Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
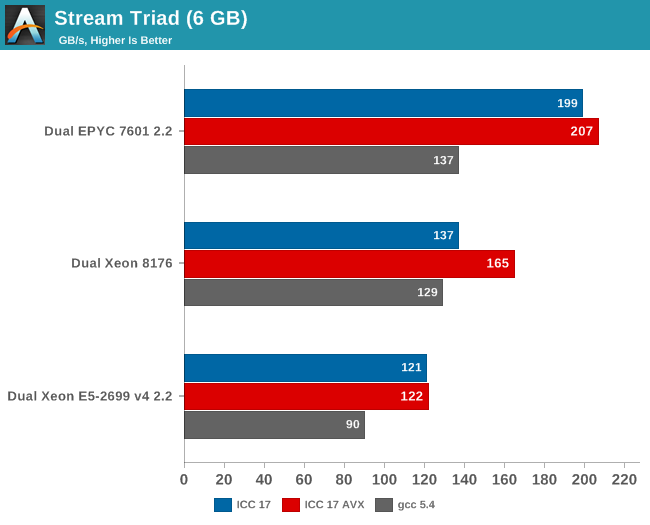
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
JohanAnandtech - Friday, July 21, 2017 - link
Thanks! It is was a challenge, and we will update this article later on, when better kernel support is available.serendip - Tuesday, July 11, 2017 - link
What idiot marketroid thought it was cool to have a huge list of SKUs and gimped "precious metals" branding? I'd like to see Epyc kicking Xeon butt simply because AMD has much more sensible product lists and there's not much gimping going on.ParanoidFactoid - Tuesday, July 11, 2017 - link
Reading through this, the takeaway seems thus. Epyc has latency concerns in communicating between CCX blocks, though this is true of all NUMA systems. If your application is latency sensitive, you either want a kernel that can dynamically migrate threads to keep them close to their memory channel - with an exposed API so applications can request migration. (Linux could easily do this, good luck convincing MS). OR, you take the hit. OR, you buy a monolithic die Intel solution for much more capital outlay. Further, the takeaway on Intel is, they have the better technology. But their market segmentation strategy is so confusing, and so limiting, it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy. Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market.msroadkill612 - Wednesday, July 12, 2017 - link
"it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy.Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market."
& given time is money, & intelwastes customers time, then intel is expensive.
Those guys will go intel anyway, but just sayin, there is already talk of a 48 core zen cpu, making 98 cores on a mere 2p mobo.
As i have posted b4, if wall street starts liking gpu compute for prompter answers, amdS monster apuS will be unanswerable.
nils_ - Wednesday, July 19, 2017 - link
98 cores on a 2p mobo isn't quite right if you keep in mind that the 32 core versions already constitute a 4 CPU system, unless AMD somehow manages to get more cores on a single die.nils_ - Wednesday, July 19, 2017 - link
Good analysis, although Sun and IBM are still coming out with new CPUs and at least with IBM there is renewed interest in the POWER ecosystem.eek2121 - Wednesday, July 12, 2017 - link
, but rather AMD's spanking new EPYC server CPU. Both CPUs are without a doubt very different: micro architecture, ISA extentions, <snip>Should be extensions.
intelemployee2012 - Wednesday, July 12, 2017 - link
After looking at the number of people who really do not fully understand the entire architecture and workloads and thinking that AMD Naples is superior because it has more cores, pci lanes etc is surprising.AMD made a 32 core server by gluing four 8core desktop dies whereas Intel has a single die balanced datacenter specific architecture which offers more perf if you make the entire Rack comparison. It's not the no of cores its the entire Rack which matters.
Intel cores are superior than AMD so a 28 core xeon is equal to ~40 cores if you compare again Ryzen core so this whole 28core vs 32core is a marketing trick. Everyone thinks Intel is expensive but if you go by performance per dollar Intel has a cheaper option at every price point to match Naples without compromising perf/dollar.
To be honest with so many Fabs, don't you think Intel is capable of gluing desktop dies to create a 32core,64core or evn 128core server (if it wants to) if thats the implementation style it needs to adopt like AMD?
The problem these days is layman looks at just numbers but that's not how you compare.
sharath.naik - Wednesday, July 12, 2017 - link
Agree, Most who look at these numbers will walk away thinking AMD is doing well with EPYC. The article points out the approach to testing and also states the performance challenges with EPYC, which can be missed who reading this review without the prior review on the older Xeons. For example the Big data test, I bet the newbies will walk away thinking EPYC beats the older XEONS E5 v4, as thats what the graphs show,without ever looking back at the numbers for a single 22 core Xeon e5 v4. So yes, a few back links in the article will be helpful.warreo - Wednesday, July 12, 2017 - link
Not a fanboi of either company, but care to elaborate more? I checked the original Xeon E5 v4 review. It shows that a single Xeon E5 v4 performs about 10% slower than a dual setup. Extrapolating that here, that means the single Xeon E5 v4 setup would be right around 4.5 jobs per day, which would make it roughly 50% slower than the dual Epyc and Xeon 8176.Sure, you could argue perf/dollar is better against a dual Epyc setup...but one could make the same argument against Intel's Skylake Xeons? I also wouldn't expect the performance to scale linearly anyway. Please let me know what I'm missing.