Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
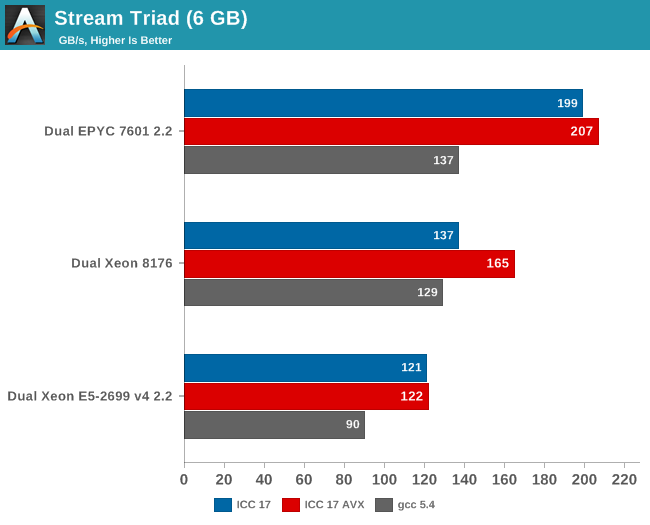
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
Shankar1962 - Wednesday, July 12, 2017 - link
AMD is fooling everyone one by showing more cores, pci lanes, security etcCan someone explain me why GOOGLE ATT AWS ALIBABA etc upgraded to sky lake when AMD IS SUPERIOR FOR HALF THE PRICE?
Shankar1962 - Wednesday, July 12, 2017 - link
Sorry its BaiduPretty sure Alibaba will upgrade
https://www.google.com/amp/s/seekingalpha.com/amp/...
PixyMisa - Thursday, July 13, 2017 - link
Lots of reasons.1. Epyc is brand new. You can bet that every major server customer has it in testing, but it could easily be a year before they're ready to deploy.
2. Functions like ESXi hot migration may not be supported on Epyc yet, and certainly not between Epyc and Intel.
3. Those companies don't pay the same prices we do. Amazon have customised CPUs for AWS - not a different die, but a particular spec that isn't on Intel's product list.
There's no trick here. This is what AMD did before, back in 2006.
blublub - Tuesday, July 11, 2017 - link
I kinda miss Infinity Fabric on my Haswell CPU and it seems to only have on die - so why is that missing on Haswell wehen Ryzen is an exact copy?blublub - Tuesday, July 11, 2017 - link
argh that post did get lost.zappor - Tuesday, July 11, 2017 - link
4.4.0 kernel?! That's not good for single-die Zen and must be even worse for Epyc!AMD's Ryzen Will Really Like A Newer Linux Kernel:
https://www.phoronix.com/scan.php?page=news_item&a...
Kernel 4.10 gives Linux support for AMD Ryzen multithreading:
http://www.pcworld.com/article/3176323/linux/kerne...
JohanAnandtech - Friday, July 21, 2017 - link
We will update to a more updated kernel once the hardware update for 16.04 LTS is available. Should be August according to Ubuntukwalker - Tuesday, July 11, 2017 - link
You mention an OpenFOAM benchmark when talking about the new mesh topology but it wasn't included in the article. Any way you could post that? We are trying to evaluate EPYC vs Skylake for CFD applications.JohanAnandtech - Friday, July 21, 2017 - link
Any suggestion on a good OpenFoam benchmark that is available? Our realworld example is not compatible with the latest OpenFoam versions. Just send me an e-mail, if you can assist.Lolimaster - Tuesday, July 11, 2017 - link
AMD's lego design where basically every CCX can be used in whatever config they want be either consumer/HEDT or server is superior in the multicore era.Cheaper to produce, cheaper to sell, huge profits.