Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
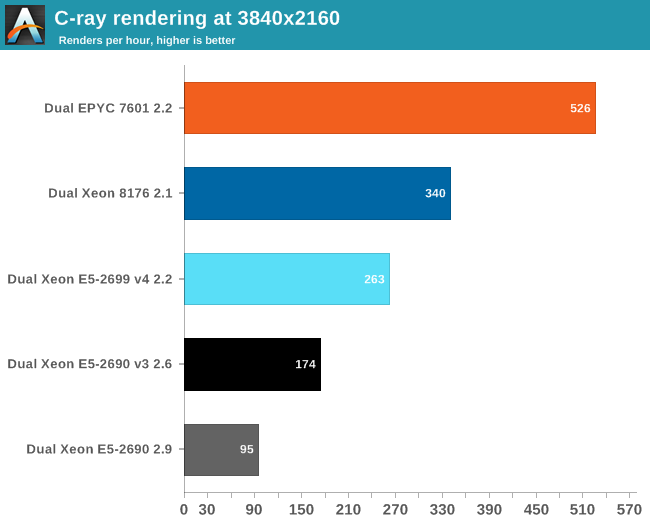
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
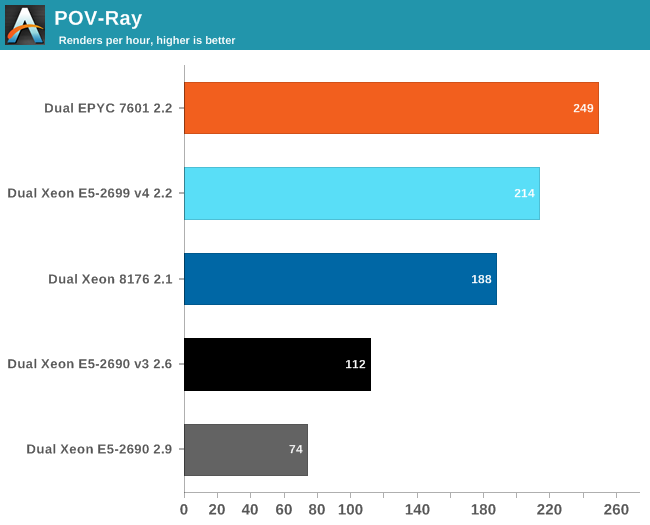
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
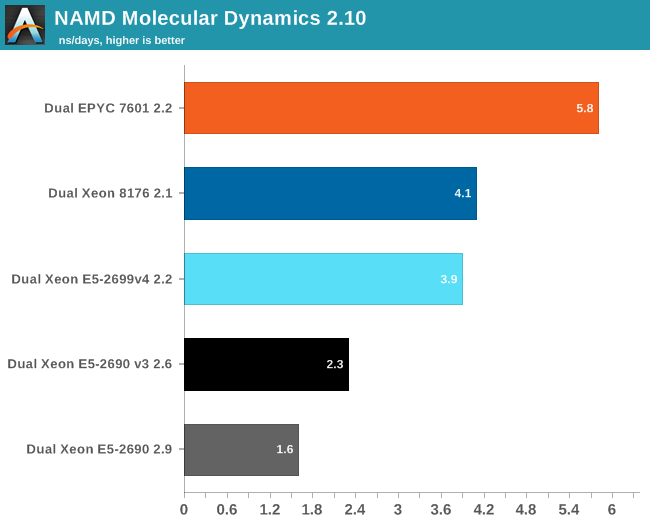
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
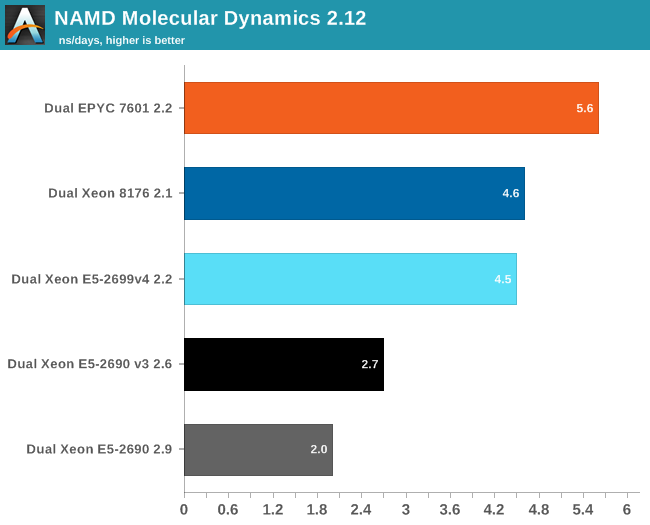
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
msroadkill612 - Wednesday, July 12, 2017 - link
It looks interesting. Do u have a point?Are you saying they have a place in this epyc debate? using cheaper ddr3 ram on epyc?
yuhong - Friday, July 14, 2017 - link
"We were told from Intel that ‘only 0.5% of the market actually uses those quad ranked and LR DRAMs’, "intelemployee2012 - Wednesday, July 12, 2017 - link
what kind of a forum and website is this? we can't delete the account, cannot edit a comment for fixing typos, cannot edit username, cannot contact an admin if we need to report something. Will never use these websites from now on.Ryan Smith - Wednesday, July 12, 2017 - link
"what kind of a forum and website is this?"The basic kind. It's not meant to be a replacement for forums, but rather a way to comment on the article. Deleting/editing comments is specifically not supported to prevent people from pulling Reddit-style shenanigans. The idea is that you post once, and you post something meaningful.
As for any other issues you may have, you are welcome to contact me directly.
Ranger1065 - Thursday, July 13, 2017 - link
That's a relief :)iwod - Wednesday, July 12, 2017 - link
I cant believe what i just read. While I knew Zen was good for Desktop, i expected the battle to be in Intel's flavour on the Server since Intel has years to tune and work on those workload. But instead, we have a much CHEAPER AMD CPU that perform Better / Same or Slightly worst in several cases, using much LOWER Energy during workload, while using a not as advance 14nm node compared to Intel!And NO words on stability problems from running these test on AMD. This is like Athlon 64 all over again!
pSupaNova - Wednesday, July 12, 2017 - link
Yes it is.But this time much worse for Intel with their manufacturing lead shrinking along with their workforce.
Shankar1962 - Wednesday, July 12, 2017 - link
Competition has spoiled the naming convention Intels 14 === competetions 7 or 10Intel publicly challenged everyone to revisit the metrics and no one responded
Can we discuss the yield density and scaling metrics? Intel used to maintain 2year lead now grew that to 3-4year lead
Because its vertically integrated company it looks like Intel vs rest of the world and yet their revenue profits grow year over year
iwod - Thursday, July 13, 2017 - link
Grew to 3 - 4 years? Intel is shipping 10nm early next year in some laptop segment, TSMC is shipping 7nm Apple SoC in 200M yearly unit quantity starting next September.If anything the gap from 2 - 3 years is now shrink to 1 to 1.5 year.
Shankar1962 - Thursday, July 13, 2017 - link
Yeah 1-1.5 years if we cheat the metrics when comparison2-3years if we look at metrics accurately
A process node shrink is compared by metrics like yield cost scaling density etc
7nm 10nm etc is just a name