Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. That said, it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. We use this benchmark because it allows us to isolate the FP performance and the energy consumption from other factors such as L2/L3 cache/memory subsystem.
We compiled the C-ray multi-threaded version with -O3 -ffast-math. Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications perform worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior.
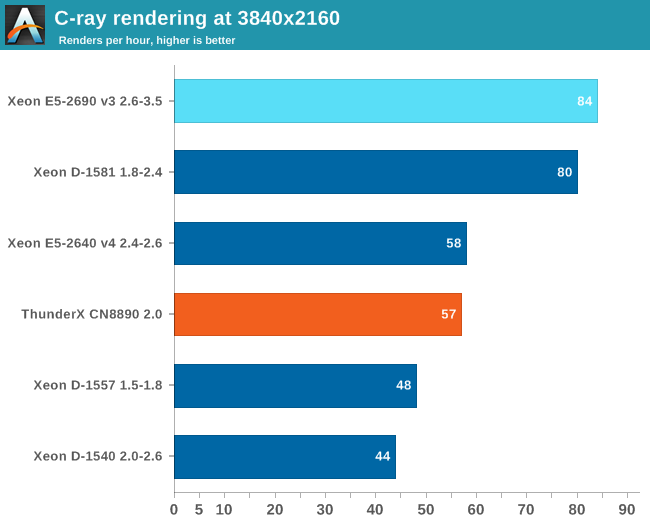
This is the most favorable floating point benchmark that we could run on the ThunderX: it does not use the high latency blocking L2-cache, nor does it needs to access the DRAMs. Also, the Xeons cannot really fully flex their AVX muscles. So take this with a large grain of salt.
In these situations, the ThunderX performs like the midrange Xeon E5-2640 v4.








82 Comments
View All Comments
TheinsanegamerN - Thursday, June 16, 2016 - link
While you are right on the actual age of the chip, if you dont compare efficiency on different nodes, how on earth would you know if you made any progress?Unless you are suggesting that one should never compare one generation of chips to another, which is simply ludicrous. Where is this "you cane compare two different nodes" mindset coming from? I've seen it in the GPU forums as well, and it makes no sense.
shelbystripes - Wednesday, June 15, 2016 - link
The E5-2600 v3 is a Haswell part, meaning it's Intel's second ("tock") core design on 22nm. So not only is this a smaller process, it's a second-gen optimization on a smaller process.For a first-gen 28nm part that includes power-hungry features like multiple 10GbE, these are some very promising initial results. A 14nm die shrink should create some real improvements off the bat in terms of performance per watt, and further optimizations from there should make this thing really shine.
Given that Intel hasn't cracked 10nm at all yet, and it'll take a while for 10nm Xeons to show up once they do, Cavium has room to play catch-up. I mean, hell, they're keeping up/surpassing Xeon D in some use cases NOW, and that's a 14nm part. What Cavium needs most is power optimization at this point, and I'm sure they'll get there in time.
Michael Bay - Thursday, June 16, 2016 - link
Good to know Intel is keeping you up to date with what`s happening in their uv labs.rahvin - Thursday, June 16, 2016 - link
Last I saw Intel is already running their test fabs at 10nm. Once they perfect it in the test fabs it only takes them about 6 months to roll it into a full scale fab. Maybe you an point to this source that indicates Intel has failed at 10nm.kgardas - Wednesday, June 15, 2016 - link
Nice article, but really looking to see testing of ThunderX2 and X-Gene 3. Will be interesting as Intel seems to be kind of struggling with single-threaded performance recently...Drazick - Wednesday, June 15, 2016 - link
Just a question.You emphasized the performance are x3 instead of x5 but I bet Intel used Intel ICC for those tests.
Intel works hard on their Compilers and anyone who wants to extract the best of Intel CPU uses them as well.
Since CPU means Compilers, if Intel has advantage on that department you should show that as well.
Namely give us some results using Intel ICC.
Thank You.
UrQuan3 - Wednesday, June 15, 2016 - link
Of course, if Anandtech uses ICC, they should use better flags in gcc for ARM/ThunderX as well (core specific flags, NEON, etc). Both ICC and targeted flags give improvements. Often large ones. This was a generic test.JohanAnandtech - Thursday, June 16, 2016 - link
For integer workloads, ICC is not that much faster than gcc (See Andreas Stiller's work). And there is the fact that ICC requires licensing and other time consuming stuff. From a linux developer/administrator perspective, it is much easier just to use gcc, you simply install it from repositories, no licensing headaches and very decent performance (about 90% of icc). So tha vast majority of the **NON HPC ** software is compiled with gcc. Our added value is that we show how the processors compare with the most popular compiler on linux. That is the big difference between benchmarking to put a CPU in the best light and benchmarking to show what most people will probably experience.Until Intel makes ICC part of the typical linux ecosystem, it is not an advantage at all in most non-HPC software.
patrickjp93 - Friday, June 17, 2016 - link
His work is woefully incomplete, lacking any analysis on vectorized integer workloads, which Intel destroys GCC in to the tune of a 40% lead.phoenix_rizzen - Wednesday, June 15, 2016 - link
"The one disadvantage of all Supermicro boards remains their Java-based remote management system. It is a hassle to get it working securely (Java security is a user unfriendly mess), and it lacks some features like booting into the BIOS configuration system, which saves time."It's IPMI, you can use any IPMI client to connect to it. Once you give it an IP and password in the BIOS, you can connect to it using your IPMI client of choice. There's also a web interface that provides most of the features of their Java client (I think that uses Java as well, but just for the console).
For our SuperMicro servers, I just use ipmitool from my Linux station and have full access to the console over the network, including booting it into the BIOS, managing the power states, and even connecting to the serial console over the network.
Not sure why you'd consider a full IPMI 2.0 implementation a downside just because the default client sucks.