Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
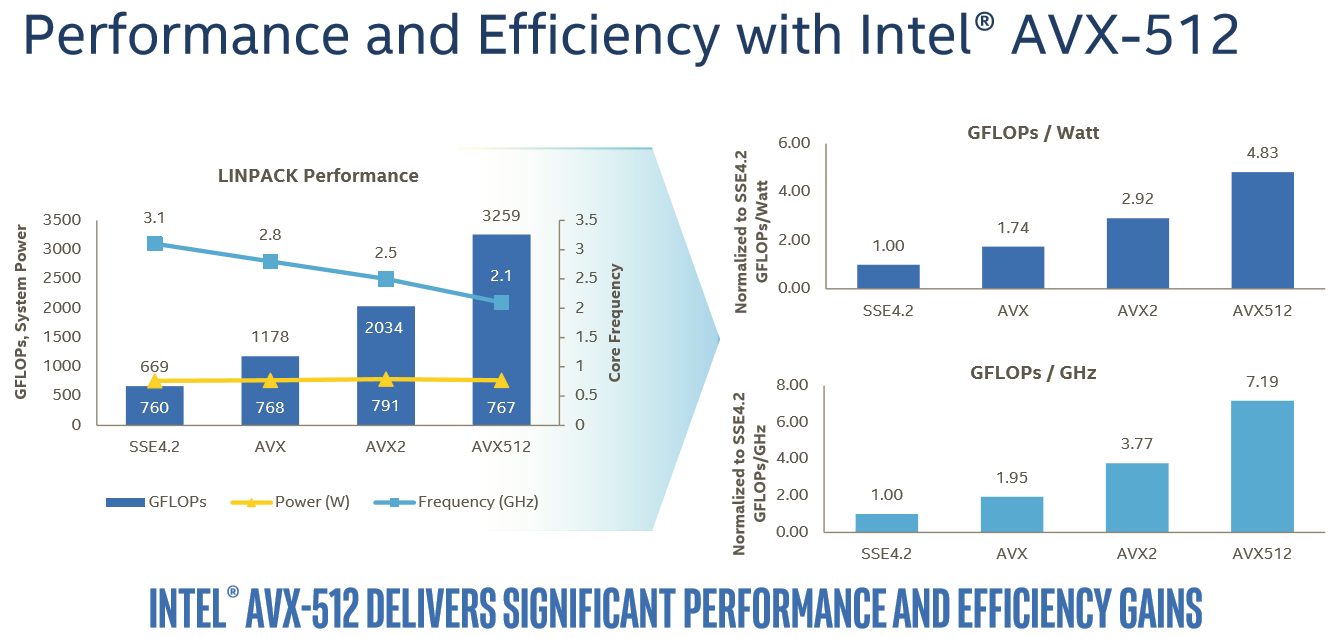
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
Kaotika - Tuesday, July 11, 2017 - link
http://www.anandtech.com/show/11464/intel-announce...This one remains wrong though
Ian Cutress - Tuesday, July 11, 2017 - link
Always reference the newest piece, especially the main review.Or we'd spend half of our time going back and updating old pieces and reviews with new data.
scottb9239 - Tuesday, July 11, 2017 - link
On the POV-RAY benchmark, shouldn't that read as almost 16% faster than the dual 2699 v4 and 32% faster than the dual 8176?scienceomatica - Tuesday, July 11, 2017 - link
I think that a fair game would be to compare the top offer of one and the other manufacturer, in other words, the Xeon 8180 should be included in the benchmark regardless of the aspect of the price. Then the difference would be quite in favor of the Intel processor, although it has few cores less.Tamz_msc - Tuesday, July 11, 2017 - link
Will we get to see more FP HPC-oriented workloads like SPECfp2006 or even 2017 being discussed in a future article?lefty2 - Tuesday, July 11, 2017 - link
I can summarize this article: "$8719 chip beaten by $4200 chip in everything except database and Appache spark."Well done Intel, another Walletripper!
Shankar1962 - Wednesday, July 12, 2017 - link
Then why did google att aws etc upgraded to skylake. They could have saved billions of dollars.Shankar1962 - Wednesday, July 12, 2017 - link
Look at what big players upgrading to skylake reportedThese are real workloads
No one cares about labs
These numbers decide who wins and who loses
No wonder AMD sells at $4200
https://www.google.com/amp/s/seekingalpha.com/amp/...
nitrobg - Tuesday, July 11, 2017 - link
Pricing on page 10 should reflect that the 2P EPYC prices are for 2 processors, not per CPU. The price of Xeons is per CPU.coder543 - Tuesday, July 11, 2017 - link
That doesn't seem true. The prices they currently have seem to be correct. Got a source?