AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
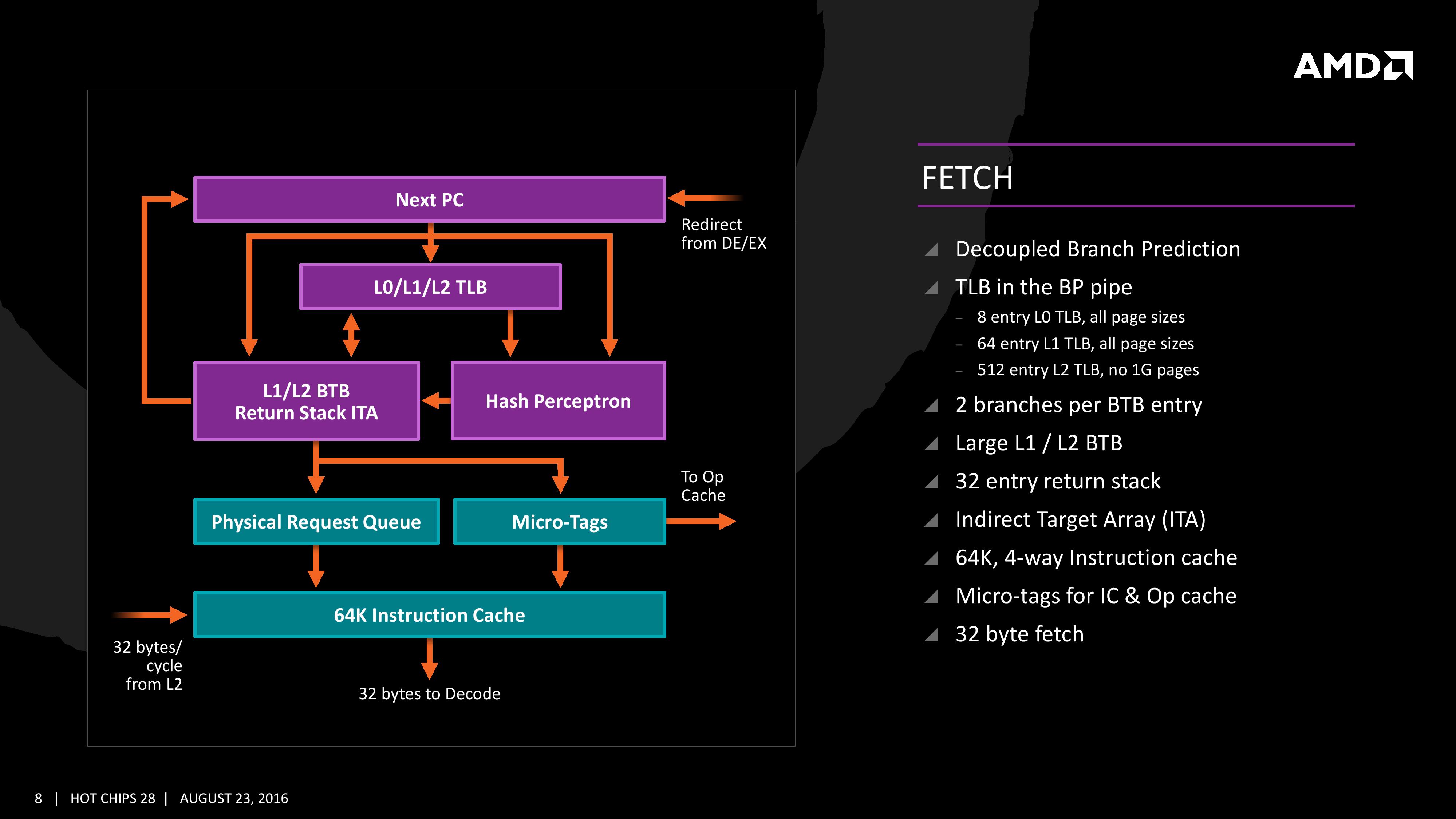
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
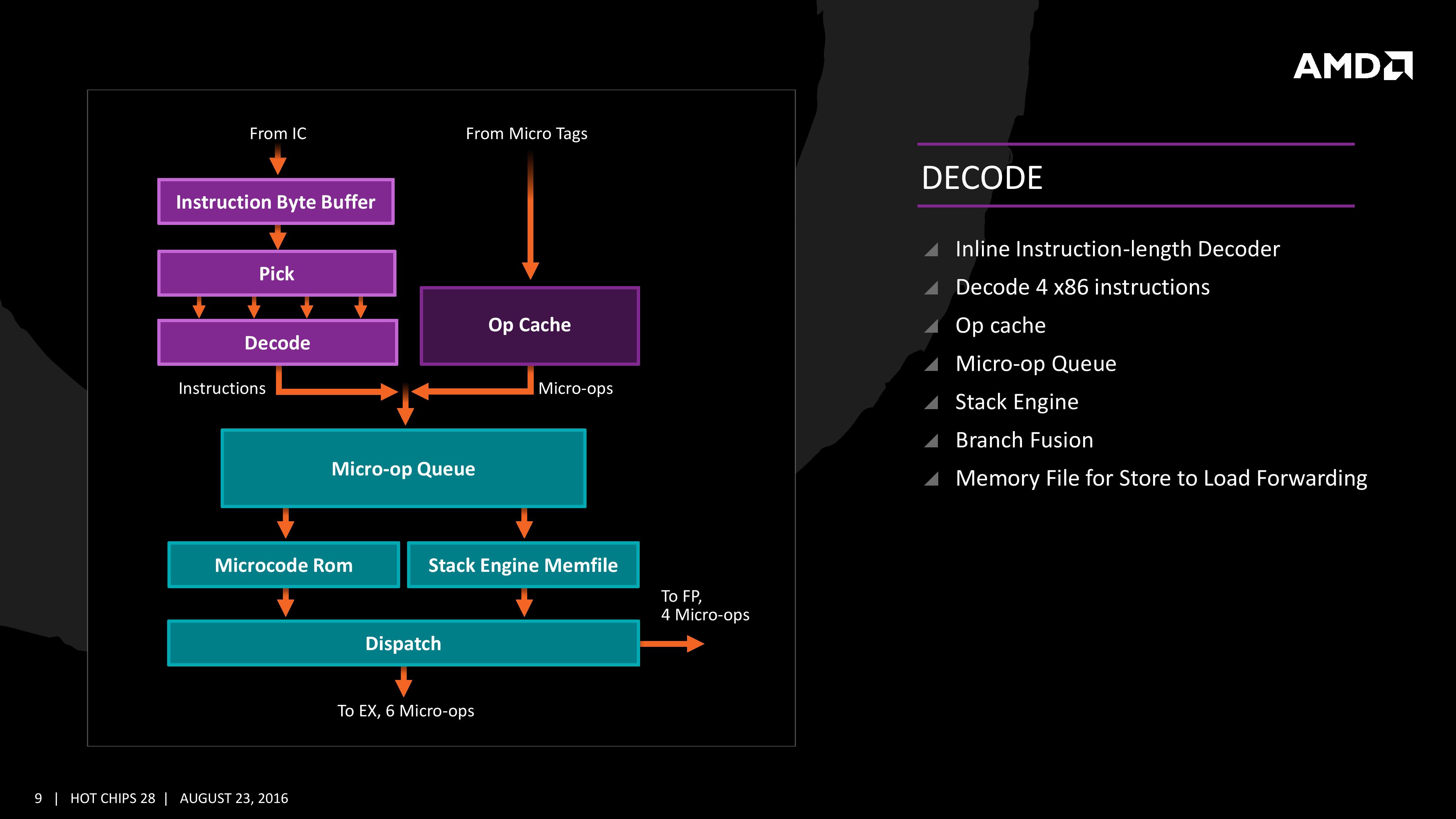
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
Xajel - Wednesday, August 24, 2016 - link
I have a feeling that the Socket has more potential, there's a huge jump in pin counts that might hides something, I suspect AMD have specific HEDT version with higher TDP ( like 130-140 ) that might ship later in 2017 after the first wave. or maybe even triple channel that works only on higher-end HEDT motherboard while it will be still backward compatible with regular dual channels motherboards...none12345 - Wednesday, August 24, 2016 - link
Nice article, thanks, and timely too.Cant wait for real zen benchmarks.
I so badly want this to be another athlon64 x2 moment. But i dont think we will get that, and we don't need that. Consider the athlon 64 gave us multicore, and it stomped the pentium4 as well.
Ill be completey happy with a phenom II moment. Which was note quite as fast as intel, but gave you more almost as fast cores for your money. As well as unlocking cores at a much lower price point, which gave you superior overclocking for your money.
I will not at this point consider buying another quad core. Quad core is insufficient for my typical work load. I do not use 1 heavily multithreaded piece of software, i constantly use multiple pieces of moderately threaded software that currently mostly maxes out my processor.
In my opinion the industry should have stopped selling dual cores a year ago. It should be quad core at the low end and 6 or 8 core should be the mainstream. For desktop that is, i can still see some moble things being dual core.
Because i will NOT consider another quad core at this point. My only option today is the intel's enthusiast platform, which is far too expensive relative to the performance increase. So they are out.
And this is why im hoping that zen does not disappoint. If they can give me 6 or 8 cores that are within 10% per core, for similar costs to the i5 or i7 line, then im a definite buy. If they give me 6 or 8 cores that are priced like intel's enthusiast platform, well then i guess im not upgrading, untill someone can offer me more cores for a reasonable price.
If intel would offer more cores mainstream, then id absolutely consider a new chip from them. IE if i3 was 4 core, i5 was 6 core, and i7 was 8 core.
Vlad_Da_Great - Wednesday, August 24, 2016 - link
i7-4790K will wipe the floor with the ZEN mop. Roy Jones Jr(Intel) vs Montell Griffin(AMD) part II. https://www.youtube.com/watch?v=VZ_4FrhHHJE That is it! I cant believe AnandTech is biting on their marketing fluff.H2323 - Wednesday, August 24, 2016 - link
"Nevertheless, power was the main concern rather than pure performance or function, which have been typical AMD targets in the past."This is contradictory to what AMD has had to say. Power was not a greater focus than performance, just not true.
takeshi7 - Wednesday, August 24, 2016 - link
Wow, I haven't seen victim caches being used in a CPU since the old VIA C3. I hope the advantage of not having to duplicate data between the L2 and L3 caches pays off for AMD.H2323 - Wednesday, August 24, 2016 - link
and bulldozer in 2011Oxford Guy - Saturday, August 27, 2016 - link
The EDRAM L4 in Broadwell C is supposed to be a victim cache.intangir - Wednesday, August 24, 2016 - link
Great article. By the way, Ian, you're missing a syllable from "Microarchitecture" in the title.name99 - Wednesday, August 24, 2016 - link
"The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds"Not exactly. The point of an instruction like CLZERO is that the usual way cache lines are filled uses twice as much bandwidth as necessary.
When I write the first datum to a cacheline, the first thing that needs to be done is to load the cacheline and then overwrite the datum I wanted to write. This is obvious. BUT suppose I'm writing enough data that I write over the entire cache line? Then pulling it in was a waste of bandwidth.
THAT is the point of an instruction like CLZERO, to "ready the cache line for being overwritten" without wasting time loading it. Of course for many purposes filling with zeros is what one wants, but there are other times when one is simply engaged in bulk writing and it again makes sense.
PPC for example had a similar instruction, DCBZ, as does ARM, DC ZVA.
I'd expect this instruction to be used, at the absolute minimum, by the OS wherever it needs to zero and copy pages, by standard libraries data copy routines, and by the compiler whenever it writes "large" (ie cache line or larger) data structures.
"PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met."
I think you are misunderstanding what this is about. My GUESS (only a guess) is that it refers to the following.
Academic work was done a few years ago that showed that the way Linux (and probably most other OSs) allocated and deallocated pages meant that, for the most part, contiguous virtual pages remain as contiguous physical pages over reasonably long stretches (say 8 to 16 pages). A consequence of this is that a TLB entry could contain not just the single physical address it refers to but also a length field or something equivalent, say that this TLB holds for this page and, say, the next 5 pages. This would work IF
- the pages all have the same settings and permissions (usually the case)
- the pages are contiguous in physical memory (as I said, usually the case)
The consequence of this is that for fairly minor modifications to the TLB, one manages to double or more the coverage of one's TLB, and that's certainly nothing to be sneered at.
It's possible that an OS that tries to maintain page contiguity could do even better --- the papers I read referred to unmodified Linux.
I've no idea what that branch predictor info refers to; but perhaps this is more of the usual x86 BS where you have to deal with some insane corner condition involving self-modifying code. The basic point, however, is obvious --- you get a nice increase in TLB coverage without having to change software, and without the pain of jumping to a larger page size.
I'm really glad to see AMD implement this because I thought it was a nice idea when I read it, and it's basically useful for everyone ---also IBM, also Intel, also ARM --- as long as the OS you're running is not insane. For someone like Apple, where they can fully control the OS, it's especially appealing. (And hell, for all we know they're actually first before AMD, they just never told anyone?)
name99 - Wednesday, August 24, 2016 - link
here we are, this is the paper I was referring to:http://www.cs.rutgers.edu/~abhib/binhpham-micro12....