Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
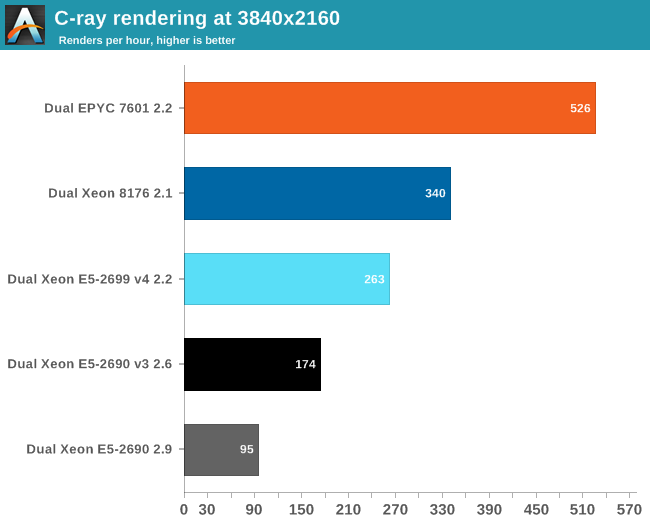
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
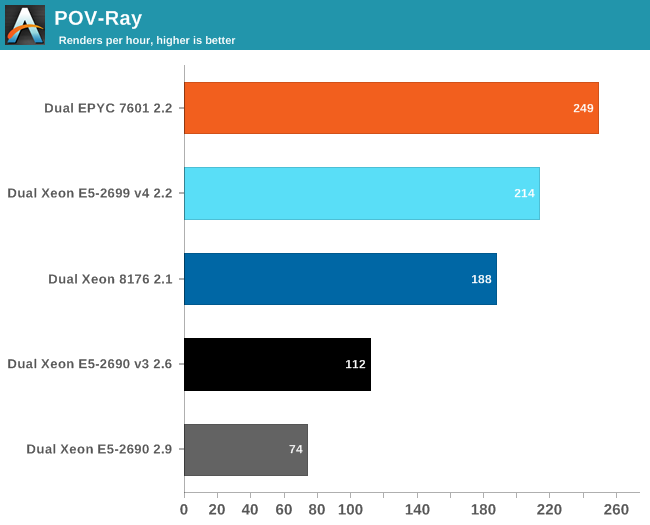
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
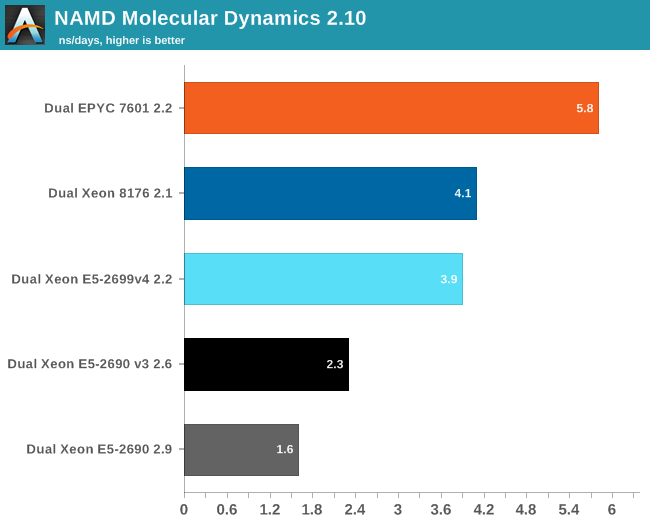
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
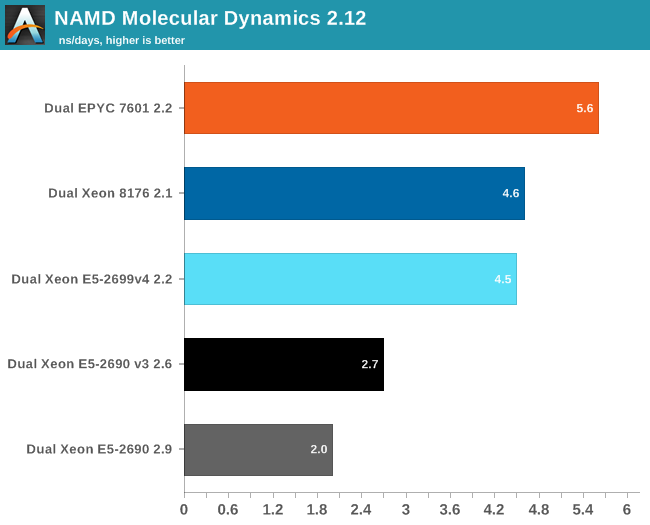
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
JohanAnandtech - Friday, July 21, 2017 - link
Thanks! It is was a challenge, and we will update this article later on, when better kernel support is available.serendip - Tuesday, July 11, 2017 - link
What idiot marketroid thought it was cool to have a huge list of SKUs and gimped "precious metals" branding? I'd like to see Epyc kicking Xeon butt simply because AMD has much more sensible product lists and there's not much gimping going on.ParanoidFactoid - Tuesday, July 11, 2017 - link
Reading through this, the takeaway seems thus. Epyc has latency concerns in communicating between CCX blocks, though this is true of all NUMA systems. If your application is latency sensitive, you either want a kernel that can dynamically migrate threads to keep them close to their memory channel - with an exposed API so applications can request migration. (Linux could easily do this, good luck convincing MS). OR, you take the hit. OR, you buy a monolithic die Intel solution for much more capital outlay. Further, the takeaway on Intel is, they have the better technology. But their market segmentation strategy is so confusing, and so limiting, it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy. Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market.msroadkill612 - Wednesday, July 12, 2017 - link
"it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy.Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market."
& given time is money, & intelwastes customers time, then intel is expensive.
Those guys will go intel anyway, but just sayin, there is already talk of a 48 core zen cpu, making 98 cores on a mere 2p mobo.
As i have posted b4, if wall street starts liking gpu compute for prompter answers, amdS monster apuS will be unanswerable.
nils_ - Wednesday, July 19, 2017 - link
98 cores on a 2p mobo isn't quite right if you keep in mind that the 32 core versions already constitute a 4 CPU system, unless AMD somehow manages to get more cores on a single die.nils_ - Wednesday, July 19, 2017 - link
Good analysis, although Sun and IBM are still coming out with new CPUs and at least with IBM there is renewed interest in the POWER ecosystem.eek2121 - Wednesday, July 12, 2017 - link
, but rather AMD's spanking new EPYC server CPU. Both CPUs are without a doubt very different: micro architecture, ISA extentions, <snip>Should be extensions.
intelemployee2012 - Wednesday, July 12, 2017 - link
After looking at the number of people who really do not fully understand the entire architecture and workloads and thinking that AMD Naples is superior because it has more cores, pci lanes etc is surprising.AMD made a 32 core server by gluing four 8core desktop dies whereas Intel has a single die balanced datacenter specific architecture which offers more perf if you make the entire Rack comparison. It's not the no of cores its the entire Rack which matters.
Intel cores are superior than AMD so a 28 core xeon is equal to ~40 cores if you compare again Ryzen core so this whole 28core vs 32core is a marketing trick. Everyone thinks Intel is expensive but if you go by performance per dollar Intel has a cheaper option at every price point to match Naples without compromising perf/dollar.
To be honest with so many Fabs, don't you think Intel is capable of gluing desktop dies to create a 32core,64core or evn 128core server (if it wants to) if thats the implementation style it needs to adopt like AMD?
The problem these days is layman looks at just numbers but that's not how you compare.
sharath.naik - Wednesday, July 12, 2017 - link
Agree, Most who look at these numbers will walk away thinking AMD is doing well with EPYC. The article points out the approach to testing and also states the performance challenges with EPYC, which can be missed who reading this review without the prior review on the older Xeons. For example the Big data test, I bet the newbies will walk away thinking EPYC beats the older XEONS E5 v4, as thats what the graphs show,without ever looking back at the numbers for a single 22 core Xeon e5 v4. So yes, a few back links in the article will be helpful.warreo - Wednesday, July 12, 2017 - link
Not a fanboi of either company, but care to elaborate more? I checked the original Xeon E5 v4 review. It shows that a single Xeon E5 v4 performs about 10% slower than a dual setup. Extrapolating that here, that means the single Xeon E5 v4 setup would be right around 4.5 jobs per day, which would make it roughly 50% slower than the dual Epyc and Xeon 8176.Sure, you could argue perf/dollar is better against a dual Epyc setup...but one could make the same argument against Intel's Skylake Xeons? I also wouldn't expect the performance to scale linearly anyway. Please let me know what I'm missing.