Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
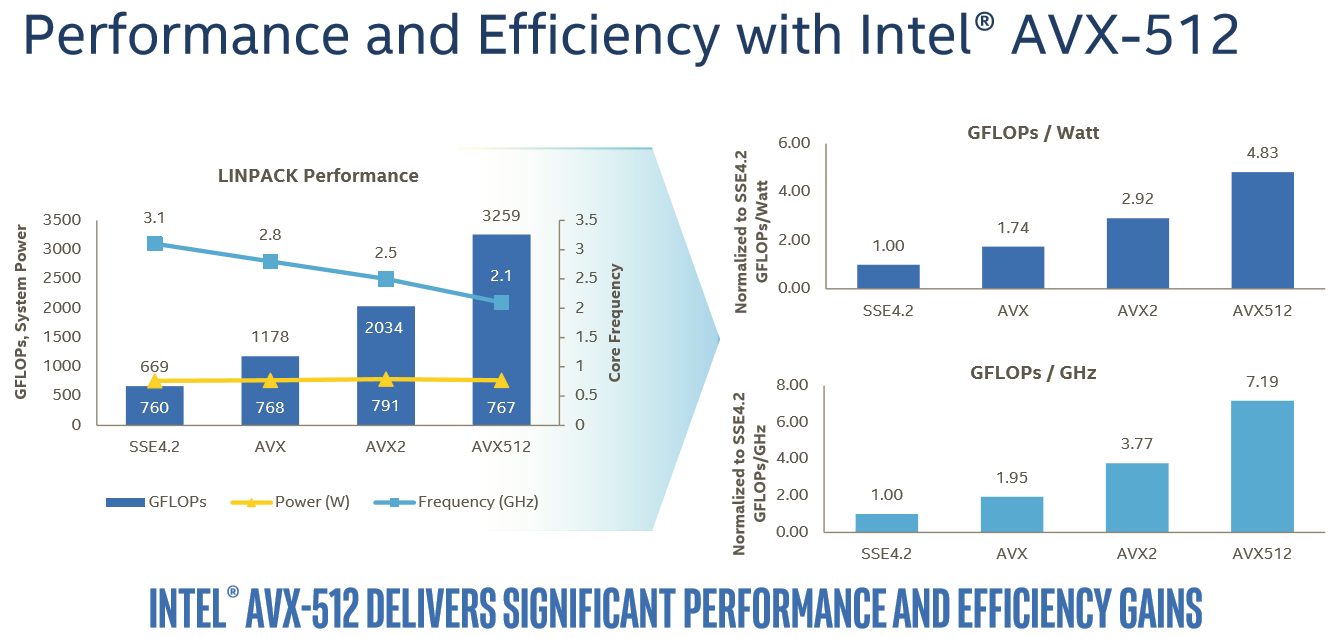
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
msroadkill612 - Wednesday, July 12, 2017 - link
It looks interesting. Do u have a point?Are you saying they have a place in this epyc debate? using cheaper ddr3 ram on epyc?
yuhong - Friday, July 14, 2017 - link
"We were told from Intel that ‘only 0.5% of the market actually uses those quad ranked and LR DRAMs’, "intelemployee2012 - Wednesday, July 12, 2017 - link
what kind of a forum and website is this? we can't delete the account, cannot edit a comment for fixing typos, cannot edit username, cannot contact an admin if we need to report something. Will never use these websites from now on.Ryan Smith - Wednesday, July 12, 2017 - link
"what kind of a forum and website is this?"The basic kind. It's not meant to be a replacement for forums, but rather a way to comment on the article. Deleting/editing comments is specifically not supported to prevent people from pulling Reddit-style shenanigans. The idea is that you post once, and you post something meaningful.
As for any other issues you may have, you are welcome to contact me directly.
Ranger1065 - Thursday, July 13, 2017 - link
That's a relief :)iwod - Wednesday, July 12, 2017 - link
I cant believe what i just read. While I knew Zen was good for Desktop, i expected the battle to be in Intel's flavour on the Server since Intel has years to tune and work on those workload. But instead, we have a much CHEAPER AMD CPU that perform Better / Same or Slightly worst in several cases, using much LOWER Energy during workload, while using a not as advance 14nm node compared to Intel!And NO words on stability problems from running these test on AMD. This is like Athlon 64 all over again!
pSupaNova - Wednesday, July 12, 2017 - link
Yes it is.But this time much worse for Intel with their manufacturing lead shrinking along with their workforce.
Shankar1962 - Wednesday, July 12, 2017 - link
Competition has spoiled the naming convention Intels 14 === competetions 7 or 10Intel publicly challenged everyone to revisit the metrics and no one responded
Can we discuss the yield density and scaling metrics? Intel used to maintain 2year lead now grew that to 3-4year lead
Because its vertically integrated company it looks like Intel vs rest of the world and yet their revenue profits grow year over year
iwod - Thursday, July 13, 2017 - link
Grew to 3 - 4 years? Intel is shipping 10nm early next year in some laptop segment, TSMC is shipping 7nm Apple SoC in 200M yearly unit quantity starting next September.If anything the gap from 2 - 3 years is now shrink to 1 to 1.5 year.
Shankar1962 - Thursday, July 13, 2017 - link
Yeah 1-1.5 years if we cheat the metrics when comparison2-3years if we look at metrics accurately
A process node shrink is compared by metrics like yield cost scaling density etc
7nm 10nm etc is just a name