AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Some Final Thoughts and Comparisons
With the Hot Chips presentation we’ve been given more information on the Zen core microarchitecture than we expected to have at this point in the Zen design/launch cycle. AMD has already stated that general availability for Zen will be in Q1, and Zen might not be the final product launch name/brand when it comes to market. However, there are still plenty of gaps in our knowledge for the hardware, and AMD has promised to reveal this information as we get closer to launch.
We discussed in our earlier piece on the Zen performance metrics given mid-week that it can be hard to interpret any anecdotal benchmark data at this point when there is so much we don’t know (or can’t confirm). With the data in this talk at Hot Chips, we can fill out a lot of information for a direct comparison chart to AMD’s last product and Intel’s current offerings.
| CPU uArch Comparison | ||||
| AMD | Intel | |||
| Zen 8C/16T 2017 |
Bulldozer 4M / 8T 2010 |
Skylake 4C / 8T 2015 |
Broadwell 8C / 16T 2014 |
|
| L1-I Size | 64KB/core | 64KB/module | 32KB/core | 32KB/core |
| L1-I Assoc | 4-way | 2-way | 8-way | 8-way |
| L1-D Size | 32KB/core | 16KB/thread | 32KB/core | 32KB/core |
| L1-D Assoc | 8-way | 4-way | 8-way | 8-way |
| L2 Size | 512KB/core | 1MB/thread | 256KB/core | 256KB/core |
| L2 Assoc | 8-way | 16-way | 4-way | 8-way |
| L3 Size | 2MB/core | 1MB/thread | >2MB/cire | 1.5-3MB/core |
| L3 Assoc | 16-way | 64-way | 16-way | 16/20-way |
| L3 Type | Victim | Victim | Write-back | Write-back |
| L0 ITLB Entry | 8 | - | - | - |
| L0 ITLB Assoc | ? | - | - | - |
| L1 ITLB Entry | 64 | 72 | 128 | 128 |
| L1 ITLB Assoc | ? | Full | 8-way | 4-way |
| L2 ITLB Entry | 512 | 512 | 1536 | 1536 |
| L2 ITLB Assoc | ? | 4-way | 12-way | 4-way |
| L1 DTLB Entry | 64 | 32 | 64 | 64 |
| L1 DTLB Assoc | ? | Full | 4-way | 4-way |
| L2 DTLB Entry | 1536 | 1024 | - | - |
| L2 DTLB Assoc | ? | 8-way | - | - |
| Decode | 4 uops/cycle | 4 Mops/cycle | 5 uops/cycle | 4 uops/cycle |
| uOp Cache Size | ? | - | 1536 | 1536 |
| uOp Cache Assoc | ? | - | 8-way | 8-way |
| uOp Queue Size | ? | - | 128 | 64 |
| Dispatch / cycle | 6 uops/cycle | 4 Mops/cycle | 6 uops/cycle | 4 uops/cycle |
| INT Registers | 168 | 160 | 180 | 168 |
| FP Registers | 160 | 96 | 168 | 168 |
| Retire Queue | 192 | 128 | 224 | 192 |
| Retire Rate | 8/cycle | 4/cycle | 8/cycle | 4/cycle |
| Load Queue | 72 | 40 | 72 | 72 |
| Store Queue | 44 | 24 | 56 | 42 |
| ALU | 4 | 2 | 4 | 4 |
| AGU | 2 | 2 | 2+2 | 2+2 |
| FMAC | 2x128-bit | 2x128-bit 2x MMX 128-bit |
2x256-bit | 2x256-bit |
Bulldozer uses AMD-coined macro-ops, or Mops, which are internal fixed length instructions and can account for 3 smaller ops. These AMD Mops are different to Intel's 'macro-ops', which are variable length and different to Intel's 'micro-ops', which are simpler and fixed-length.
Excavator has a number of improvements over Bulldozer, such as a larger L1-D cache and a 768-entry L1 BTB size, however we were never given a full run-down of the core in a similar fashion and no high-end desktop version of Excavator will be made.
This isn’t an exhaustive list of all features (thanks to CPU World, Real World Tech and WikiChip for filling in some blanks) by any means, and doesn’t paint the whole story. For example, on the power side of the equation, AMD is stating that it has the ability to clock gate parts of the core and CCX that are not required to save power, and the L3 runs on its own clock domain shared across the cores. Or the latency to run certain operations, which is critical for workflow if a MUL operation takes 3, 4 or 5 cycles to complete. We have been told that the FPU load is two cycles quicker, which is something. The latency in the caches is also going to feature heavily in performance, and all we are told at this point is that L2 and L3 are lower latency than previous designs.
A number of these features we’ve already seen on Intel x86 CPUs, such as move elimination to reduce power, or the micro-op cache. The micro-op cache is a piece of the puzzle we want to know more about, especially the rate at which we get cache hits for a given workload. Also, the use of new instructions will adjust a number of workloads that rely on them. Some users will lament the lack of true single-instruction AVX-2 support, however I suspect AMD would argue that the die area cost might be excessive at this time. That’s not to say AMD won’t support it in the future – we were told quite clearly that there were a number of features originally listed internally for Zen which didn’t make it, either due to time constraints or a lack of transistors.
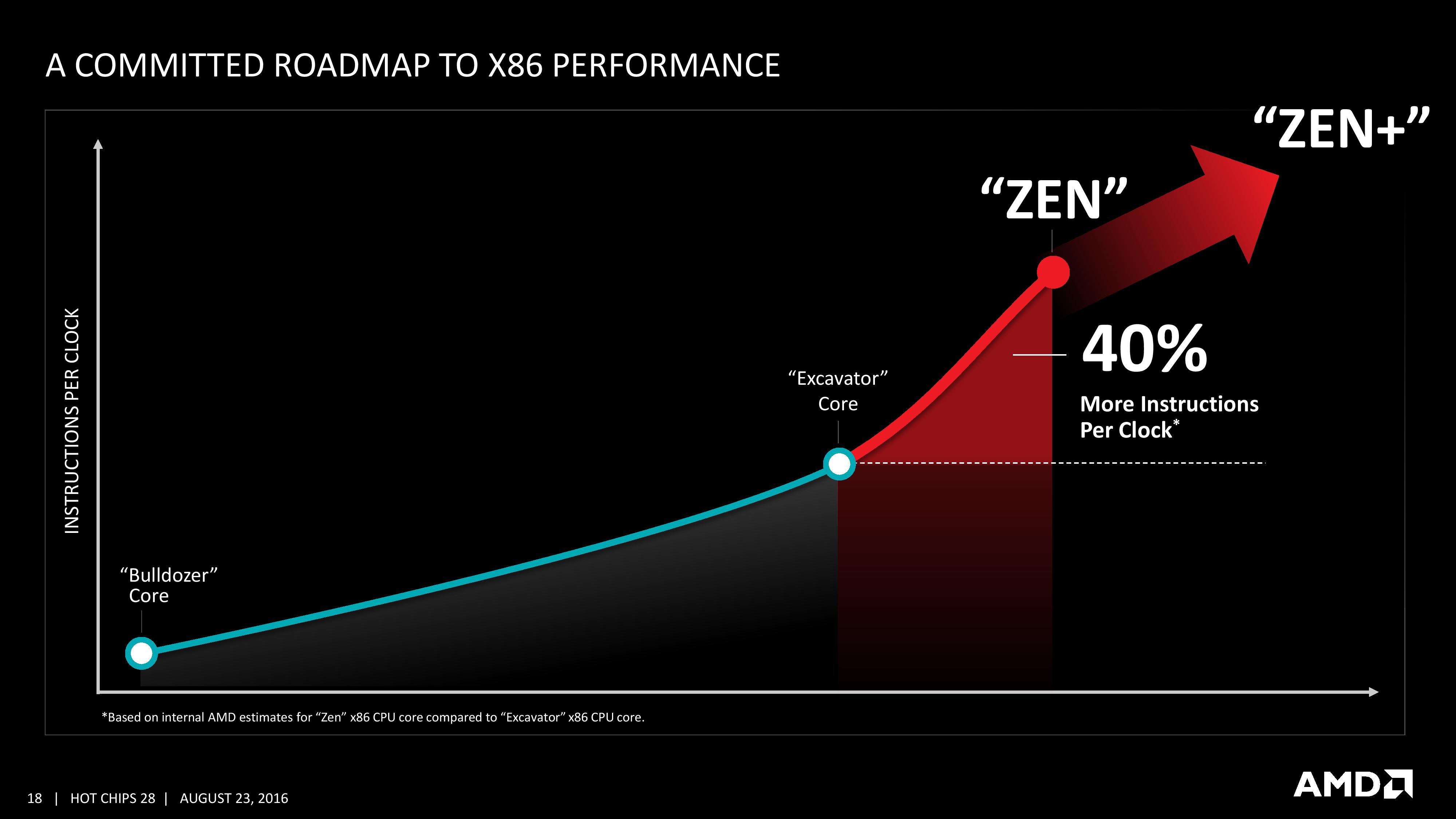
We are told that AMD has a clear internal roadmap for CPU microarchitecture design over the next few generations. As long as we don’t stay for so long on 14nm similar to what we did at 28/32nm, with IO updates over the coming years, a competitive clock-for-clock product (even to Broadwell) with good efficiency will be a welcome return.








106 Comments
View All Comments
CrazyElf - Tuesday, August 23, 2016 - link
If they can really get a 40% improvement over Excavator, and I mean 40% on average, not on a few select benchmarks, then AMD has a serious chance of being a compelling option once again.I'm hoping to see more improvements on Floating Point, which was comically bad in Bulldozer.
A big part of the problem is that we don't know how well Zen will clock or the power consumption. Still, this should be a major leap in performance overall. We'll have to wait for the launch day benchmarks to see the true story.
Another big concern is the platform. CPU performance is only part of the story. We need a good platform that can rival the Z170 and Intel HEDT platforms for this to be compelling on the desktop. For mobile, there will have to be good dual channel Zen APUs (Carrizo, as Anandtech noted was heavily gimped by poor quality OEM designs obsessed with cost cutting).
jabber - Wednesday, August 24, 2016 - link
Yeah I don't think OEMs and others are that worried about supporting AMD. AMD have withered away so much, making AMD CPU capable gear must have become a very minor part of say ASUS/Gigabyte/MSI etc. revenue stream. Making AMD based graphics cards is okay but motherboards? Not so much.teuast - Wednesday, August 24, 2016 - link
I wouldn't speak so soon. Just this year MSI and Gigabyte (at least) have introduced new AM3+ boards with USB 3.1 and PCIe 3.0. Why, I'm not sure, but if they're doing that for something as old and deprecated as the FX chips, it would defy logic for Zen to come out and for them to only release a few token efforts.I will say, if the CPUs are good but you're right about OEMs not being concerned with support, then the first OEM to say "hey, why don't we make some actually good AM4 boards?" is going to make an absolute killing.
h4rm0ny - Thursday, August 25, 2016 - link
Are you sure about the PCI-E v3 on AM3+ motherboards? I can find recent releases that have USB3.1 and M.2, but none that support PCI-Ev3. Can you link me or provide a model number? I didn't think 3rd generation PCI-E was possible on the Bulldozer line.SKD007 - Thursday, August 25, 2016 - link
SABERTOOTH 990FX/GEN3 R2.0SKD007 - Thursday, August 25, 2016 - link
https://www.asus.com/Motherboards/SABERTOOTH_990FX...Outlander_04 - Thursday, August 25, 2016 - link
A little misleading . The Graphics pci-e controller is built in to an FX processor so adding a pci-e 3 standard slot to a motherboard will make no difference to actual bandwidth.Not an issue though since x16 pci-e 2 has the same bandwidth as x8 pci-e 3 and intel boards with SLI/crossfire ability running at x8/x8 do not choke any current graphics card
h4rm0ny - Thursday, August 25, 2016 - link
What about PCI-E SSDs? Can I get full bandwidth on those? I agree about the graphics cards but that's not so important to me. If I can get full PCI-Ev3 x4 performance for an SSD then I'll pribably buy this as a hold-over until Zen. Thanks fir the link!fanofanand - Friday, August 26, 2016 - link
Pci-e 3.0 x4 should be the same as 2.0 x 8. So long as you have a vacant x8 it should theoretically work the same.extide - Wednesday, September 7, 2016 - link
I think they use a PLX chip and turn the 32 2.0 lanes from the FX chip into 16 3.0 lanes.