AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
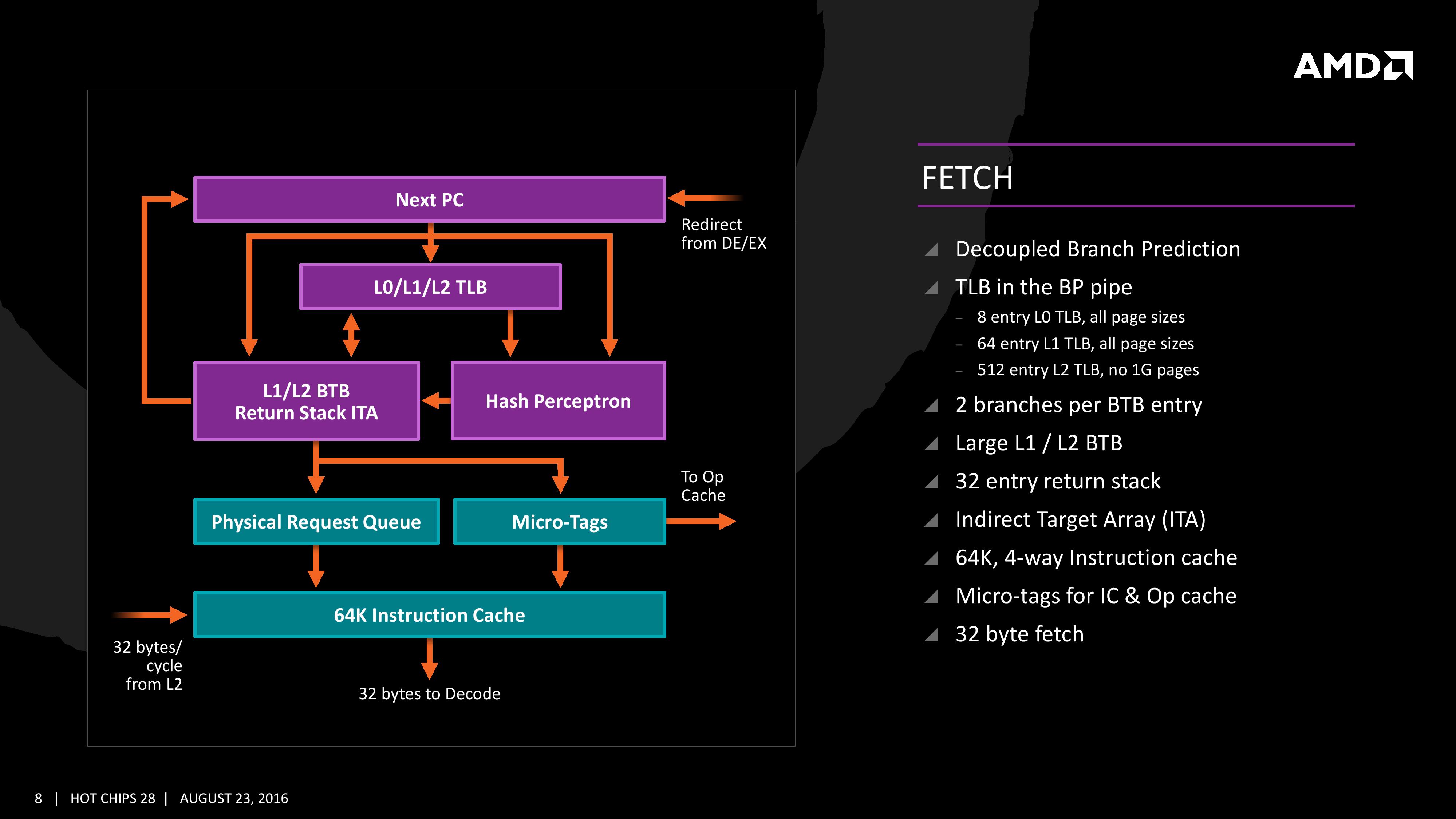
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
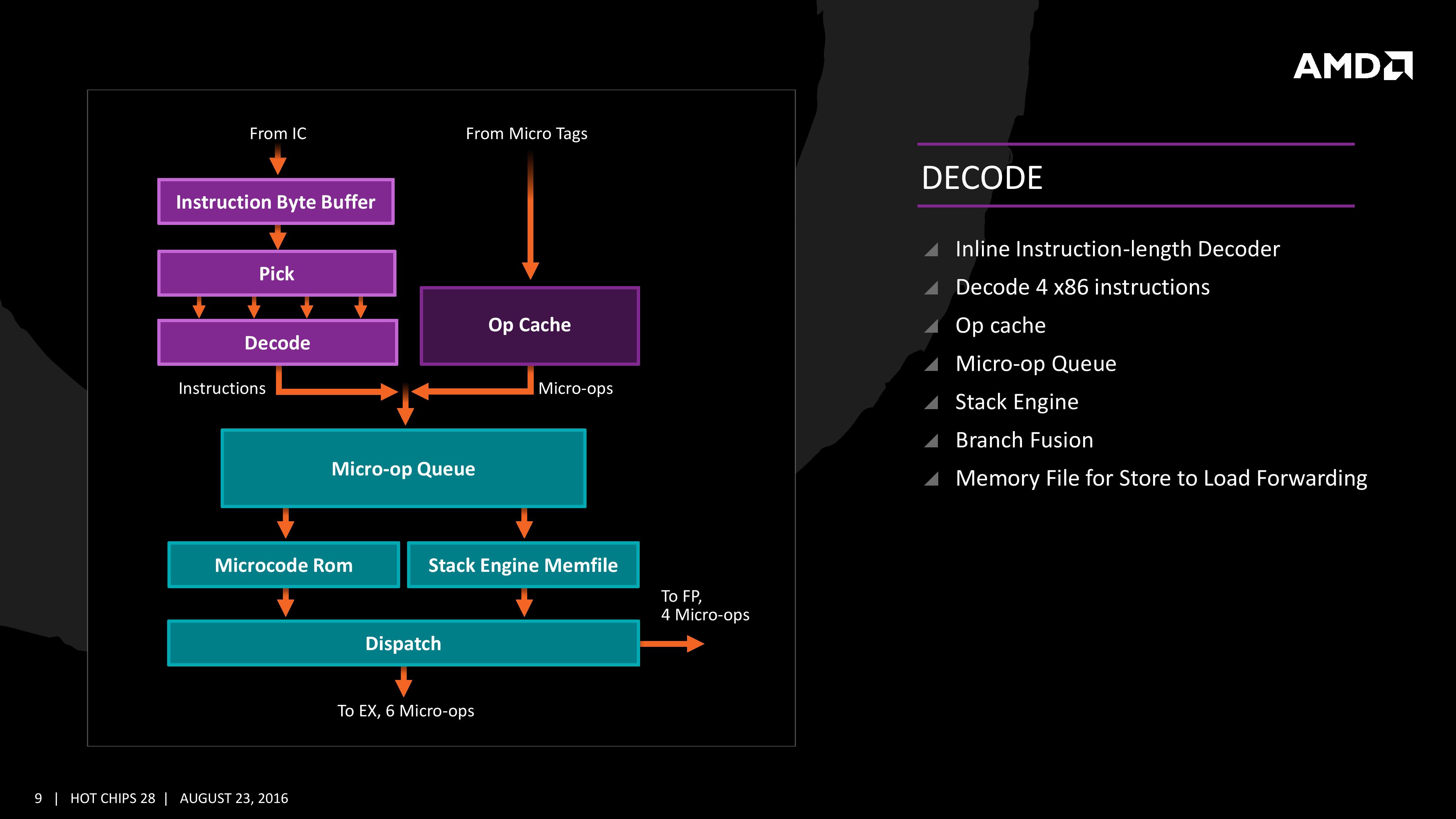
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
tipoo - Wednesday, August 31, 2016 - link
Meanwhile Intel worked on shortening pipelines...Curious to see how this will go, hope for AMDs sake it's competitive.masouth - Friday, September 2, 2016 - link
I hope it works out for AMD as well but reading about long pipelines and higher freqs always reminds me of the P4 days/shudder
junky77 - Wednesday, August 24, 2016 - link
The problem is now having Intel/AMD provide fast enough CPUs to feed the new GPUs that don't seem to slow down..gamerk2 - Wednesday, August 24, 2016 - link
Pretty much anything from an i7 920 onward can keep GPUs fed these days. For gaming purposes, CPUs haven't been the bottleneck for over a decade. That's why you don't see significant improvement from generation to generation, since our favorite CPU tests happen to be with GPU sensitive benchmarks.Death666Angel - Thursday, August 25, 2016 - link
The story is much more complicated than you are making it seem:https://www.youtube.com/watch?v=frNjT5R5XI4
tipoo - Wednesday, August 31, 2016 - link
A Skylake i3 presents better frametimes than old i7s like the 920 or 2500Krhysiam - Wednesday, August 24, 2016 - link
40% over Excavator probably still puts it well behind even Haswell on IPC. If I'm looking at it right, Bench on this site has 4 single threaded tests (3 Cinebench versions and 3D Particle...). I crunched some numbers and found that if you add 40% to Excavator @ 4Ghz (X4 860 turbo), it still loses to Skylake @ 3.9Ghz (turbo) by between 32% & 39% across the four benchmarks. Haswell @ 3.9Ghz (turbo) would still be faster by 24% to 33%.If it really is 40% minimum, AND they can sustain decent clock speeds, then that's at least enough to be in the ballpark, but it's still well short of Intel in those few benchmarks at least. TBH I don't know how representative those benchmarks are of overall single-threaded performance.
It could well be a case of AMD offering significantly poorer lightly threaded performance, but a genuine 8 core CPU at an affordable (i.e. not $1000) price.
gamerk2 - Wednesday, August 24, 2016 - link
I except the following:~40% average IPC gain in FP workloads
~30% average IPC gain in INT workloads
~20% clock speed reduction.
Average performance increase: ~15-20%, or Ivy Bridge i7 level performance.
Michael Bay - Wednesday, August 24, 2016 - link
Well, nothing stops them from their own brand of tick-tock, especially considering largely stagnant intel IPC.looncraz - Wednesday, August 24, 2016 - link
40% over Excavator is almost exactly Haswell overall, particularly once you shape the performance to match what is known about Zen.http://excavator.looncraz.net/