The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTThe Core Complex, Caches, and Fabric
Many core designs often start with an initial low-core-count building block that is repeated across a coherent fabric to generate a large number of cores and the large die. In this case, AMD is using a CPU Complex (CCX) as that building block which consists of four cores and the associated caches.
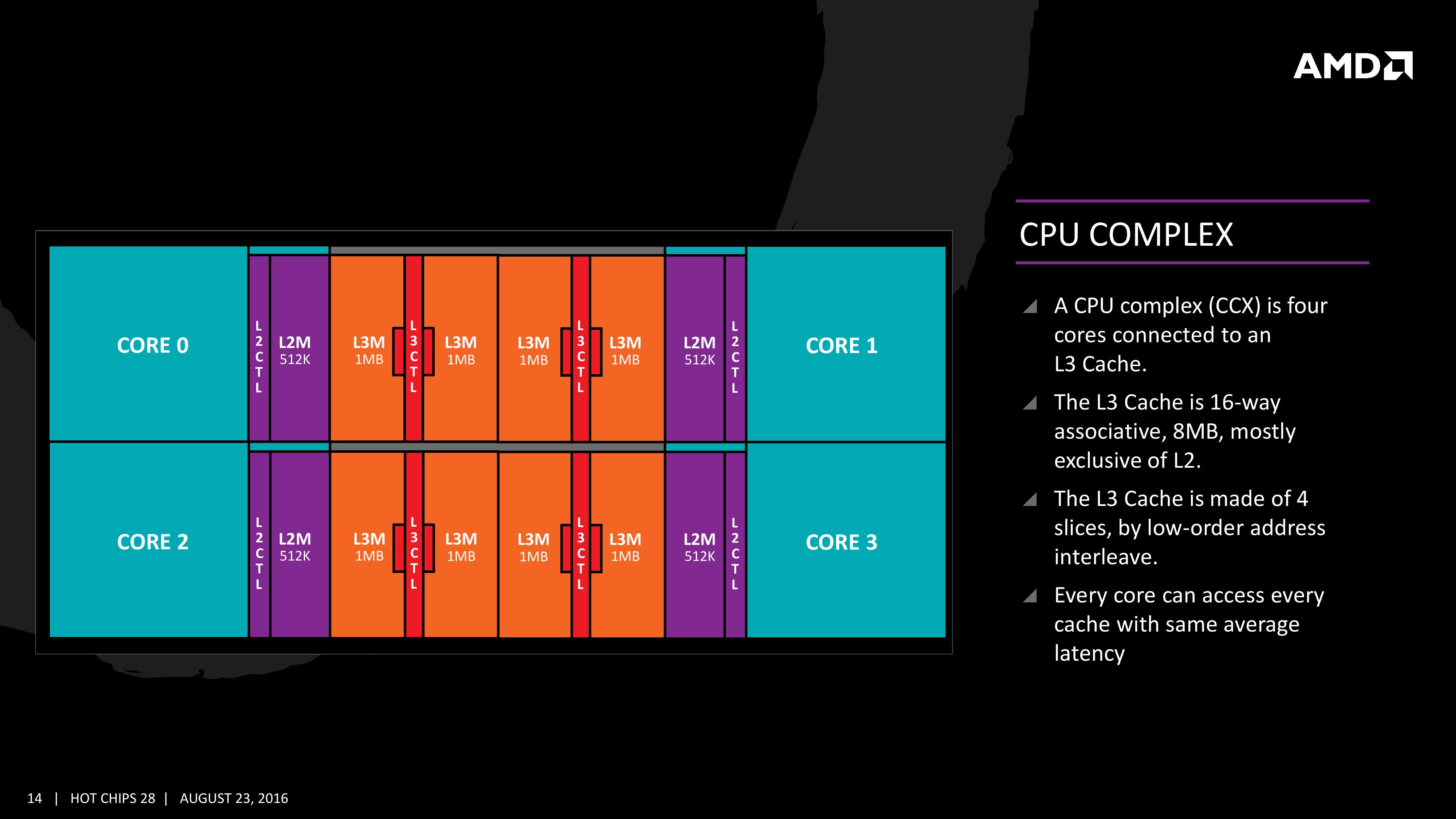
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
The L3 cache is actually a victim cache, taking data from L1 and L2 evictions rather than collecting data from prefetch/demand instructions. Victim caches tend to be less effective than inclusive caches, however Zen counters this by having a sufficiency large L2 to compensate. The use of a victim cache means that it does not have to hold L2 data inside, effectively increasing its potential capacity with less data redundancy.
It is worth noting that a single CCX has 8 MB of cache, and as a result the 8-core Zen being displayed by AMD at the current events involves two CPU Complexes. This affords a total of 16 MB of L3 cache, albeit in two distinct parts. This means that the true LLC for the entire chip is actually DRAM, although AMD states that the two CCXes can communicate with each other through the custom fabric which connects both the complexes, the memory controller, the IO, the PCIe lanes etc.
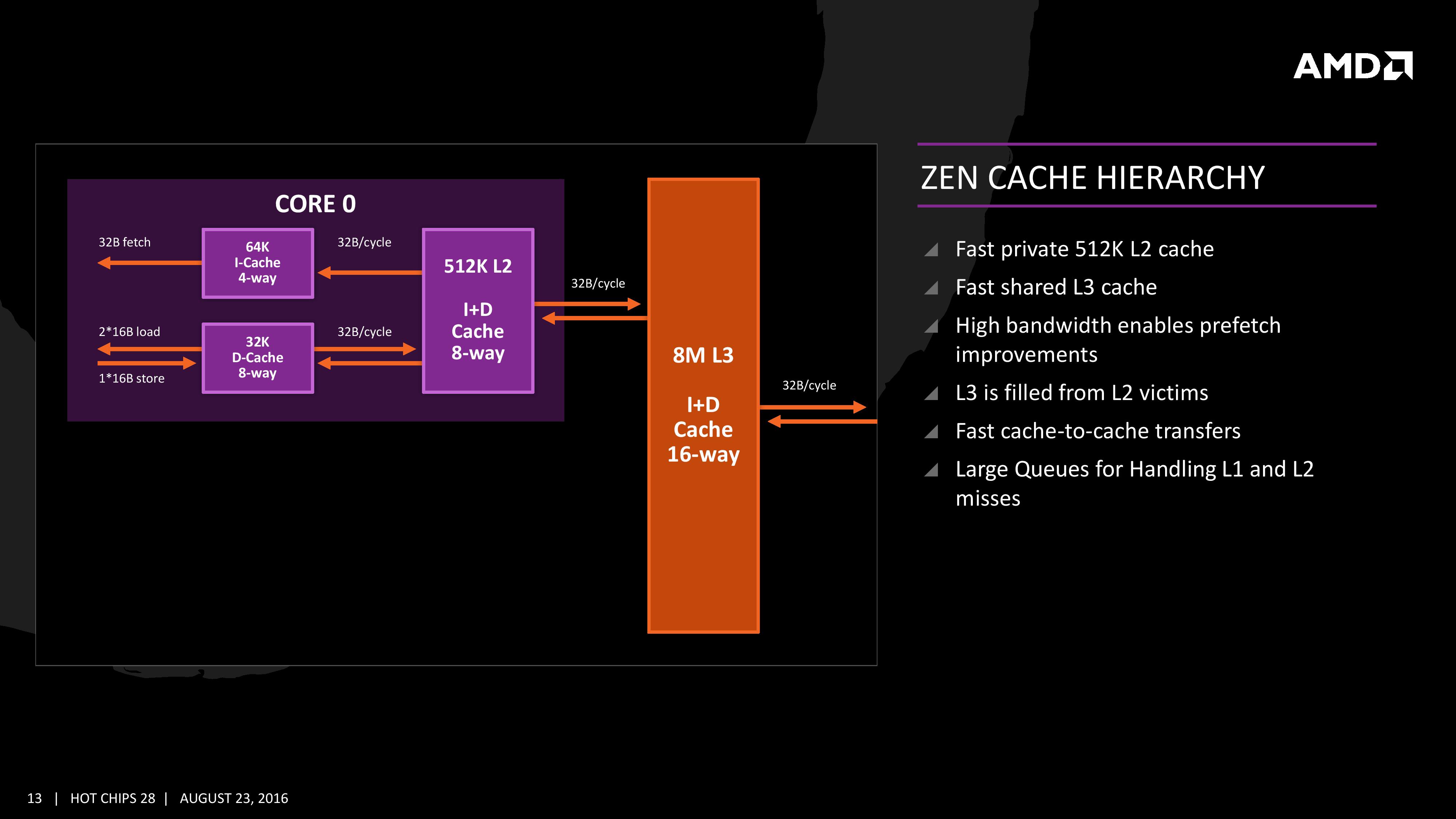
The cache representation shows L1 and L2 being local to each the core, followed by 8MB of L3 split over several cores. AMD states that the L1 and L2 bandwidth is nearly double that of Excavator, with L3 now up to 5x for bandwidth, and that this bandwidth will help drive the improvements made on the prefetch side. AMD also states that there are large queues in play for L1/L2 cache misses.

One interesting story is going to be how AMD’s coherent fabric works. For those that follow mobile phone SoCs, we know fabrics and interconnects such as CCI-400 or the CCN family are optimized to take advantage of core clusters along with the rest of the chip. A number of people have speculated that the fabric used in AMD’s new design is based on HyperTransport, however AMD has confirmed that they are using a superset HyperTransport here for Zen, and that the Infinity fabric design is meant to be high bandwidth, low latency, and be in both Zen and Vega as well as future products. Almost similar to the CPU/GPU roadmaps, the Fabric has its own as well.
Ultimately the new fabric involves a series of control and data passing structures, with the data passing enabling third-party IP in custom designs, a high-performance common bus for large multi-unit (CPU/GPU) structures, and socket to socket communication. The control elements are an extension of power management, enabling parts of the fabric to duty cycle when not in use, security by way of memory management and detection, and test/initialization for activities such as data prefetch.








574 Comments
View All Comments
theuglyman0war - Saturday, March 4, 2017 - link
I'd like to see a lot more older i7 extreme editions covered all the way to westmere so I can sell clients on new builds with such a comparison.mapesdhs - Sunday, March 5, 2017 - link
Which older i7s interest you specifically?theuglyman0war - Saturday, March 4, 2017 - link
Checking what I paid last month for i7-7700k at Microcenter...Although I did get the motherboard combo price sale they "usually" offer...
The supposed $60 off for $319 is the cheapest price I found with a quick survey of new egg, amazon etc... And only $20 less then what I paid! Hardly A slashed priced answer shot across the bow by Intel! Not by a long shot!
I thought I was going to recommend the new cheap price to all my customer's new builds but I am pushing RYZEN and AM4 for a real combined price that makes a difference. ( the cheap price for enthusiast Am4 is enticing but the loss of PCI lanes is of concern for extreme cpu comparison anyway. Not so much compared to i7-7700k though which brings the comparison back to 16 lane parity! )
theuglyman0war - Saturday, March 4, 2017 - link
Could anyone actually point me to the amazing slashed deals that "BEAT" what I couldn't get last month by a long shot?( which was $349 BEFORE rebate. In other words it's not like there were not sales last month as well. And I see nothing now that really amounts to AMAZING compared to last month? )
Pretty dam insulting from somewhere in the pipe? Not sure if it's Intel. Or it's resellers clinging on to greedy margins not reflecting the savings to save their own ass's and bottom line due to stock considerations? Which iz no excuse considering the writing was on the wall. Someone needs to do a lot better. A heck of a lot better. Particularly considering I was thinking I could jes laff off AMD with an Intel savings and now have egg on my face! :)
rpns - Saturday, March 4, 2017 - link
The 'Test Bed Setup' section could do with some more details. E.g. what BIOS version? Windows 10 build version? Any notable driver versions?These details aren't useful just now, but also when looking back at the review a few months down the line.
jorkevyn - Saturday, March 4, 2017 - link
why they don't get 4 channel for DDR4 memory? I think, if you get that you will may be the real I7 6950K Killersedra - Saturday, March 4, 2017 - link
have a look at this:"Many software programmers consider Intel's compiler the best optimizing compiler on the market, and it is often the preferred compiler for the most critical applications. Likewise, Intel is supplying a lot of highly optimized function libraries for many different technical and scientific applications. In many cases, there are no good alternatives to Intel's function libraries.
Unfortunately, software compiled with the Intel compiler or the Intel function libraries has inferior performance on AMD and VIA processors. The reason is that the compiler or library can make multiple versions of a piece of code, each optimized for a certain processor and instruction set, for example SSE2, SSE3, etc. The system includes a function that detects which type of CPU it is running on and chooses the optimal code path for that CPU. This is called a CPU dispatcher. However, the Intel CPU dispatcher does not only check which instruction set is supported by the CPU, it also checks the vendor ID string. If the vendor string says "GenuineIntel" then it uses the optimal code path. If the CPU is not from Intel then, in most cases, it will run the slowest possible version of the code, even if the CPU is fully compatible with a better version."
http://www.agner.org/optimize/blog/read.php?i=49&a...
HomeworldFound - Saturday, March 4, 2017 - link
Everyone here already knew that ten years ago.Notmyusualid - Sunday, March 5, 2017 - link
Indeed it was.sedra - Sunday, March 5, 2017 - link
it is worth to bring it up now.