AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
The High-Level Zen Overview
AMD is keen to stress that the Zen project had three main goals: core, cache and power. The power aspect of the design is one that was very aggressive – not in the sense of aiming for a mobile-first design, but efficiency at the higher performance levels was key in order to be competitive again. It is worth noting that AMD did not mention ‘die size’ in any of the three main goals, which is usually a requirement as well. Arguably you can make a massive core design to run at high performance and low latency, but it comes at the expense of die size which makes the cost of such a design from a product standpoint less economical (if AMD had to rely on 500mm2 die designs in consumer at 14nm, they would be priced way too high). Nevertheless, power was the main concern rather than pure performance or function, which have been typical AMD targets in the past. The shifting of the goal posts was part of the process to creating Zen.

This slide contains a number of features we will hit on later in this piece but covers a number of main topics which come under those main three goals of core, cache and power.
For the core, having bigger and wider everything was to be expected, however maintaining a low latency can be difficult. Features such as the micro-op cache help most instruction streams improve in performance and bypass parts of potentially long-cycle repetitive operations, but also the larger dispatch, larger retire, larger schedulers and better branch prediction means that higher throughput can be maintained longer and in the fastest order possible. Add in dual threads and the applicability of keeping the functional units occupied with full queues also improves multi-threaded performance.
For the caches, having a faster prefetch and better algorithms ensures the data is ready when each of the caches when a thread needs it. Aiming for faster caches was AMD’s target, and while they are not disclosing latencies or bandwidth at this time, we are being told that L1/L2 bandwidth is doubled with L3 up to 5x.
For the power, AMD has taken what it learned with Carrizo and moved it forward. This involves more aggressive monitoring of critical paths around the core, and better control of the frequency and power in various regions of the silicon. Zen will have more clock regions (it seems various parts of the back-end and front-end can be gated as needed) with features that help improve power efficiency, such as the micro-op cache, the Stack Engine (dedicated low power address manipulation unit) and Move elimination (low-power method for register adjustment - pointers to registers are adjusted rather than going through the high-power scheduler).
The Big Core Diagram
We saw this diagram last week, but now we get updates on some of the bigger features AMD wants to promote:
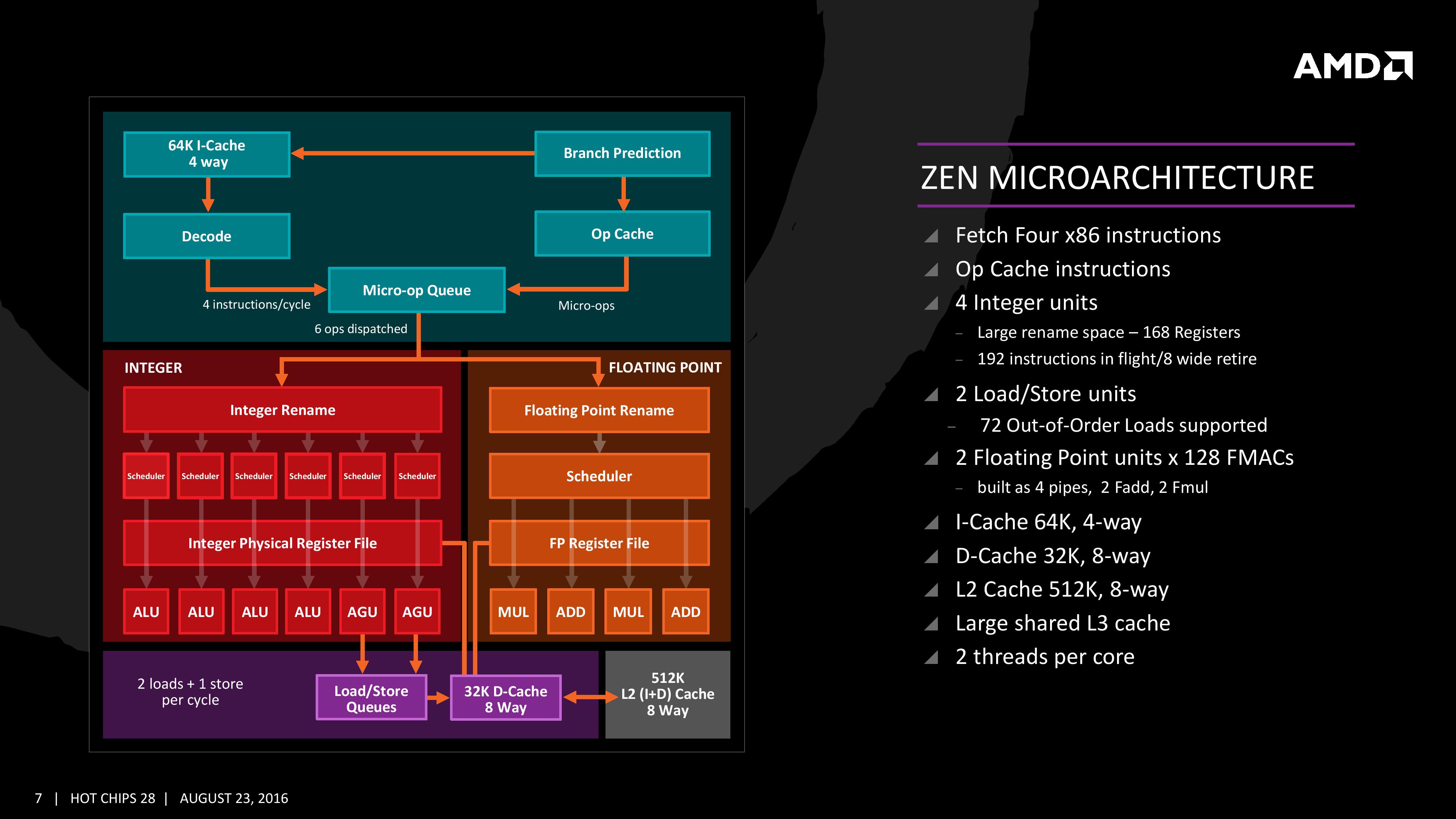
The improved branch predictor allows for 2 branches per Branch Target Buffer (BTB), but in the event of tagged instructions will filter through the micro-op cache. On the other side, the decoder can dispatch 4 instructions per cycle however some of those instructions can be fused into the micro-op queue. Fused instructions still come out of the queue as two micro-ops, but take up less buffer space as a result.
As mentioned earlier, the INT and FP pipes and schedulers are separated, but the INT rename space is 168 registers wide, which feeds into 6x14 scheduling queues. The FP employs as 160 entry register file, and both the FP and INT sections feed into a 192-entry retire queue. The retire queue can operate at 8 instructions per cycle, moving up from 4/cycle in previous AMD microarchitectures.
The load/store units are improved, supporting a 72 out-of-order loads, similar to Skylake. We’ll discuss this a bit later. On the FP side there are four pipes (compared to three in previous designs) which support combined 128-bit FMAC instructions. These cannot be combined for one 256-bit AVX2, but can be scheduled for AVX2 over two instructions.








106 Comments
View All Comments
CrazyElf - Tuesday, August 23, 2016 - link
If they can really get a 40% improvement over Excavator, and I mean 40% on average, not on a few select benchmarks, then AMD has a serious chance of being a compelling option once again.I'm hoping to see more improvements on Floating Point, which was comically bad in Bulldozer.
A big part of the problem is that we don't know how well Zen will clock or the power consumption. Still, this should be a major leap in performance overall. We'll have to wait for the launch day benchmarks to see the true story.
Another big concern is the platform. CPU performance is only part of the story. We need a good platform that can rival the Z170 and Intel HEDT platforms for this to be compelling on the desktop. For mobile, there will have to be good dual channel Zen APUs (Carrizo, as Anandtech noted was heavily gimped by poor quality OEM designs obsessed with cost cutting).
jabber - Wednesday, August 24, 2016 - link
Yeah I don't think OEMs and others are that worried about supporting AMD. AMD have withered away so much, making AMD CPU capable gear must have become a very minor part of say ASUS/Gigabyte/MSI etc. revenue stream. Making AMD based graphics cards is okay but motherboards? Not so much.teuast - Wednesday, August 24, 2016 - link
I wouldn't speak so soon. Just this year MSI and Gigabyte (at least) have introduced new AM3+ boards with USB 3.1 and PCIe 3.0. Why, I'm not sure, but if they're doing that for something as old and deprecated as the FX chips, it would defy logic for Zen to come out and for them to only release a few token efforts.I will say, if the CPUs are good but you're right about OEMs not being concerned with support, then the first OEM to say "hey, why don't we make some actually good AM4 boards?" is going to make an absolute killing.
h4rm0ny - Thursday, August 25, 2016 - link
Are you sure about the PCI-E v3 on AM3+ motherboards? I can find recent releases that have USB3.1 and M.2, but none that support PCI-Ev3. Can you link me or provide a model number? I didn't think 3rd generation PCI-E was possible on the Bulldozer line.SKD007 - Thursday, August 25, 2016 - link
SABERTOOTH 990FX/GEN3 R2.0SKD007 - Thursday, August 25, 2016 - link
https://www.asus.com/Motherboards/SABERTOOTH_990FX...Outlander_04 - Thursday, August 25, 2016 - link
A little misleading . The Graphics pci-e controller is built in to an FX processor so adding a pci-e 3 standard slot to a motherboard will make no difference to actual bandwidth.Not an issue though since x16 pci-e 2 has the same bandwidth as x8 pci-e 3 and intel boards with SLI/crossfire ability running at x8/x8 do not choke any current graphics card
h4rm0ny - Thursday, August 25, 2016 - link
What about PCI-E SSDs? Can I get full bandwidth on those? I agree about the graphics cards but that's not so important to me. If I can get full PCI-Ev3 x4 performance for an SSD then I'll pribably buy this as a hold-over until Zen. Thanks fir the link!fanofanand - Friday, August 26, 2016 - link
Pci-e 3.0 x4 should be the same as 2.0 x 8. So long as you have a vacant x8 it should theoretically work the same.extide - Wednesday, September 7, 2016 - link
I think they use a PLX chip and turn the 32 2.0 lanes from the FX chip into 16 3.0 lanes.