disk, at least for high queue depths, since each disk will only see about 1/3rd of the reads. RAID0 similarly has 3x random write throughput.
RAID10n2 of 3 disks can have better random write throughput than a single disk, but RAID5 is much worse. RAID1 of course mirrors all the writes to all the disks, so it's a wash for writes. (But can still gain for mixed read and write workloads, since the reads can be distributed among the disks).
Lieutenant Tofu - Tuesday, June 20, 2017 - link
I wonder why 1600X outperforms 1800X here on WebXPRT. It's not a huge difference, but I don't see why it's happening. 6-core vs. 8-core, 3.6 GHz base, 4.0 GHz turbo. This presumably runs in just one thread, so performance should be nearly identical. The only reason I can think of is less contention across the IF on the 1600X due to less enabled cores, but don't see that having a major effect on a single-threaded test like this one.Maybe 1600X can XFR to a little higher than the 1800X.
Eyered - Tuesday, June 20, 2017 - link
Did they have any issues with heat at all?mat9v - Tuesday, June 20, 2017 - link
If that were so everyone would be using HEDT instead of 4c/8t CPUsmat9v - Tuesday, June 20, 2017 - link
Then why again why aren't every workstation consist of dual cpu xeons? If the expense is so insignificant compared to how much faster machine will earn...mat9v - Tuesday, June 20, 2017 - link
I'm just wondering how did 7900X menage to stay within 140W bracket during Prome95 tests when in other reviews it easily reached 250W or more. Is it some internal throttling mechanism that keeps CPU constantly dynamically underclocked to stay within power envelope? How does such compare to forced 4Ghz CPU clock?mat9v - Tuesday, June 20, 2017 - link
And yet in conclusion you say to play it safe and get 7900X ?How does that work together?