Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
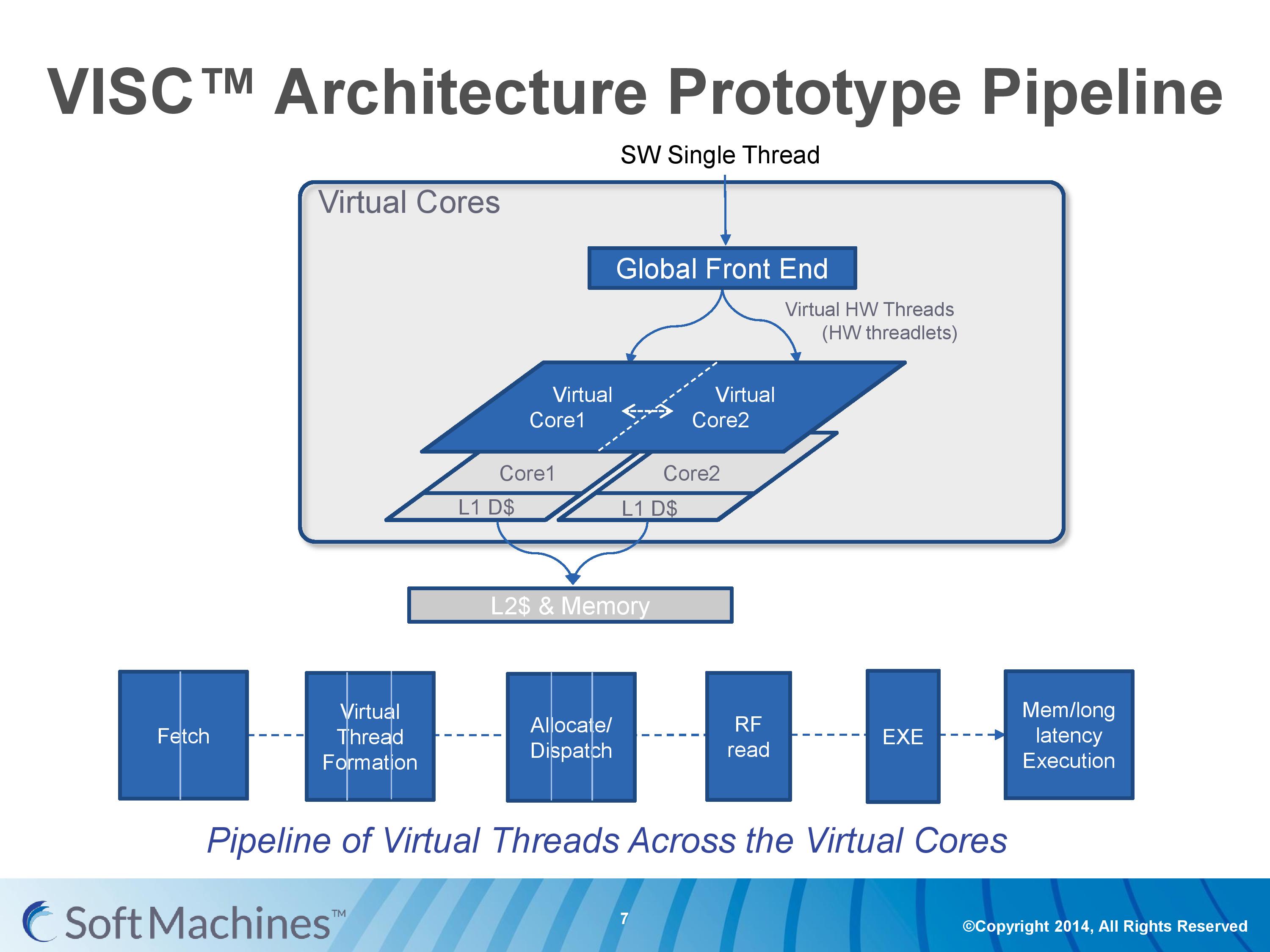
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
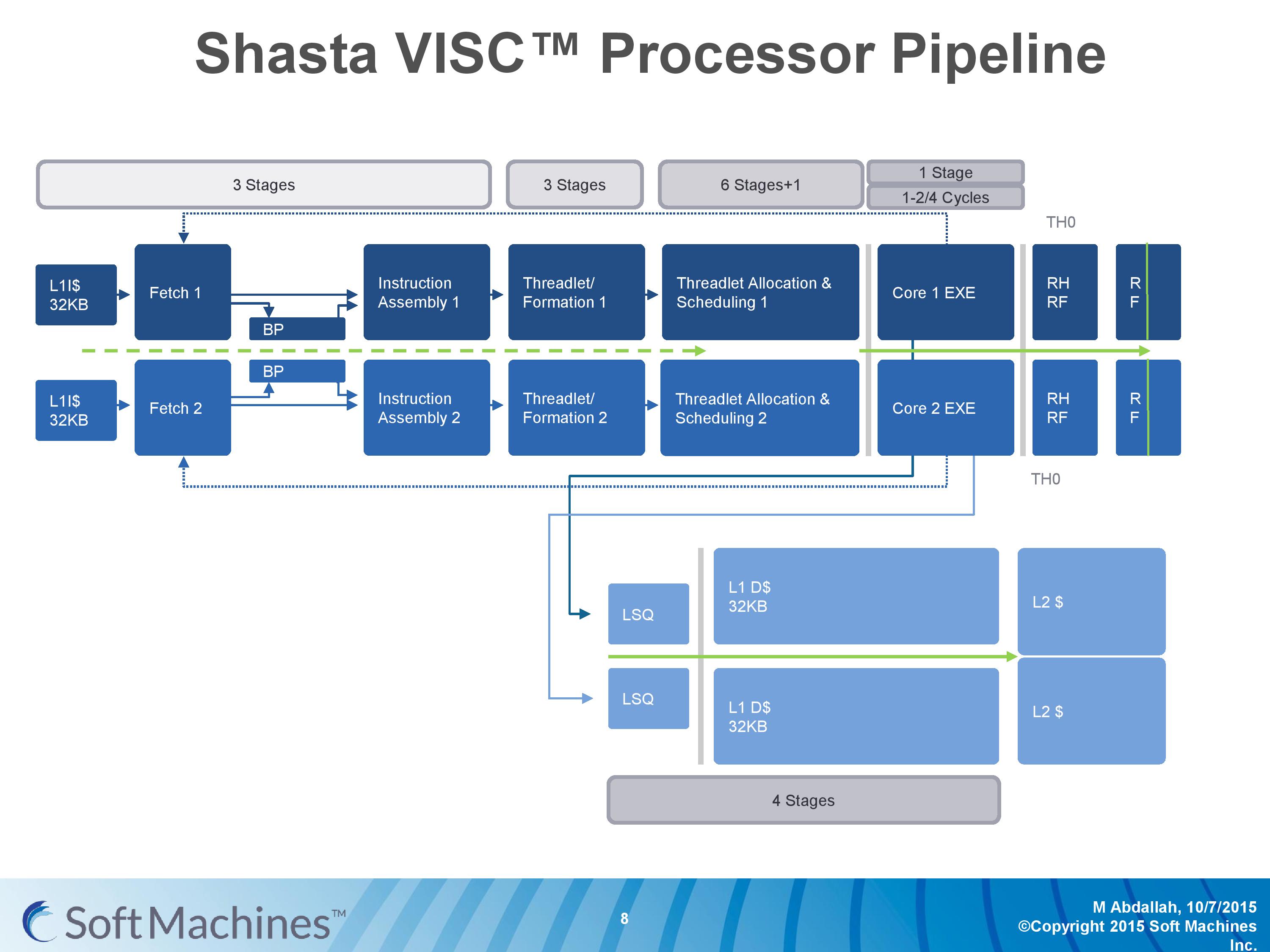
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
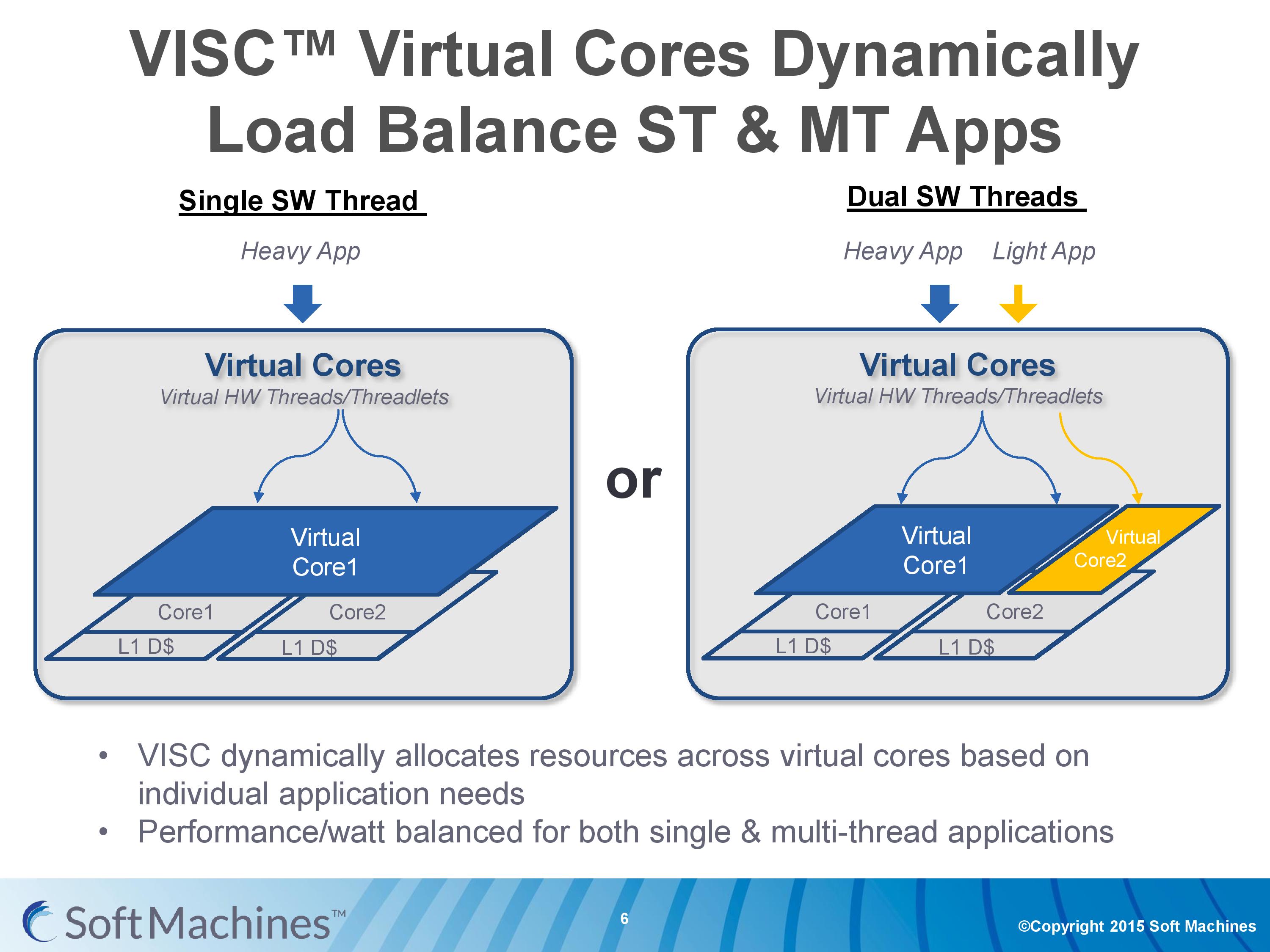
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
kgardas - Saturday, February 13, 2016 - link
Market is not dominated by excellent technology, but by average or mediocre in fact. "Good enough" is enemy of any excellence.Also in comparison with AMD64 which is just pile of hacks to prolong x86 architecture life, IA-64 was clean design on green field and its really a pity Intel can't push that further -- also due to AMD64 existence in the market.
Alexvrb - Monday, February 15, 2016 - link
That kind of thinking is what lead to the Itanic, the unsinkable chip. Too bad they ran afoul of a giant costberg.But no, you're right, everyone should switch to a new ISA because Intel says it's better, even though it means switching to an Intel-exclusive ISA that will cost you dearly now, and even more dearly later when you become dependent on a product that only Intel can produce.
If Intel's only desire was a better design for everyone, they would have worked with AMD and freely extended licensing agreements to IA-64 to them so they could both produce IA-64 chips. The outcome could have very well been different in that scenario. But that is not what they did, and they paid for it. Of course, Intel is such a giant that they can afford to take such failures in stride. AMD can not afford another flop - Zen, Polaris, and eventually a ZenPolaris APU have to achieve at least a significant degree of success.
FunBunny2 - Monday, February 15, 2016 - link
-- Of course, Intel is such a giant that they can afford to take such failures in stride.the irony, of course, is that Intel got where it is just because, in ~1980, Intel had one foot in chapter 7 and one foot on a banana peel. IOW, an easy controlled peon for IBM to abuse, thus the 8088 came to be. if IBM had secured the BIOS, life for both would have turned out rather differently, I suspect.
Alexvrb - Monday, February 15, 2016 - link
Yeah that is ironic. Intel was trying to avoid making a similar mistake, and in doing so they screwed up - but the SIZE of the failure was tiny in comparison. One thing about Intel is that they have better foresight and planning than IBM. IBM always was caught up in their own world. Intel probably was working on backup plans for Itanium failure before it even launched, regardless of how high they thought its chances were.diediealldie - Friday, February 12, 2016 - link
Thanks for great article.Anyway, I'd wait for actual working silicon with high frequency(Not .5Ghz) to figure out if it's real or not.
Since they're making abstraction layer with real silicon, demonstrating it on slow chip will not enough to convince industry experts(Hardware will be complicated so making it work on very high frequency is also big challenge).
High freqency chips requires more pipeline thus latencies and cache efficiency gets worse, hardware blocks not working...etc. so high frequeny chip is what Shasta really have to demonstrate.
dcbronco - Friday, February 12, 2016 - link
Interesting that AMD are switching to SMT with Zen and are one of the big financers of Soft Machines and VISC works well with SMT. I also wonder if an OS written for VISC would give a boost to APUs or would the bottlenecks kill any advantage.zodiacfml - Saturday, February 13, 2016 - link
Interesting as numerous patents created can be beneficial to other CPU makers but for them creating a compelling chip that could sell would be miraculous.haplo602 - Saturday, February 13, 2016 - link
Lots of marketing and even more estimates and projections. Looks like a very long road ahead to actual working chip with peripherals. And a lot of obstacles still to clear.While the idea is interesting, it is highly impractical. The higher frequency they'll go, the more the final compositing overhead will bite them. There's a cost traversing the layers of the design from thread to CPU and back with results. I do not see that explained anywhere.
Another point is, I think this is not a new idea. It is fairly obvious an extension so expect Intel already went that route and met a dead-end.
vladx - Sunday, February 14, 2016 - link
Intel are too conservative to come with such ideas, they'd rather milk the cow as long as possible.hMunster - Sunday, February 14, 2016 - link
There's one important question I don't see addressed, how do you run at higher IPCs when you have a conditional branch every few instructions? A 16-wide virtual CPU using 4 physical cores is all nice and dandy, but 16 instructions will, in normal x85 code, contain at least 2 branches. I can't see them doing a lot of speculative execution because that drives up the power consumption. So how do they solve this?