The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTOverclocking
For our final evaluation of the GTX 1080 and GTX 1070 Founders Edition cards, let’s take a look a overclocking.
Whenever I review an NVIDIA reference card, I feel it’s important to point out that while NVIDIA supports overclocking – why else would they include fine-grained controls like GPU Boost 3.0 – they have taken a hard stance against true overvolting. Overvolting is limited to NVIDIA’s built in overvoltage function, which isn’t so much a voltage control as it is the ability to unlock 1-2 more boost bins and their associated voltages. Meanwhile TDP controls are limited to whatever value NVIDIA believes is safe for that model card, which can vary depending on its GPU and its power delivery design.
For GTX 1080FE and its 5+1 power design, we have a 120% TDP limit, which translates to an absolute maximum TDP of 216W. As for GTX 1070FE and its 4+1 design, this is reduced to a 112% TDP limit, or 168W. Both cards can be “overvolted” to 1.093v, which represents 1 boost bin. As such the maximum clockspeed with NVIDIA’s stock programming is 1911MHz.
| GeForce GTX 1080FE Overclocking | ||||
| Stock | Overclocked | |||
| Core Clock | 1607MHz | 1807MHz | ||
| Boost Clock | 1734MHz | 1934MHz | ||
| Max Boost Clock | 1898MHz | 2088MHz | ||
| Memory Clock | 10Gbps | 11Gbps | ||
| Max Voltage | 1.062v | 1.093v | ||
| GeForce GTX 1070FE Overclocking | ||||
| Stock | Overclocked | |||
| Core Clock | 1506MHz | 1681MHz | ||
| Boost Clock | 1683MHz | 1858MHz | ||
| Max Boost Clock | 1898MHz | 2062MHz | ||
| Memory Clock | 8Gbps | 8.8Gbps | ||
| Max Voltage | 1.062v | 1.093v | ||
Both cards ended up overclocking by similar amounts. We were able to take the GTX 1080FE another 200MHz (+12% boost) on the GPU, and another 1Gbps (+10%) on the memory clock. The GTX 1070 could be pushed another 175MHz (+10% boost) on the GPU, while memory could go another 800Mbps (+10%) to 8.8Gbps.
Both of these are respectable overclocks, but compared to Maxwell 2 where our reference cards could do 20-25%, these aren’t nearly as extreme. Given NVIDIA’s comments on the 16nm FinFET voltage/frequency curve being steeper than 28nm, this could be first-hand evidence of that. It also indicates that NVIDIA has pushed GP104 closer to its limit, though that could easily be a consequence of the curve.
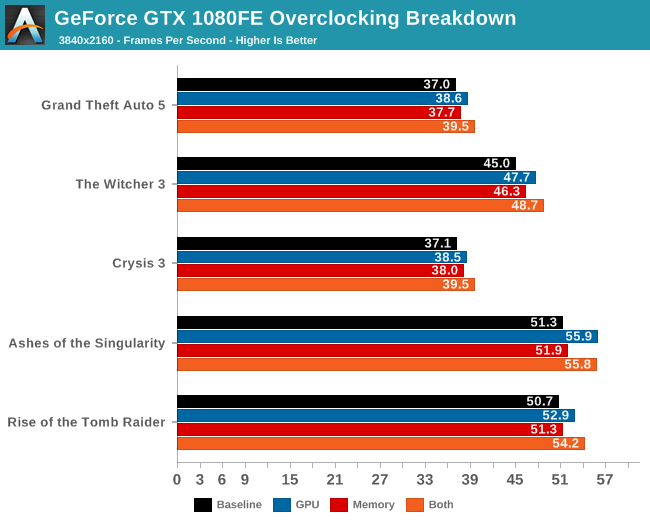
Given that this is our first look at Pascal, before diving into overall performance, let’s first take a look at an overclocking breakdown. NVIDIA offers 4 knobs to adjust when overclocking: overvolting (unlocking additional boost bins), increasing the power/temperature limits, the memory clock, and the GPU clock. Though all 4 will be adjusted for a final overclock, it’s often helpful to see whether it’s GPU overclocking or memory overclocking that delivers the greater impact, especially as it can highlight where the performance bottlenecks are on a card.
To examine this, we’ve gone ahead and benchmarked the GTX 1080 4 times: once with overvolting and increased power/temp limits (to serve as a baseline), once with the memory overclocked added, once with GPU overclock added, and finally with both the GPU and memory overclocks added.
| GeForce GTX 1080 Overclocking Performance | ||||||
| Power/Temp Limit (+20%) | Core (+12%) | Memory (+10%) | Cumulative | |||
| Tomb Raider |
+3%
|
+4%
|
+1%
|
+10%
|
||
| Ashes |
+1%
|
+9%
|
+1%
|
+10%
|
||
| Crysis 3 |
+4%
|
+4%
|
+2%
|
+11%
|
||
| The Witcher 3 |
+2%
|
+6%
|
+3%
|
+10%
|
||
| Grand Theft Auto V |
+1%
|
+4%
|
+2%
|
+8%
|
||
Across all 5 games, the results are clear and consistent: GPU overclocking contributes more to performance than memory overclocking. To be sure, both contribute, but even after compensating for the fact that the GPU overclock was a bit greater than the memory overclock (12% vs 10%), we still end up with the GPU more clearly contributing. Though I am a bit surprised that increasing the power/temperature limit didn't have more of an effect.
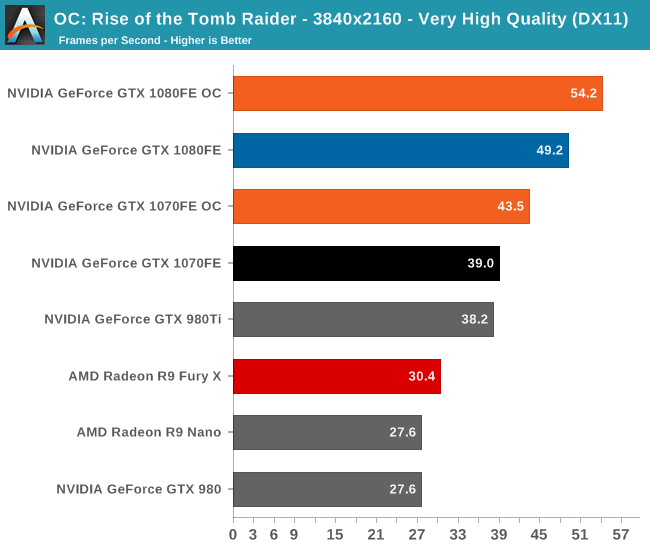
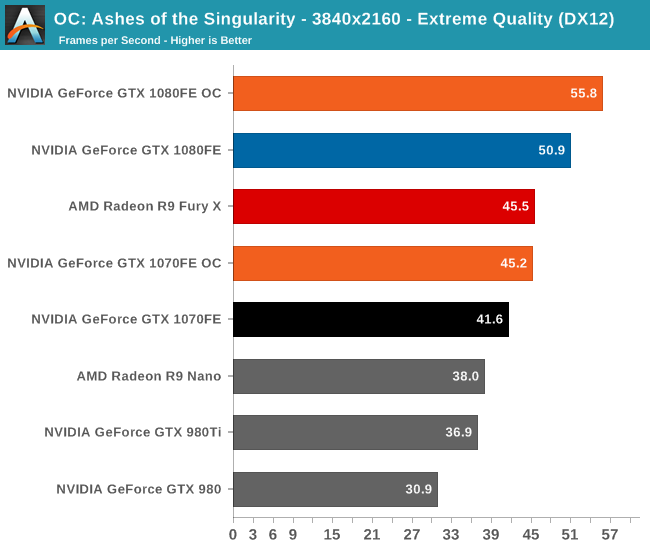
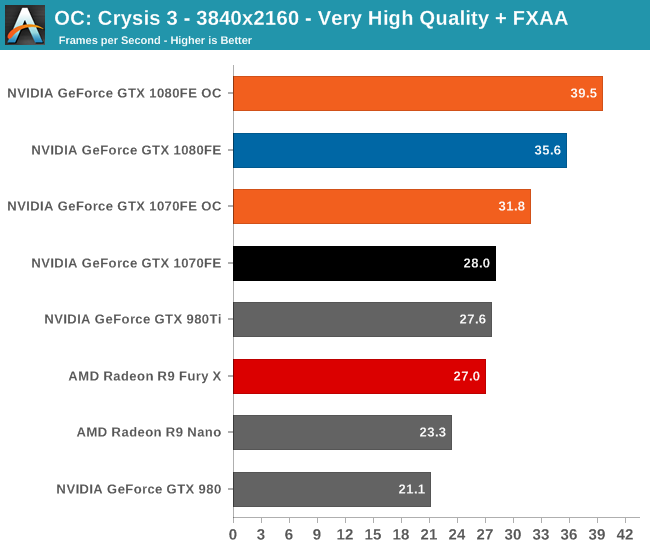
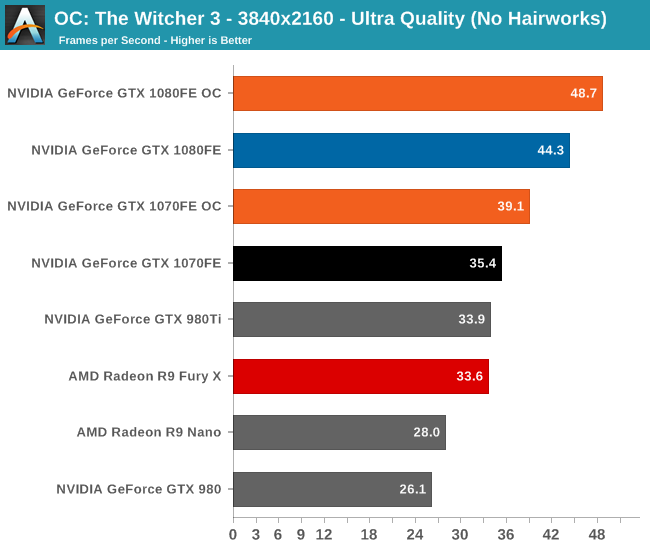
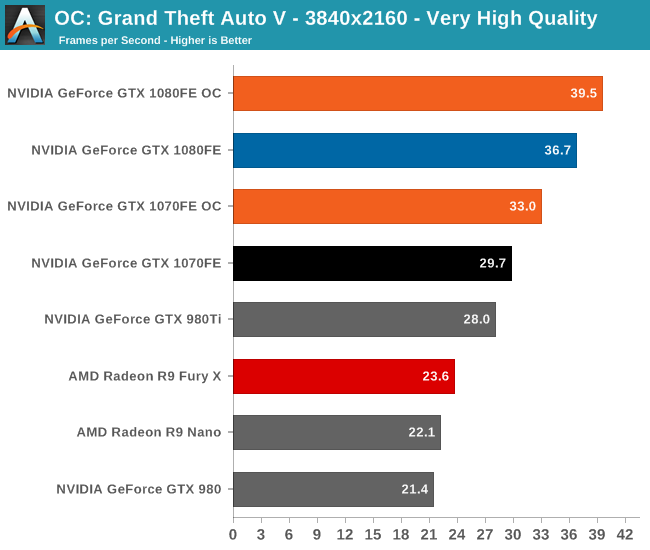
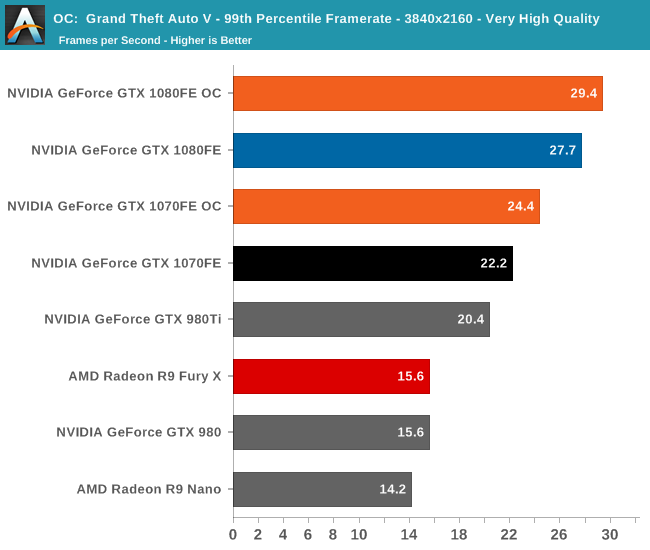
Overall we’re looking at an 8%-10% increase in performance from overclocking. It’s enough to further stretch the GTX 1080FE and GTX 1070FE’s leads, but it won’t radically alter performance.
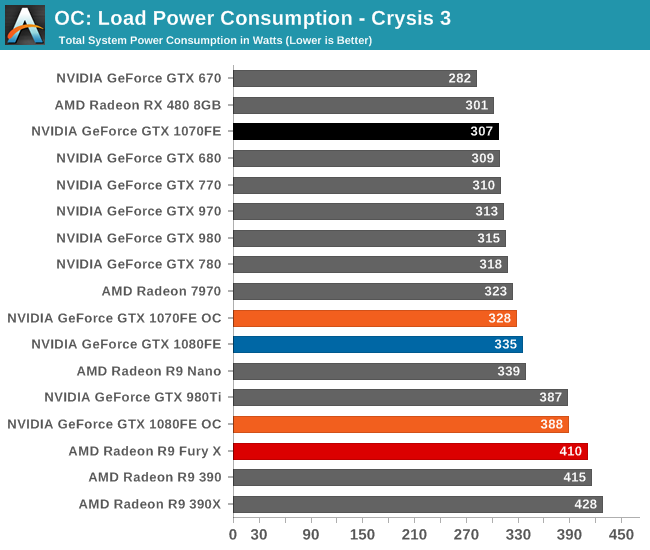
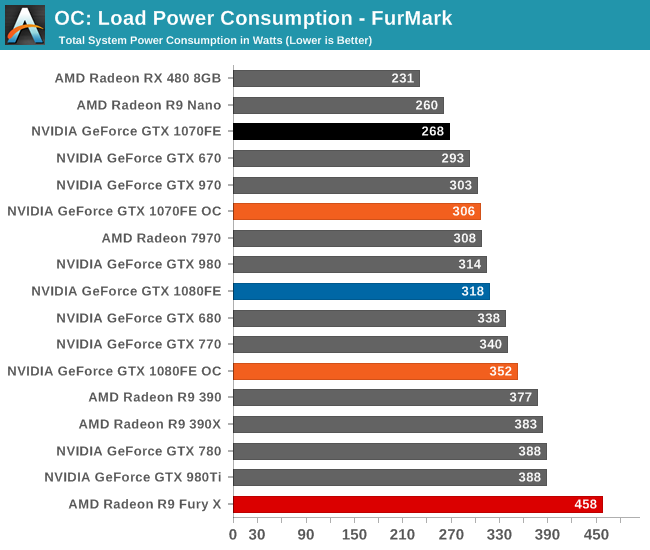
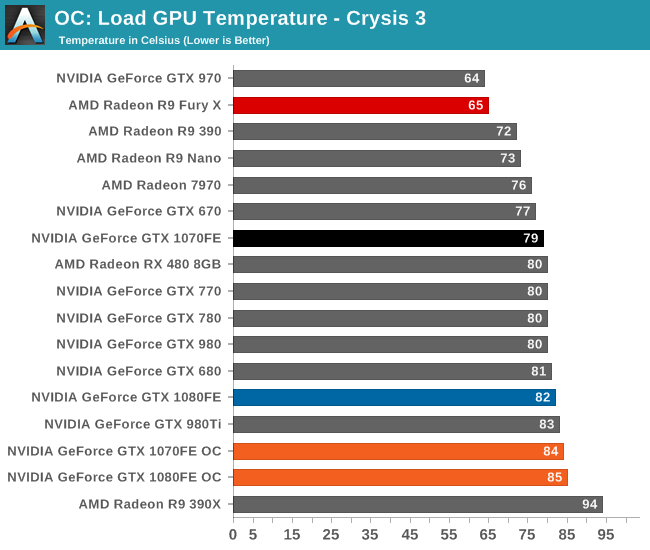
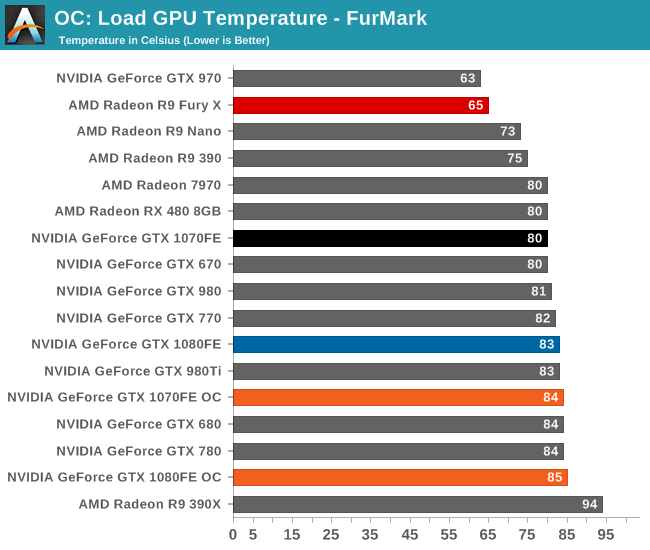
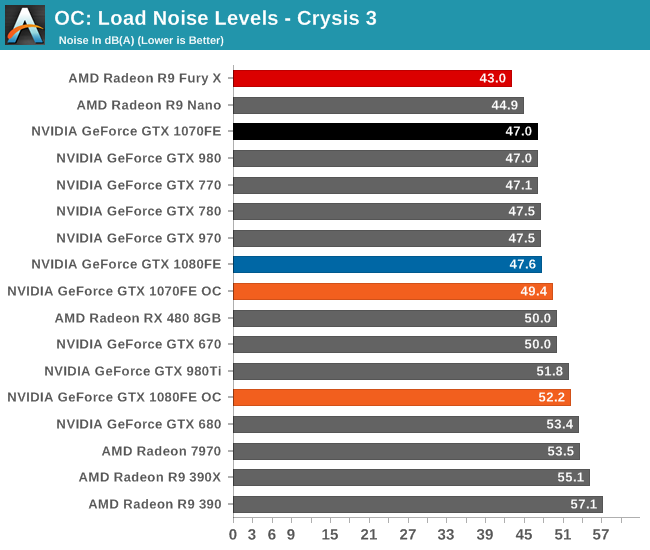
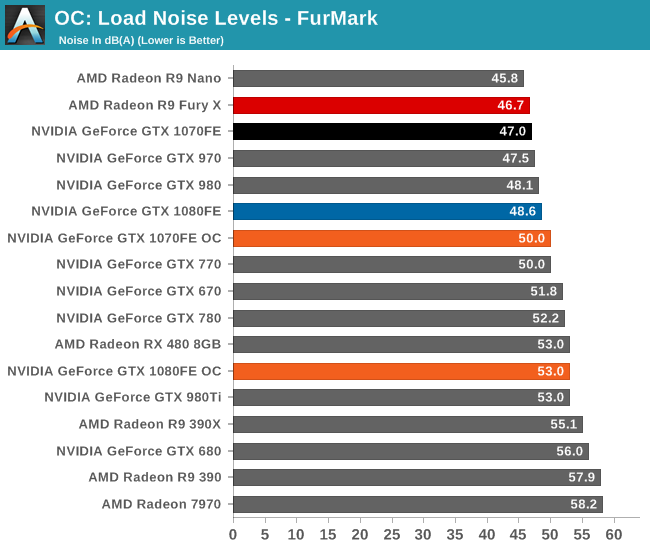
Finally, let’s see the cost of overclocking in terms of power, temperature, and noise. For the GTX 1080FE, the power cost at the wall proves to be rather significant. An 11% Crysis 3 performance increase translates into a 60W increase in power consumption at the wall, essentially moving GTX 1080FE into the neighborhood of NVIDIA’s 250W cards like the GTX 980 Ti. The noise cost is also not insignificant, as GTX 1080FE has to ramp up to 52.2dB(A), a 4.6dB(A) increase in noise. Meanwhile FurMark essentially confirms these findings, with a smaller power increase but a similar increase in noise.
As for the GTX 1070FE, neither the increase in power consumption nor noise is quite as high as GTX 1080FE, though the performance uplift is also a bit smaller. The power penalty is just 21W at the wall for Crysis 3 and 38W for FurMark. This translates to a 2-3dB(A) increase in noise, topping out at 50.0dB for FurMark.








200 Comments
View All Comments
patrickjp93 - Wednesday, July 20, 2016 - link
That doesn't actually support your point...Scali - Wednesday, July 20, 2016 - link
Did I read a different article?Because the article that I read said that the 'holes' would be pretty similar on Maxwell v2 and Pascal, given that they have very similar architectures. However, Pascal is more efficient at filling the holes with its dynamic repartitioning.
mr.techguru - Wednesday, July 20, 2016 - link
Just Ordered the MSI GeForce GTX 1070 Gaming X , way better than 1060 / 480. NVidia Nail it :)tipoo - Wednesday, July 20, 2016 - link
" NVIDIA tells us that it can be done in under 100us (0.1ms), or about 170,000 clock cycles."Is my understanding right that Polaris, and I think even earlier with late GCN parts, could seamlessly interleave per-clock? So 170,000 times faster than Pascal in clock cycles (less in total time, but still above 100,000 times faster)?
Scali - Wednesday, July 20, 2016 - link
That seems highly unlikely. Switching to another task is going to take some time, because you also need to switch all the registers, buffers, caches need to be re-filled etc.The only way to avoid most of that is to duplicate the whole register file, like HyperThreading does. That's doable on an x86 CPU, but a GPU has way more registers.
Besides, as we can see, nVidia's approach is fast enough in practice. Why throw tons of silicon on making context switching faster than it needs to be? You want to avoid context switches as much as possible anyway.
Sadly AMD doesn't seem to go into any detail, but I'm pretty sure it's going to be in the same ballpark.
My guess is that what AMD calls an 'ACE' is actually very similar to the SMs and their command queues on the Pascal side.
Ryan Smith - Wednesday, July 20, 2016 - link
Task switching is separate from interleaving. Interleaving takes place on all GPUs as a basic form of latency hiding (GPUs are very high latency).The big difference is that interleaving uses different threads from the same task; task switching by its very nature loads up another task entirely.
Scali - Thursday, July 21, 2016 - link
After re-reading AMD's asynchronous shader PDF, it seems that AMD also speaks of 'interleaving' when they switch a graphics CU to a compute task after the graphics task has completed. So 'interleaving' at task level, rather than at instruction level.Which would be pretty much the same as NVidia's Dynamic Load Balancing in Pascal.
eddman - Thursday, July 21, 2016 - link
The more I read about async computing in Polaris and Pascal, the more I realize that the implementations are not much different.As Ryan pointed out, it seems that the reason that Polaris, and GCN as a whole, benefit more from async is the architecture of the GPU itself, being wider and having more ALUs.
Nonetheless, I'm sure we're still going to see comments like "Polaris does async in hardware. Pascal is hopeless with its software async hack".
Matt Doyle - Wednesday, July 20, 2016 - link
Typo in the lead sentence of HPC vs. Consumer: Divergence paragraph: "Pascal in an architecture that...""is" instead of "in"
Matt Doyle - Wednesday, July 20, 2016 - link
Feeding Pascal page, "GDDR5X uses a 16n prefetch, which is twice the size of GDDR5’s 8n prefect."Prefect = prefetch