Assessing IBM's POWER8, Part 2: Server Applications on OpenPOWER
by Johan De Gelas on September 15, 2016 8:01 AM ESTFuture Visions: POWER8 with NVLink
Digging a bit deeper, the shiny new S822LC is a different beast. If offers the "NVIDIA improved" POWER8. The core remained the same but the CPU now comes with NVIDIA's NVlink technology. Four of these NVLink ports allows the S822LC to make a very fast (80 GB/s full duplex) and direct link with the latest and greatest of NVIDIA GPUs: the Tesla P100. Ryan has discussed NVLink and the 16 nm P100 in more detail a few months ago. I quote:
NVLink will allow GPUs to connect to either each other or to supporting CPUs (OpenPOWER), offering a higher bandwidth cache coherent link than what PCIe 3 offers. This link will be important for NVIDIA for a number of reasons, as their scalability and unified memory plans are built around its functionality.
Each P100 has a 720 GB/s of memory bandwidth, powered by 16 GB of HBM2 stacked memory. If you combine that with the fact that the P100 has more than twice the processing power in half precision and double precision floating point (important for machine learning algorithms) than its predecessor, it easy to understand why the data transfers from the CPU to GPU can easily become a bottleneck in some applications.
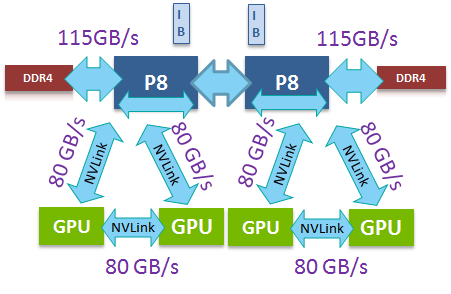
This means that the "OpenPOWER way of working" has enabled the IBM POWER8 to be the first platform to fully leverage the best of NVIDIA's technology. It is almost certain that Intel will not add NVLink to their products, as Intel went a totally different route with the Xeon and Xeon Phi. NVLink offers 80 GB/s of full-duplex connectivity per GPU, which is provided in the form of 4 20GB/s connections that can be routed between GPUs and CPUs as needed. By comparison, a P100 that plugs into an x16 PCIe 3.0 slot only gets 16 GB/s full duplex to communicate with both the CPU and the other GPUs. So theoretically, a quad NVLink setup from GPU to CPU offers at least 2.5 times more bandwidth. However, IBM claims that in reality the advantage is 2.8x as the NVLink is more efficient than PCIe (83% of theoretical bandwidth vs. 74%).

The NVLink equipped P100 cards will make use of the SXM2 form factor and come with a bonus: they deliver 13% more raw compute performance than the "classic" PCIe card due to the higher TDP (300W vs 250W). By the numbers, this amounts to 5.3 TFLOPS double precision for the SXM2 version, versus 4.7 TFLOPS for the PCIe version.








49 Comments
View All Comments
loa - Monday, September 19, 2016 - link
This article neglects one important aspect to costs:per-core licensed software.
Those licenses can easily be north of 10 000$ . PER CORE. For some special purpose software the license cost can be over 100 000 $ / core. Yes, per core. It sounds ridiculous, but it's true.
So if your 10-core IBM system has the same performance as a 14-core Intel system, and your license cost is 10 000$ / core, well, then you just saved yourself 40 000 $ by using the IBM processor.
Even with lower license fee / core, the cost advantage can be significant, easily outweighing the additional electricity bill over the lifetime of the server.
aryonoco - Tuesday, September 20, 2016 - link
Thanks Johan for another very interesting article.As I have said before, there is literally nothing on the web that compares with your work. You are one of a kind!
Looking forward to POWER 9. Should be very interesting.
HellStew - Tuesday, September 20, 2016 - link
Good article as usually. Thanks Johan.I'd still love to see some VM benchmarks!
cdimauro - Wednesday, September 21, 2016 - link
I don't know how much value could have the performed tests, because they don't reflect what happens in the real world. In the real world you don't use an old o.s. version and an old compiler for an x86/x64 platform, only because the POWER platform has problems with the newer ones. And a company which spends so much money in setting up its systems, can also spend just a fraction and buy an Intel compiler to squeeze out the maximum performance.IMO you should perform the tests with the best environment(s) which is available for a specific platform.
JohanAnandtech - Sunday, September 25, 2016 - link
I missed your reaction, but we discussed this is in the first part. Using Intel's compiler is good practice in HPC, but it is not common at all in the rest of the server market. And I do not see what an Intel compiler can do when you install mysql or run java based applications. Nobody is running recompiled databases or most other server software.cdimauro - Sunday, October 2, 2016 - link
Then why you haven't used the latest available distro (and compiler) for x86? It's the one which people usually use when installing a brand new system.nils_ - Monday, September 26, 2016 - link
This seems rather disappointing, and with regards to optmized Postgres and MariaDB, I think in that case one should also build these software packages optimized for Xeon Broadwell.jesperfrimann - Thursday, September 29, 2016 - link
@nils_Optimized for.. simply means that the software has been officially ported to POWER, and yes that would normally include that the specific accelerators that are inside the POWER architecture now are actually used by the software, and this usually means changing the code a bit.
So .. to put it in other words .. just like it is with Intel x86 Xeons.
// Jesper
alpha754293 - Monday, October 3, 2016 - link
I look forward to your HPC benchmarks if/when they become available.