Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
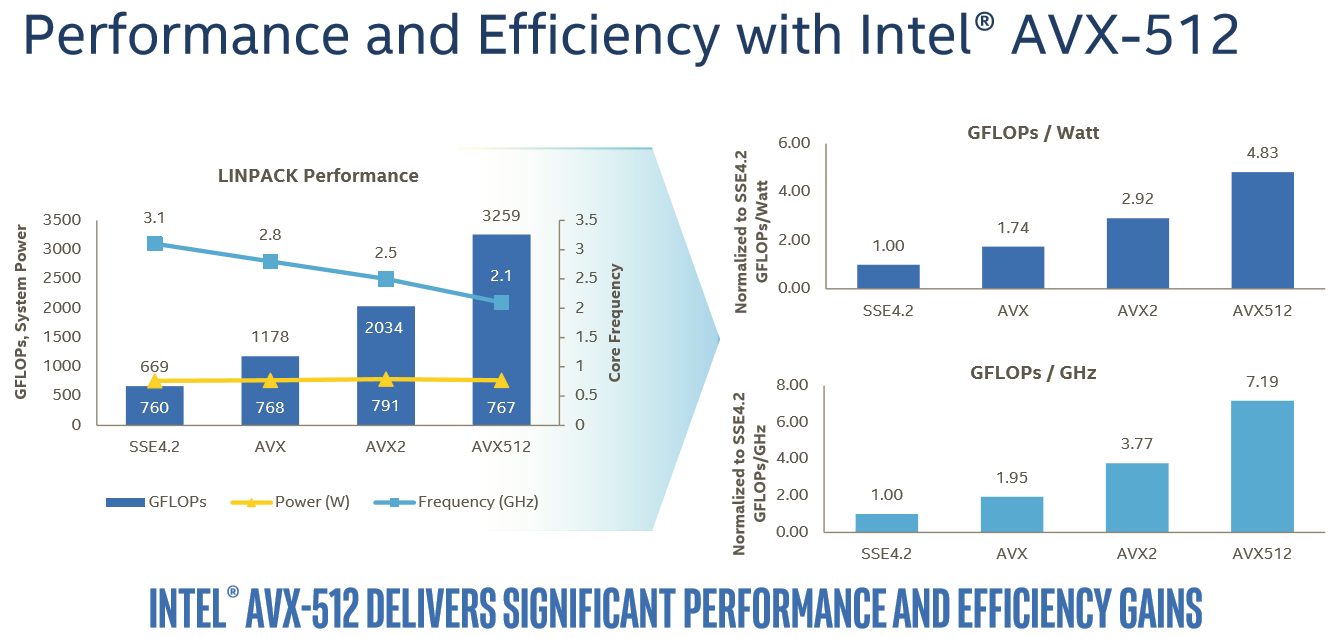
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
alpha754293 - Tuesday, July 11, 2017 - link
Pity that OpenFOAM failed to run on Ubuntu 16.04.2 LTS. I would have been very interested in those results.farmergann - Tuesday, July 11, 2017 - link
Are you trying to hide the fact that AMD's performance per watt absolutely dominates intel's, or have you simply overlooked one of, if not the, single most important aspects of server processors?Ryan Smith - Tuesday, July 11, 2017 - link
Neither. We just had very little time to look at power consumption. It's also the metric we're the least confident in right now, as we'd like to have a better understanding of the quirks of the platform (which again takes more time).Carl Bicknell - Wednesday, July 12, 2017 - link
Ryan / Ian,Just to let you know there are better chess benchmarks than the one you've chosen. Stockfish is an example of a newer program which better uses modern CPU architecture.
NixZero - Tuesday, July 11, 2017 - link
"AMD's MCM approach is much cheaper to manufacture. Peak memory bandwidth and capacity is quite a bit higher with 4 dies and 2 memory channels per die. However, there is no central last level cache that can perform low latency data coordination between the L2-caches of the different cores (except inside one CCX). The eight 8 MB L3-caches acts like - relatively low latency - spill over caches for the 32 L2-caches on one chip. "isnt skylake-x's l3 a victim cache too? and divided at 1.3mb for each core, not a monolytic one?
Ian Cutress - Tuesday, July 11, 2017 - link
That's what a 'spill-over' cache is - it accepts evicted cache lines.NixZero - Wednesday, July 12, 2017 - link
so why its put as an advantage for intel cache, which is spill over too?JonathanWoodruff - Wednesday, July 12, 2017 - link
Since the Intel one is all on one die, a miss to a "slice" of cache can be filled without DRAM-like latencies from another slice. Since AMD has it's last level caches spread across dies, going to another cache looks to be equivalent latency-wise to going to DRAM. It wouldn't necessarily have to be quite that bad, and I would expect some improvement here for Zen2.Martin_Schou - Tuesday, July 11, 2017 - link
This has to be wrong:CPU Two EPYC 7601 (2.2 GHz, 32c, 8x8MB L3, 180W)
RAM 512 GB (12x32 GB) Samsung DDR4-2666 @2400
12 x 32 GB is 384 GB, and 12 sticks doesn't fit nicely into 8 channels. In all likelihood that's supposed to be 16x32 GB, as we see in the E52690
Dr.Neale - Tuesday, July 11, 2017 - link
I find myself puzzled by the curious omission in this article of a key aspect of Server architecture: Data Security.AMD has a LOT; Intel, not so much.
I would think this aspect of Server "Performance" would be a major consideration in choosing which company's Architecture to deploy in a Secure Server scenario. Especially in light of Recent Revelations fuelling Hacking Headlines in the news, and Dominating Discussions on various social media websites.
How much is Data Security worth?
A topic of EPYC consequence!