Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
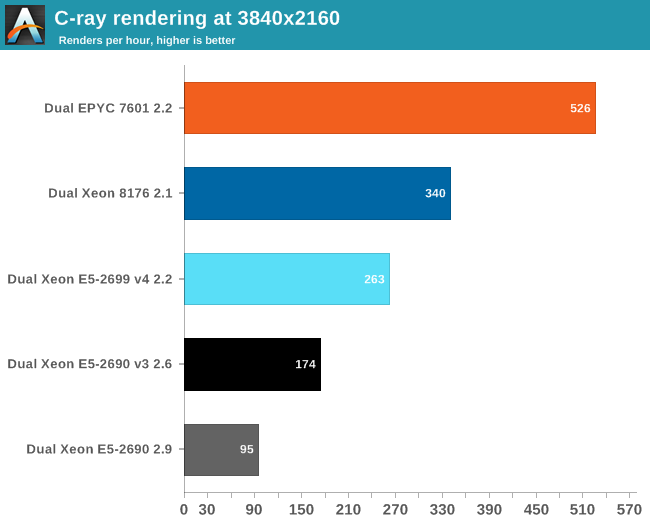
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
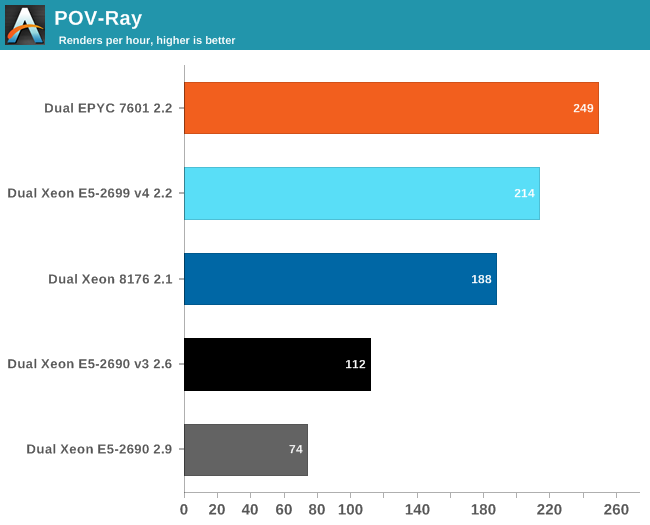
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
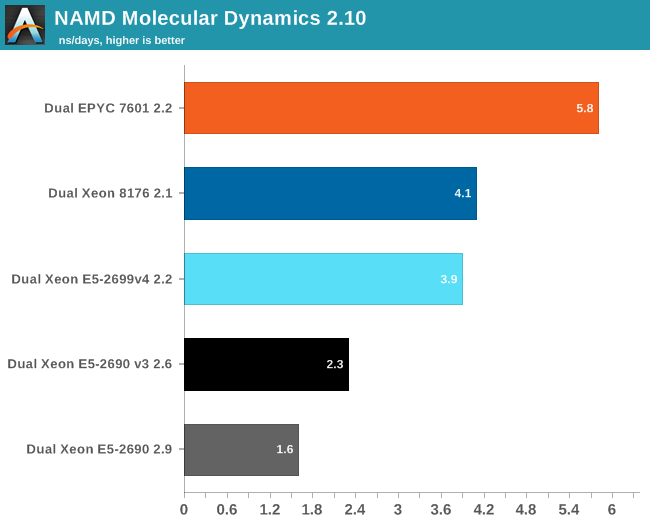
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
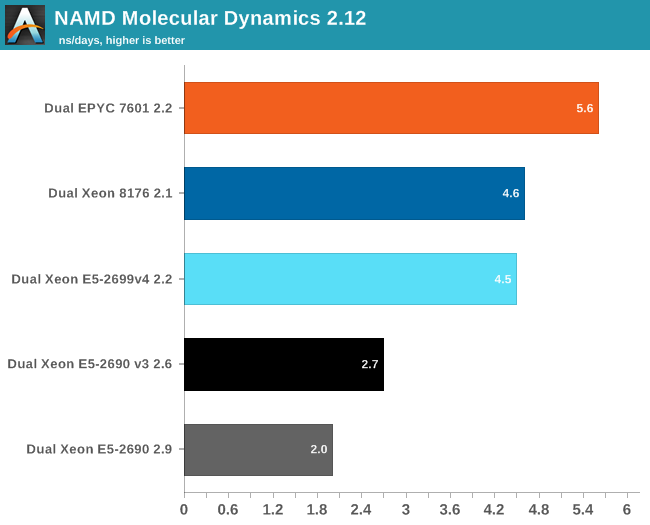
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
extide - Tuesday, July 11, 2017 - link
PCPer made this same mistake -- Nehalem/Westmere used a crossbar memory bus -- not a ringbus. Only Nehalem/Westmere EX used the ringbus (the 6500/7500 series) The i7 and Xeon 5500 and 5600 series used the crossbar.extide - Tuesday, July 11, 2017 - link
Sandy Bridge brought the ringbus down to Xeon EP and client chips.Yorgos - Tuesday, July 11, 2017 - link
"With the complexity of both server hardware and especially server software, that is very little time. There is still a lot to test and tune, but the general picture is clear."No wonder why we see ubuntu and ancient versions of gcc and the rest of the s/w stack.
Imagine if you tried to use debian or rhel, it would take you decades to get the review.
eligrey - Tuesday, July 11, 2017 - link
Why did you omit the Turbo frequencies for the Xeon Gold 6146 and 6144?Intel ARK says that the 6146's turbo frequency is 4.2GHz and the 6144's is 4.5GHz.
eligrey - Tuesday, July 11, 2017 - link
Oops, I mean 4.2GHz for both.boozed - Tuesday, July 11, 2017 - link
Need more Skylake-SP SKUsrHardware - Tuesday, July 11, 2017 - link
For the purley system, It's listed that you used Chipset Intel Wellsburg B0This information cannot be correct. Lewisburg Chipset is the name of the purley chipset. Also, B0 stepping lewisburg also wouldn't boot with the stepping of CPU you have.
rHardware - Tuesday, July 11, 2017 - link
That 0200011 microcode is also very old.Rickyxds - Tuesday, July 11, 2017 - link
I'am a brazilian processors enthusiast and I'am very critic about intel and AMD processors, between 2012 and Q1 2017 AMD just doesn't existed, who bought AMD on that years, bougth just for love AMD and just it, doesn't for the price, doesn't for the high core count, doesn't for AMD is red, AMD was the worst performance processors. The A9 Apple dual core performance is better than FX 8150.But now I am very surprise with the aggressive AMD prices. No one here Imagined get the Ryzen 7 performance for less than $500. And I don't know if this scenario brings profit to AMD, but for the image against the intel it's wonderful.
On the next years we will see.
krumme - Tuesday, July 11, 2017 - link
Thank you for quality stuff article especially given the short time. So thank you for booting up Johan !Interesting and surpricing results.