Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
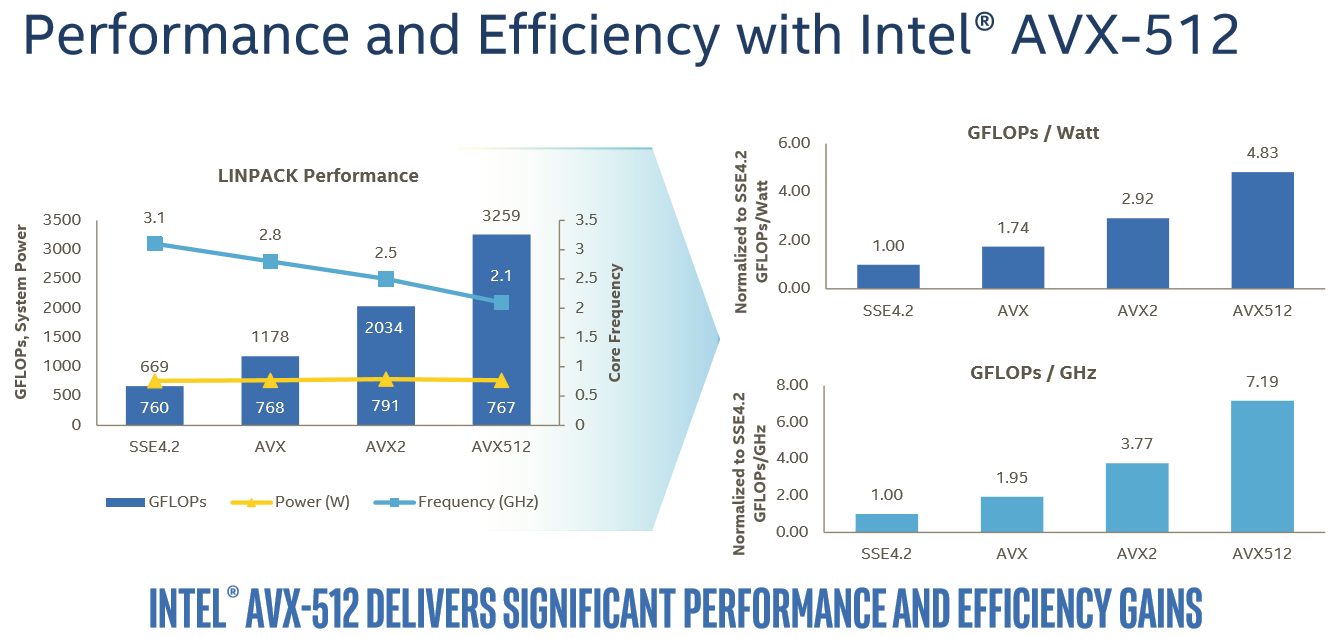
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
PixyMisa - Tuesday, July 11, 2017 - link
No, the pricing is correct. The 1P CPUs really are half the price of a single 2P CPU.msroadkill612 - Wednesday, July 12, 2017 - link
Seems to me, the simplest explanation of something complex, is to list what it will not do, which they will not do :(.Can i run a 1p Epyc in a 2p mobo e.g., please?
PixyMisa - Thursday, July 13, 2017 - link
Short answer is no. It might boot, but only half the slots, memory, SATA and so on will be available. Two 1P CPUs won't talk to each other.A 2P Epyc will work in a 1P board though.
cekim - Tuesday, July 11, 2017 - link
One glaring bug/feature of AMD's segmentation relative to Intel's is the utter and obvious crippling of clock speeds for all but the absolute top SKUs. Fewer cores should be able to make use of higher clocks within the same TDP envelope. As a result Intel is objectively offering more and better fits up and down the sweep of cores vs clocks vs price spectrum.So, the bottom line is AMD is saying that you will have to buy the top-end, 4S SKU to get the top GHz for those applications in your mix that won't benefit from 16,18,32,128 cores.
I say all of this as someone who desperately wants EPYC to shake things up and force Intel to remove the sand-bags. I know I'm in a small, but non-zero market of users who can make use of dozens of cores, but still need 8 or fewer cores to perform on par with desktop parts for that purpose.
KAlmquist - Wednesday, July 12, 2017 - link
One possibility is that they have only a small percentage of the chips currently being produced bin well enough to be used in the highest clocking SKU's, so they are saving those chips for the most expensive offerings. Admittedly, that depends on what they are seeing coming off the production line. If they have a fair number of chips where with two very good cores, and two not so good, then it would make sense to offer a high clocking 16 core EPYC using chips with two cores disabled. But if clock speed on most chips is limited due to minor registration errors (which would affect the entire chip), then a chip with only two really good cores would require two localized defects in two separate cores, in addition to very good registration to get the two good cores. The combination might be too rare to justify a separate SKU.I would expect Global Foundries to continue to tweak its process to get better yields. In that case, more processors would end up in the highest bin, and AMD might decide to launch a higher clock speed 16 and 8 core EPYC processors, mostly using chips which bin well enough that they could have been used for the 32 core EPYC 7601.
alpha754293 - Tuesday, July 11, 2017 - link
Why does the Intel Xeon 6142 cost LESS than the 6142M? (e.g. per the table above, 6142 is shown with a price of $5946 while the 6142M costs $2949)ca197 - Tuesday, July 11, 2017 - link
I assume that is the wrong way round on the list. I have seen it reported the other way round on other sites.Ian Cutress - Tuesday, July 11, 2017 - link
You're correct. I've updated the piece, was a misread error from Intel's tables.coder543 - Tuesday, July 11, 2017 - link
On page 6, it says that Epyc only has 64 PCIe lanes (available), but that's not correct. There are 128 PCIe lanes per chip. In a 1P configuration, that's 128 PCIe lanes available. On a 2P configuration, 64 PCIe lanes from each chip are used to connect to the other chip, leaving 64 + 64 = 128 PCIe lanes still available.This is a significant advantage.
Ian Cutress - Tuesday, July 11, 2017 - link
You misread that table. It's quoting per-CPU when in a 2P configuration.