The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTAshes of the Singularity
Sorely missing from our benchmark suite for quite some time have been RTSes, which don’t enjoy quite the popularity they once did. As a result Ashes holds a special place in our hearts, and that’s before we talk about the technical aspects. Based on developer Oxide Games’ Nitrous Engine, Ashes has been designed from the ground up for low-level APIs like DirectX 12. As a result of all of the games in our benchmark suite, this is the game making the best use of DirectX 12’s various features, from asynchronous compute to multi-threadeded work submission and high batch counts. What we see can’t be extrapolated to all DirectX 12 games, but it gives us a very interesting look at what we might expect in the future.
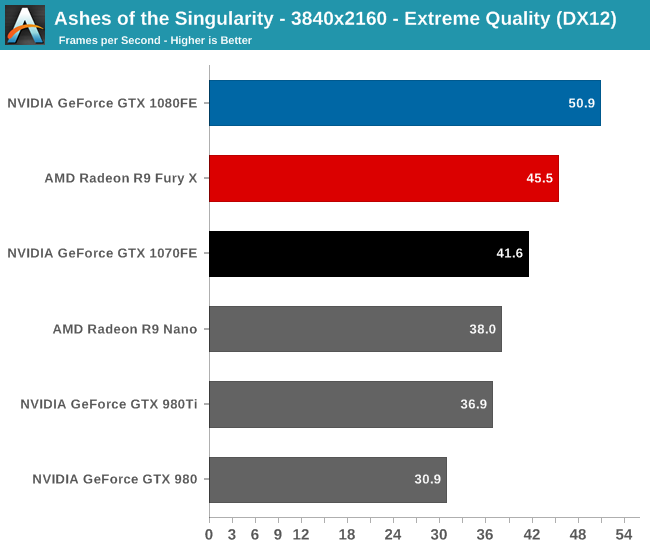
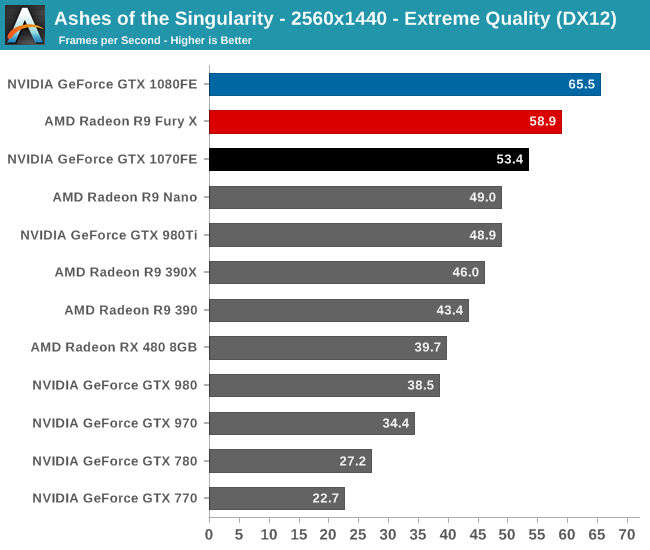

Once again the top spot is uncontested by the GTX 1080. However after that, things become more interesting. On the whole, Ashes is a game that favors AMD GPU over NVIDIA GPUs, and as a result the GTX 1070 does not get to lock in second place. Rather that goes to the last generation Fury X. AMD designs are very ALU-heavy, and I suspect Ashes is capable of putting those ALUs to good use, something most other games struggle with. That said, if we normalized this for price or power consumption, then the Pascal cards would be well in the lead, but it does show that on an absolute basis, GTX 1070 isn’t going to outrun the best of the last-gen cards all the time.
Meanwhile it’s interesting to note that one of the more unusual aspects of the engine behind Ashes is that it’s relatively resolution insensitive. That is, performance only drops moderately as we increase the resolution. This means that we need a GTX 1070 to sustain better than 60fps at 1080p, but that same card is still getting better than 40fps at 4K, a resolution with 4x the pixels.
Finally, looking at our NVIDIA cards on a generational basis, even without their commanding lead, the two Pascal cards show the expected generational gains. GTX 1080 improves on GTX 980 by between 65% and 70%, and GTX 1070 improves on GTX 970 by between 53% and 58%.








200 Comments
View All Comments
TestKing123 - Wednesday, July 20, 2016 - link
Then you're woefully behind the times since other sites can do this better. If you're not able to re-run a benchmark for a game with a pretty significant patch like Tomb Raider, or a high profile game like Doom with a significant performance patch like Vulcan that's been out for over a week, then you're workflow is flawed and this site won't stand a chance against the other crop. I'm pretty sure you're seeing this already if you have any sort of metrics tracking in place.TheinsanegamerN - Wednesday, July 20, 2016 - link
So question, if you started this article on may 14th, was their no time in the over 2 months to add one game to that benchmark list?nathanddrews - Wednesday, July 20, 2016 - link
Seems like an official addendum is necessary at some point. Doom on Vulkan is amazing. Dota 2 on Vulkan is great, too (and would be useful in reviews of low end to mainstream GPUs especially). Talos... not so much.Eden-K121D - Thursday, July 21, 2016 - link
Talos Principle was a proof of conceptajlueke - Friday, July 22, 2016 - link
http://www.pcgamer.com/doom-benchmarks-return-vulk...Addendum complete.
mczak - Wednesday, July 20, 2016 - link
The table with the native FP throughput rates isn't correct on page 5. Either it's in terms of flops, then gp104 fp16 would be 1:64. Or it's in terms of hw instruction throughput - then gp100 would be 1:1. (Interestingly, the sandra numbers for half-float are indeed 1:128 - suggesting it didn't make any use of fp16 packing at all.)Ryan Smith - Wednesday, July 20, 2016 - link
Ahh, right you are. I was going for the FLOPs rate, but wrote down the wrong value. Thanks!As for the Sandra numbers, they're not super precise. But it's an obvious indication of what's going on under the hood. When the same CUDA 7.5 code path gives you wildly different results on Pascal, then you know something has changed...
BurntMyBacon - Thursday, July 21, 2016 - link
Did nVidia somehow limit the ability to promote FP16 operations to FP32? If not, I don't see the point in creating such a slow performing FP16 mode in the first place. Why waste die space when an intelligent designer can just promote the commands to get normal speeds out of the chip anyways? Sure you miss out on speed doubling through packing, but that is still much better than the 1/128 (1/64) rate you get using the provided FP16 mode.Scali - Thursday, July 21, 2016 - link
I think they can just do that in the shader compiler. Any FP16 operation gets replaced by an FP32 one.Only reading from buffers and writing to buffers with FP16 content should remain FP16. Then again, if their driver is smart enough, it can even promote all buffers to FP32 as well (as long as the GPU is the only one accessing the data, the actual representation doesn't matter. Only when the CPU also accesses the data, does it actually need to be FP16).
owan - Wednesday, July 20, 2016 - link
Only 2 months late and published the day after a different major GPU release. What happened to this place?