The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTZen: New Core Features
Since August, AMD has been slowly releasing microarchitecture details about Zen. Initially it started with a formal disclosure during Intel’s annual developer event, the followed a paper at HotChips, some more details at the ‘New Horizon’ event in December, and recently a talk at ISSCC. The Zen Tech Day just before launch gave a chance to get some of those questions answered.
First up, let’s dive right in to the high-level block diagram:
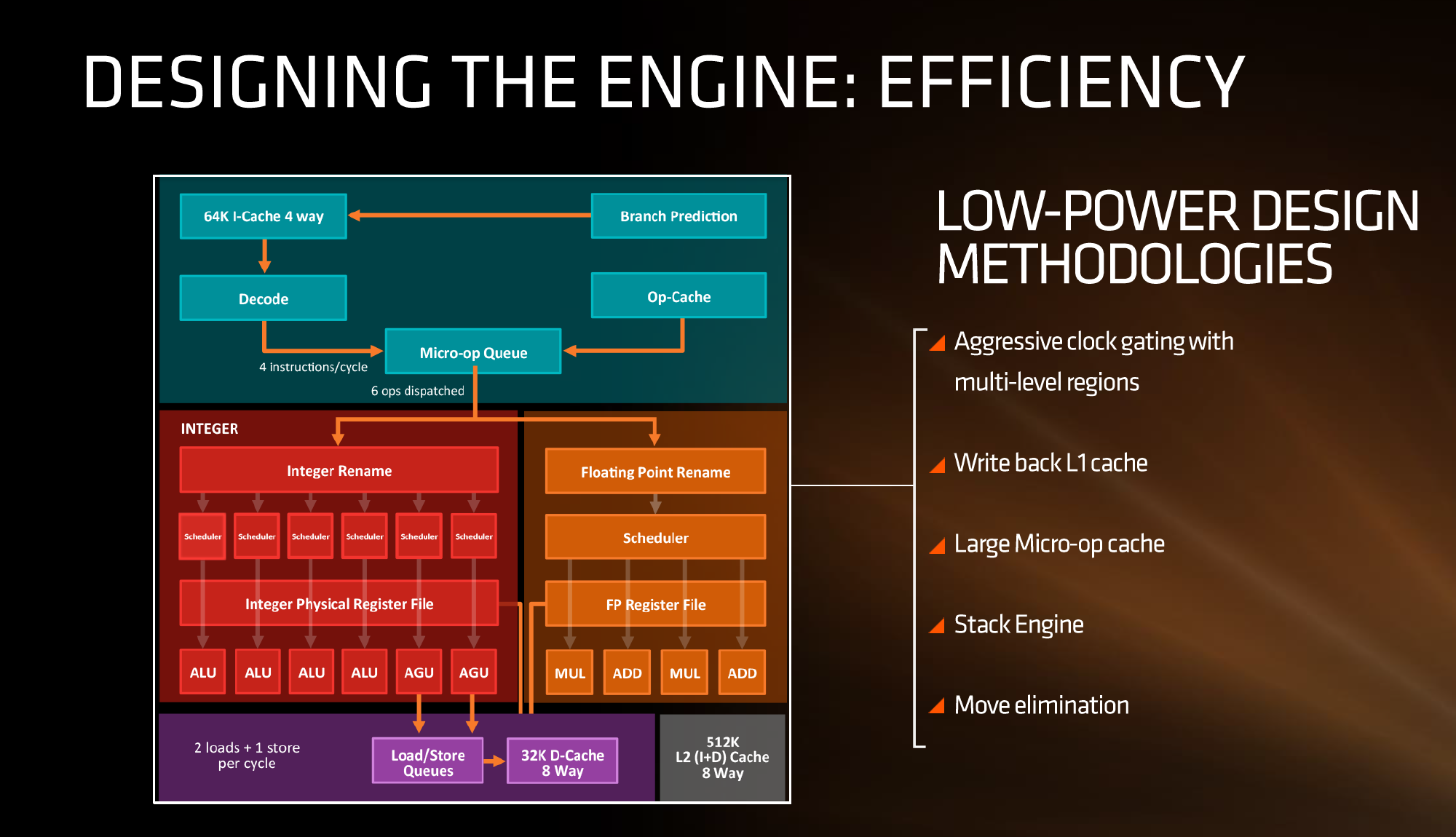
In this diagram, the core is split into the ‘front-end’ in blue and the rest of the core is the ‘back-end’. The front-end is where instructions come into the core, branch predictors are activated and instructions are decoded into micro-ops (micro-operations) before being placed into a micro-op queue. In red is the part of the back-end that deals with integer (INT) based instructions, such as integer math, loops, loads and stores. In orange is the floating-point (FP) part of the back-end, typically focused on different forms of math compute. Both the INT and FP segments have their own separate execution port schedulers
If it looks somewhat similar to other high-performance CPU cores, you’d be correct: there seems to be a high-level way of ‘doing things’ when it comes to x86, with three levels of cache, multi-level TLBs, instruction coalescing, a set of decoders that dispatch a combined 4-5+ micro-ops per cycle, a very large micro-op queue (150+), shared retire resources, AVX support, and simultaneous hyper-threading.
What’s New to AMD
First up, and the most important, was the inclusion of the micro-op cache. This allows for instructions that were recently used to be called up to the micro-op queue rather than being decoded again, and saves a trip through the core and caches. Typically micro-op caches are still relatively small: Intel’s version can support 1536 uOps with 8-way associativity. We learned (after much asking) at AMD’s Tech Day that the micro-op cache for Zen can support ‘2K’ (aka 2048) micro-ops with up to 8-ops per cache line. This is good for AMD, although I conversed with Mike Clark on this: if AMD had said ‘512’, on one hand I’d be asking why it is so small, and on the other wondering if they would have done something different to account for the performance adjustments. But ‘2K’ fits in with what we would expect.
Secondly is the cache structure. We were given details for the L1, L2 and L3 cache sizes, along with associativity, to compare it to former microarchitectures as well as Intel’s offering.
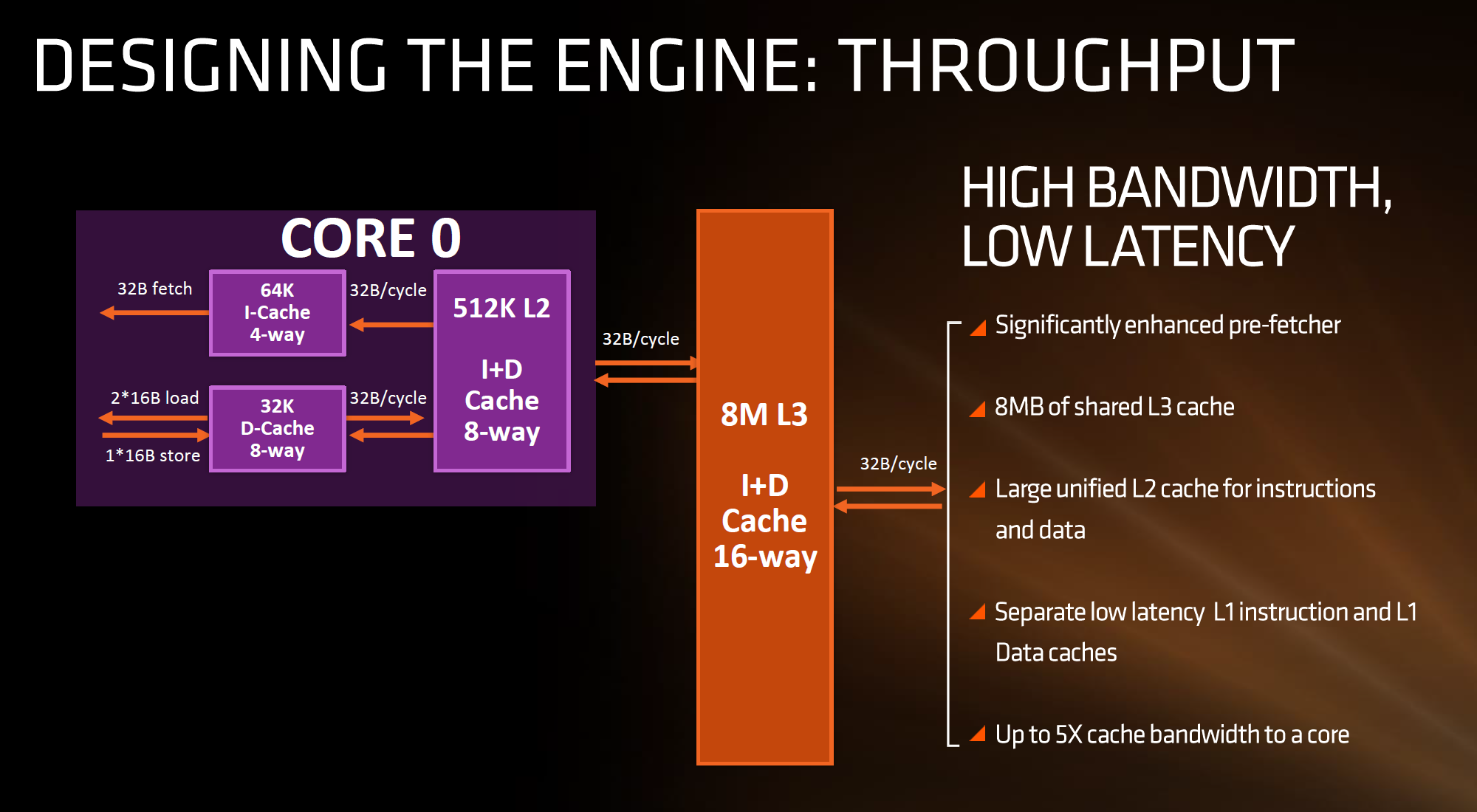
In this case, AMD has given Zen a 64KB L1 Instruction cache per core with 4-way associativity, with a lop-sided 32KB L1 Data cache per core with 8-way associativity. The size and accessibility determines how frequently a cache line is missed, and it is typically a trade-off for die area and power (larger caches require more die area, more associativity usually costs power). The instruction cache, per cycle, can afford a 32byte fetch while the data cache allows for 2x 16-byte loads and one 16-byte store per cycle. AMD stated that allowing two D-cache loads per cycle is more representative of the most workloads that end up with more loads than stores.
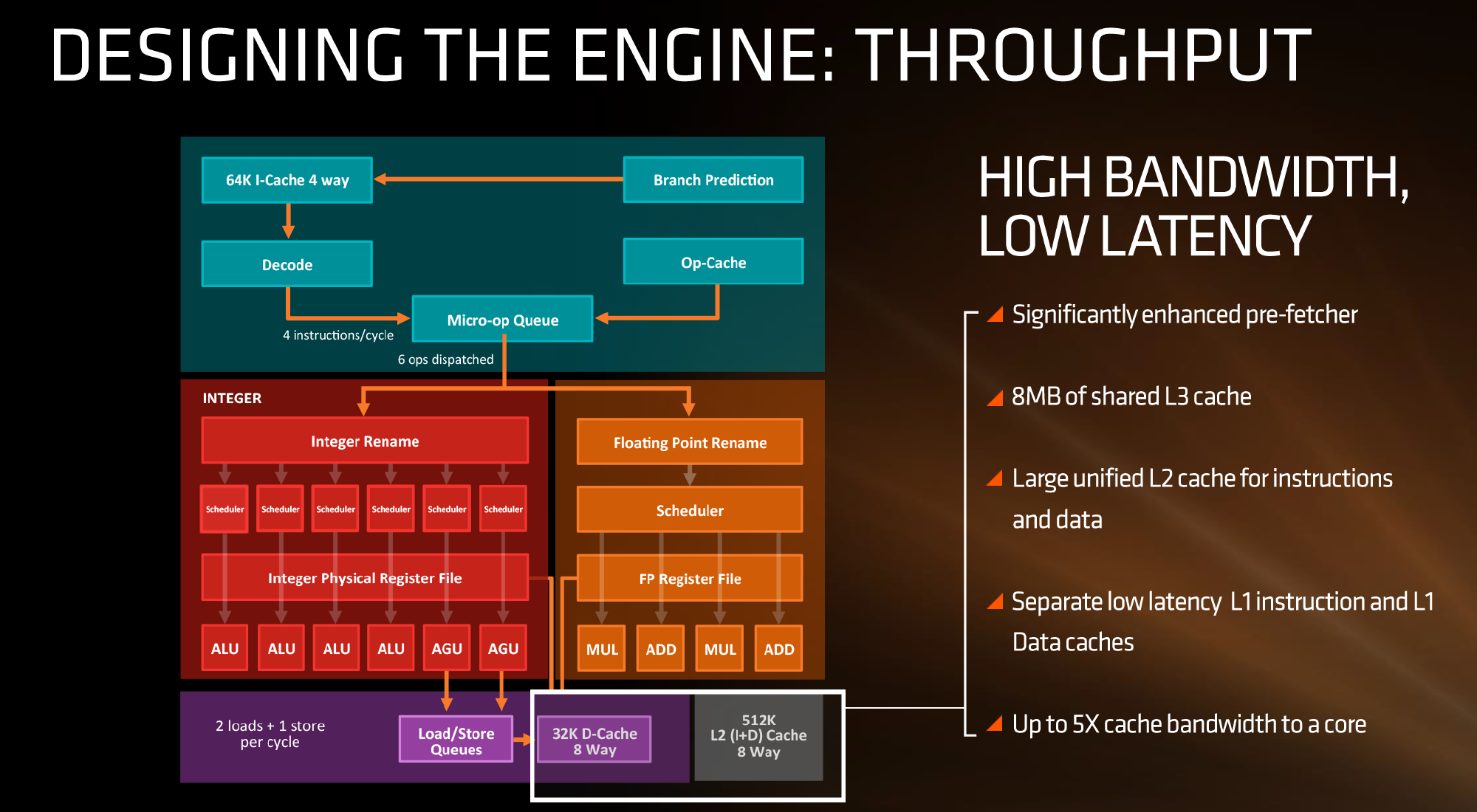
The L2 is a large 512 KB, 8-way cache per core. This is double the size of Intel’s 256 KB 4-way cache in Skylake or 256 KB 8-way cache in Broadwell. Typically doubling the cache size affords a 1.414 (square root of 2) better chance of a cache hit, reducing the need to go further out to find data, but comes at the expense of die area. This will have a big impact on a lot of performance metrics, and AMD is promoting faster cache-to-cache transfers than previous generations. Both the L1 and L2 caches are write-back caches, improving over the L1 write-through cache in Bulldozer.
The L3 cache is an 8MB 16-way cache, although at the time last week it was not specified over how many cores this was. From the data release today, we can confirm rumors that this 8 MB cache is split over a four-core module, affording 2 MB of L3 cache per core or 16 MB of L3 cache for the whole 8-core Zen CPU. These two 8 MB caches are separate, so act as a last-level cache per 4-core module with the appropriate hooks into the other L3 to determine if data is needed. As part of the talk today we also learned that the L3 is a pure victim cache for L1/L2 victims, rather than a cache for prefetch/demand data, which tempers the expectations a little but the large L2 will make up for this. We’ll discuss it as part of today’s announcement.
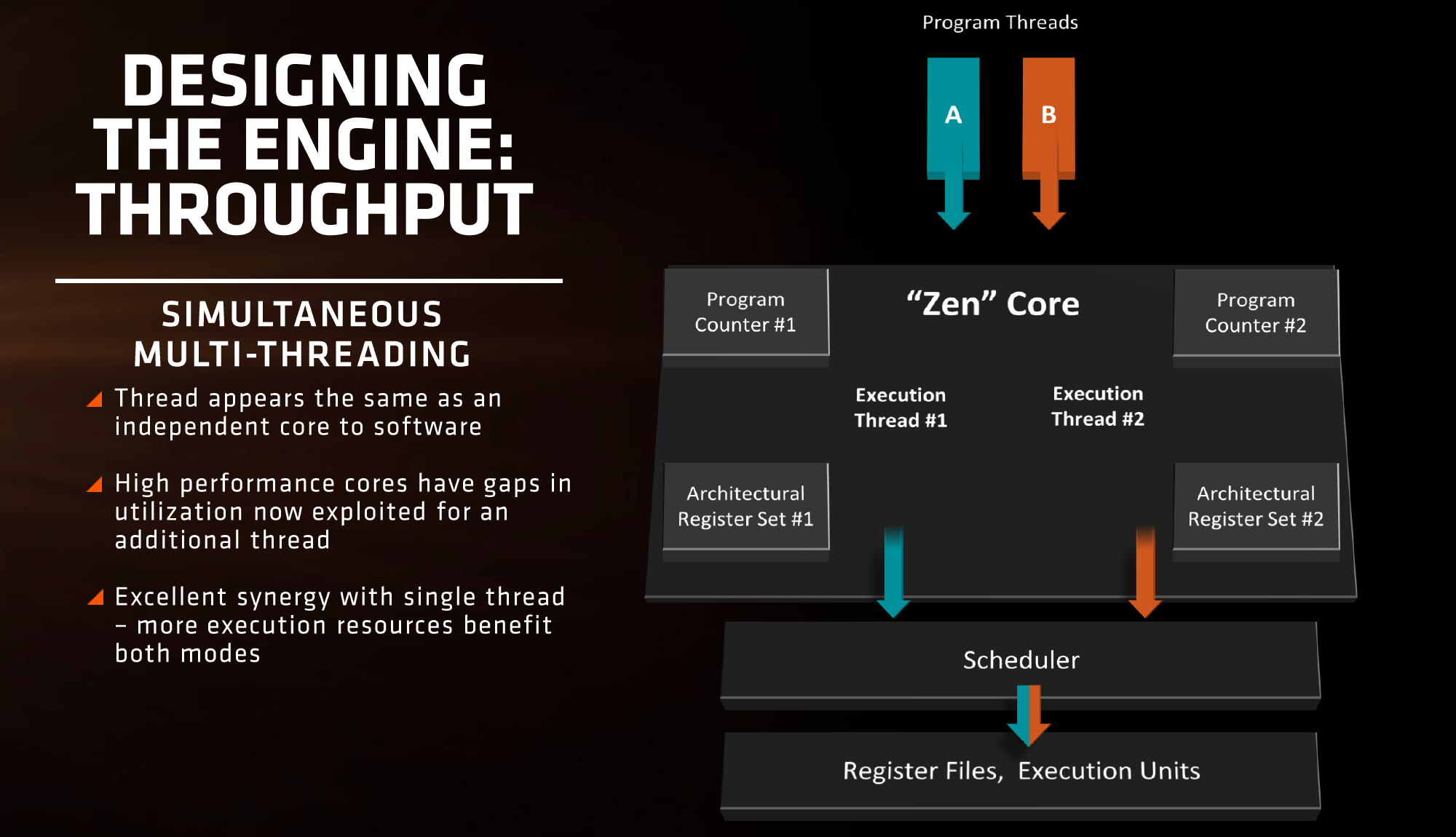
AMD is also playing with SMT, or simultaneous multi-threading. We’ve covered this with Intel extensively, under the heading ‘HyperThreading’. At a high level both these terms are essentially saying the same thing, although their implementations may differ. Adding SMT to a core design has the potential to increase throughput by allowing a second thread (or third, or fourth, or like IBM up to eight) on the same core to have the same access to execution ports, queues and caches. However SMT requires hardware level support – not all structures can be dynamically shared between threads and can either be algorithmically partitioned (prefetch), statically partitioned (micro-op queue) or used in alternate cycles (retire queue).
We also have dual schedulers, one for INT and another for FP, which is different to Intel’s joint scheduler/buffer implementation.








574 Comments
View All Comments
deltaFx2 - Wednesday, March 8, 2017 - link
@Meteor2: No. Consumer GPUs have poor throughput for Double precision FP. So you can't push those to the GPU (unless you own those super-expensive Nvidia compute cards). Apparently, many rendering/video editing programs use GPUs for preview but do the final rendering on CPU. Quality, apparently, and might be related to DP FP. I'm not the expert, so if you know otherwise, I'd be happy to be corrected and educated. Also, you could make the same argument about AVX-256.The quoted paragraph is probably the only balanced statement in that entire review. Compare the tone of that review with AT review above.
On an unrelated note, there's the larger question of running games at low res on top-end gpus and comparing frame-rates that far exceed human perception. I know, they have to do something, so why not just do this. The rationale is: " In future a faster GPU in future will create a bottleneck ". If this is true, it should be easy to demonstrate, right? Just dig through a history of Intel desktop CPUs paired with increasingly powerful GPUs and see how it trends. There's not one reviewer that has proven that this is true. It's being taken as gospel. OTOH, plenty of folks seem happy with their Sandy Bridge + Nvidia 1080, so clearly the bottleneck isn't here 5 years after SB. Maybe, just maybe, it's because the differences are imperceptible?
Ryzen clearly has some bottlenecks but the whole gaming thing is a tempest in a tea-cup.
theuglyman0war - Thursday, March 9, 2017 - link
ZBRUSHprobably 90% of all 3d assets that are created from concept ( NOT SCANNED )
Went through Zbrush at some point.
Which means no GPU acceleration at all.
Renderman
Maxwell
Vray
Arnold
still all use CPU rendering As do a mountain of other renderers.
Arnold will be getting an option
But the two popular GPU renderers are Otoy Octane and Redshift...
The have their excellent expensive place. But the majority of rendering out there is still suffered through software rendering. And will always be a valid concern as long as they come FREE built into major DCC applications.
theuglyman0war - Thursday, March 9, 2017 - link
Saw that same GPU trumps CPU render validity concerns...Comment and had a good laugh.
I'll remember to spread that around every time I see Renderman Vray Arnold Maxwell sans GPU rendering going on.
Or the next time a Mercury engine update negates all non Quadro GPU acceleration.
To be fair a lot of creative pros and tech artists seem to disagree with me but...
The only time between pulling vrts in Maya and brushing a surface in Zbrush that I really feel that I am suffering buckets of tears and desire a new CPU ( still on i7-980x ) is when I am cussing out a progress bar that is teasing me with it's slow progress. And that means CORES! encoding... un compressing... Rendering! Otherwise I could probably not notice day to day on a ten year old CPU. ( excluding CPU bound gaming of course... talking bout day to day vrt pulling )
I was just as productive in 2007 as I am today.
MaidoMaido - Saturday, March 4, 2017 - link
Been trying to find a review including practical benchmarks for common video editing / motion graphics applications like After Effects, Resolve, Fusion, Premiere, Element 3D.In a lot of these tasks, the multithreading is not always the best, as a result quad core 6700K often outperforms the more expensive Xeon and 5960X etc
deltaFx2 - Saturday, March 4, 2017 - link
I would recommend this response to the GamersNexus hit piece: https://www.reddit.com/r/Amd/comments/5xgonu/analy...The i5 level performance is a lie.
Notmyusualid - Saturday, March 4, 2017 - link
@ deltaFx2Sorry, not reading a 4k worded response. I'll wait for Anand to finish its Ryzen reviews before I draw any final conclusions.
Meteor2 - Tuesday, March 7, 2017 - link
@deltaFX2 RE: in the 4k word Reddit 'rebuttal', what that person seems to be saying, is that once you've converted your $500 Ryzen 1800X into a 8C/8T chip, _then_ it beats a $240 i5, while still falling short of the $330 i7. Out-of-the-box, it has worse gaming performance than either Intel chip.That's not exactly a ringing endorsement.
The analysis in the Anandtech forums, which concludes that in a certain narrow and low power band a heavily down-clocked 1800X happens to get excellent performance/W, isn't exactly thrilling either.
deltaFx2 - Wednesday, March 8, 2017 - link
@ Meteor2: The anandtech forum thing: Perf/watt matters for servers and laptop. Take a look at the IPC numbers too. His average is that Zen == Broadwell IPC, and ~10% behind Sky/Kaby lake (except for AVX256 workloads). That's not too shabby at all for a $300 part.You completely missed the point of the reddit rebuttal. The GN reviewer drops i5s from plenty of tests citing "methodological reasons", but then says R7==i5 in gaming. The argument is that plenty of games use >4 threads and that puts i5 at a disadvantage.
tankNZ - Sunday, March 5, 2017 - link
yes I agree, it's even better than okay for gaming[img]http://smsh.me/li3a.png[/img]deltaFx2 - Monday, March 6, 2017 - link
You may wish to see this though: https://forums.anandtech.com/threads/ryzen-strictl... Way, way, more detailed than any tech media review site can hope to get. No, it's got nothing to do with gaming. Gaming isn't the story here. AMD's current situation in x86 market share had little to do with gaming efficiency, but perf/watt.I'll quote the author: "850 points in Cinebench 15 at 30W is quite telling. Or not telling, but absolutely massive. Zeppelin can reach absolutely monstrous and unseen levels of efficiency, as long as it operates within its ideal frequency range."