Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
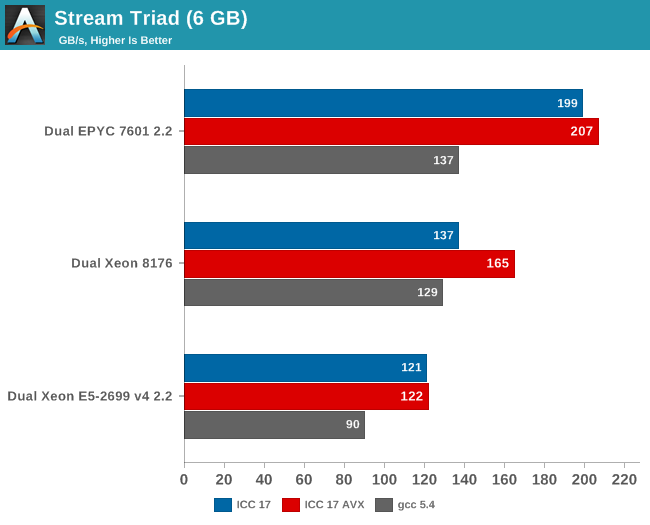
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
extide - Tuesday, July 11, 2017 - link
PCPer made this same mistake -- Nehalem/Westmere used a crossbar memory bus -- not a ringbus. Only Nehalem/Westmere EX used the ringbus (the 6500/7500 series) The i7 and Xeon 5500 and 5600 series used the crossbar.extide - Tuesday, July 11, 2017 - link
Sandy Bridge brought the ringbus down to Xeon EP and client chips.Yorgos - Tuesday, July 11, 2017 - link
"With the complexity of both server hardware and especially server software, that is very little time. There is still a lot to test and tune, but the general picture is clear."No wonder why we see ubuntu and ancient versions of gcc and the rest of the s/w stack.
Imagine if you tried to use debian or rhel, it would take you decades to get the review.
eligrey - Tuesday, July 11, 2017 - link
Why did you omit the Turbo frequencies for the Xeon Gold 6146 and 6144?Intel ARK says that the 6146's turbo frequency is 4.2GHz and the 6144's is 4.5GHz.
eligrey - Tuesday, July 11, 2017 - link
Oops, I mean 4.2GHz for both.boozed - Tuesday, July 11, 2017 - link
Need more Skylake-SP SKUsrHardware - Tuesday, July 11, 2017 - link
For the purley system, It's listed that you used Chipset Intel Wellsburg B0This information cannot be correct. Lewisburg Chipset is the name of the purley chipset. Also, B0 stepping lewisburg also wouldn't boot with the stepping of CPU you have.
rHardware - Tuesday, July 11, 2017 - link
That 0200011 microcode is also very old.Rickyxds - Tuesday, July 11, 2017 - link
I'am a brazilian processors enthusiast and I'am very critic about intel and AMD processors, between 2012 and Q1 2017 AMD just doesn't existed, who bought AMD on that years, bougth just for love AMD and just it, doesn't for the price, doesn't for the high core count, doesn't for AMD is red, AMD was the worst performance processors. The A9 Apple dual core performance is better than FX 8150.But now I am very surprise with the aggressive AMD prices. No one here Imagined get the Ryzen 7 performance for less than $500. And I don't know if this scenario brings profit to AMD, but for the image against the intel it's wonderful.
On the next years we will see.
krumme - Tuesday, July 11, 2017 - link
Thank you for quality stuff article especially given the short time. So thank you for booting up Johan !Interesting and surpricing results.