AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Simultaneous MultiThreading (SMT)
Zen will be AMD’s first foray into a true simultaneous multithreading structure, and certain parts of the core will act differently depending on their implementation. There are many ways to manage threads, particularly to avoid stalls where one thread is blocking another that ends in the system hanging or crashing. The drivers that communicate with the OS also have to make sure they can distinguish between threads running on new cores or when a core is already occupied – to achieve maximum throughput then four threads should be across two cores, but for efficiency where speed isn’t a factor, perhaps power gating/clock gating half the cores in a CCX is a good idea.
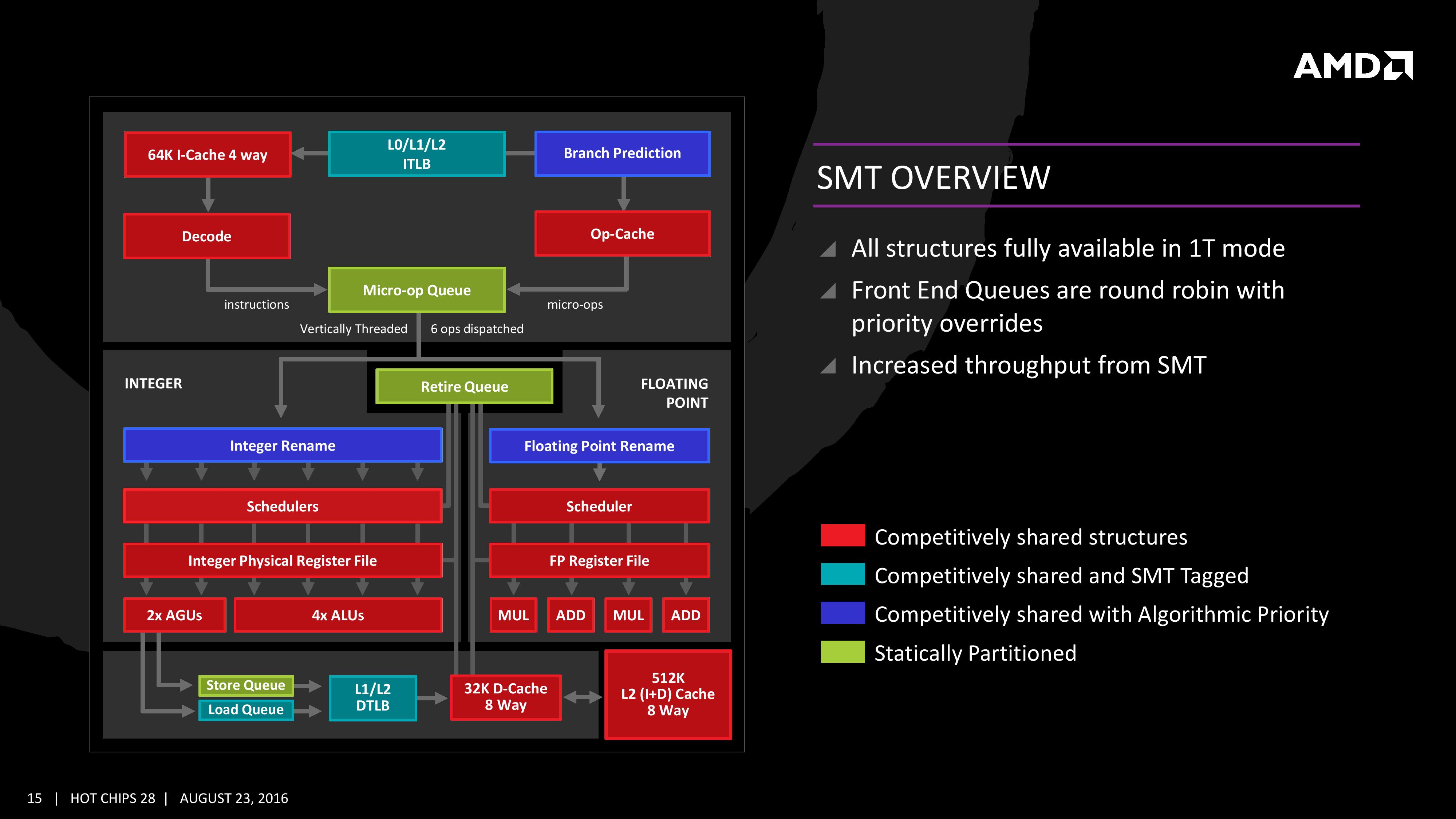
There are a number of ways that AMD will deal with thread management. The basic way is time slicing, and giving each thread an equal share of the pie. This is not always the best policy, especially when you have one performance dominant thread, or one thread that creates a lot of stalls, or a thread where latency is vital. In some methodologies the importance of a thread can be tagged or determined, and this is what we get here, though for some of the structures in the core it has to revert to a basic model.
With each thread, AMD performs internal analysis on the data stream for each to see which thread has algorithmic priority. This means that certain threads will require more resources, or that a branch miss needs to be prioritized to avoid long stall delays. The elements in blue (Branch Prediction, INT/FP Rename) operate on this methodology.
A thread can also be tagged with higher priority. This is important for latency sensitive operations, such as a touch-screen input or immediate user input elements required. The Translation Lookaside Buffers work in this way, to prioritize looking for recent virtual memory address translations. The Load Queue is similarly enabled this way, as typically low latency workloads require data as soon as possible, so the load queue is perfect for this.
Certain parts of the core are statically partitioned, giving each thread an equal timing. This is implemented mostly for anything that is typically processed in-order, such as anything coming out of the micro-op queue, the retire queue and the store queue.
The rest of the core is competitive, meaning that if a thread demands more resources it will try to get there first if there is space to do so each cycle.
New Instructions
AMD has a couple of tricks up its sleeve for Zen. Along with including the standard ISA, there are a few new custom instructions that are AMD only.

Some of the new commands are linked with ones that Intel already uses, such as RDSEED for random number generation, or SHA1/SHA256 for cryptography. The two new instructions are CLZERO and PTE Coalescing.
The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds. This allows a thread to clear a poisoned cache line atomically (in one cycle) in preparation for zero data structures. It also allows a level of repeatability when the cache line is filled with expected data. CLZERO support will be determined by a CPUID bit.
PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met.








106 Comments
View All Comments
eldakka - Wednesday, August 24, 2016 - link
The first page link, AMD Server CPUs and Motherboard Analysis, is wrong, it actually links to the ARM v8-A article.atlantico - Friday, August 26, 2016 - link
Yes, it's also wrong here: http://www.anandtech.com/show/10585/unpacking-amds...Sigh.
TristanSDX - Wednesday, August 24, 2016 - link
Zen do not support transactional memory, big disadvantage comparing to IntelSenti - Wednesday, August 24, 2016 - link
And how much does it matter? TSX is great thing no doubt there. But the adoption? What can you name of real software what uses and get significant benefit of it?I blame Intel stupid marketing for cutting TSX from too many versions and killing the adoption.
coder111 - Wednesday, August 24, 2016 - link
As far as I know, Azul JVMs do support transactional memory. So if you have a Java app, you can use it.Other than that, yes, I haven't seen TSX used much...
68k - Wednesday, August 24, 2016 - link
Isn't the version of glibc in recent Linux-distributions using the lock elision feature of TSX?https://lwn.net/Articles/534758/
https://01.org/blogs/tlcounts/2014/lock-elision-gl...
If so, then essentially every single Linux program does make use of TSX when present.
looncraz - Wednesday, August 24, 2016 - link
One of the most important features of TSX are checkpoints. Zen supports checkpoints in its execution pipeline. Otherwise, I've not seen anything that said Zen did or did not support TSX, not that the tech is widely used at this time.From there, you just need tagging and a few other features to add support. It's something that could be included in Zen+ if Zen does not have it.
silverblue - Wednesday, August 24, 2016 - link
It looks like Zen was developed to accelerate the vast majority of software, and rely on core count for everything else. It might explain the lack of focus on AVX.If cache stats were any indication of performance, it would appear that Zen was destined to compete with Broadwell, but not quite match the Lake CPUs; Zen+ would perhaps close the gap albeit a bit late. Bulldozer was hamstrung by half-speed writes and horrific L3 latency - would it be remiss to assume that they've at least fixed those two issues?
I'm not sure anybody can truly predict performance however, even with a Blender demonstration, and certainly not to work out prospective Cinebench or SuperPi performance. You could have a monster of an architecture, but if the software isn't optimised for it, it's not going to be representative of its true performance.
wumpus - Wednesday, August 24, 2016 - link
I'd still want the TSX instructions before even thinking about the server market. I guess they surrendered that before the overall architecture was finished. Although considering how badly it has worked for Intel (essentially turned off after errata was noted in the first generation), maybe it wasn't worth risk.Alexvrb - Sunday, August 28, 2016 - link
Yeah they need to take their time. A faulty implementation would do more harm than good at this point.