Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Soft Machines
To put it succinctly, having a thread take resources from multiple cores - when the performance can be extracted - sounds like the long-desired solution to the problem making multi-core designs more useful in lightly-threaded scenarios. Having multiple threads use resources on a single core on the same clock cycle is an even bigger leap in the same direction. Now obviously Soft Machines didn’t come up with this overnight.

Soft Machines came out of stealth mode at the 2014 Linley Conference. Their main goal was to increase performance-per-watt using better IPC designs, which is often one of the better ways if you can keep a design fed with data. One big challenge to this is that IPC has been somewhat flat these past few years - we're seeing small sub-10% yearly increases from the big players using standard designs. Soft Machines were already six years old at the time, with $150M+ raised from investors that include Samsung Ventures, GlobalFoundries, AMD, Mubadala and others (with another $25M since). If those names all seem interlinked, it’s because they all have historic business or investment dealings with each other (AMD/GloFo, Samsung/GloFo, AMD/Mubadala etc.). The team at Soft Machines is 250+ strong, with ex Intel, ex Qualcomm, ex AMD engineers on staff from processor design to platform architects. Half the staff is currently located in California.
At the 2014 conference, aside from explaining what they were doing, Soft Machines also exhibited working silicon of their design. The first generation proof of concept was fabbed at 28nm at TSMC and running at 500 MHz.

It seems odd to say that it was done at TSMC, especially with Samsung and Global Foundries as investors. We were told that this was due to timing and positioning with IP more than anything else, and the same is true for the next generation at 16nm FF+, rather than 14nm.
VISC and Roadmaps
The first generation chip wasn’t perfect – there were some design flaws in silicon that required specific workarounds relating to cache flushing and various methods, but at the time it was compared to a single thread Cortex A15 running at a similar frequency in a Samsung processor. The results with SPEC2000, SPEC2006, Denbench and Kraken gave a corresponding IPC relative to A15 of 1.5x to 7x, or as Soft Machines likes to put it: 3-4x "on average." It was estimated that access to a second physical core improves performance by an average of 50-60%, or an average IPC of 1.3 per core compared to 0.71 for Cortex A15, which explains the 3-4x average.
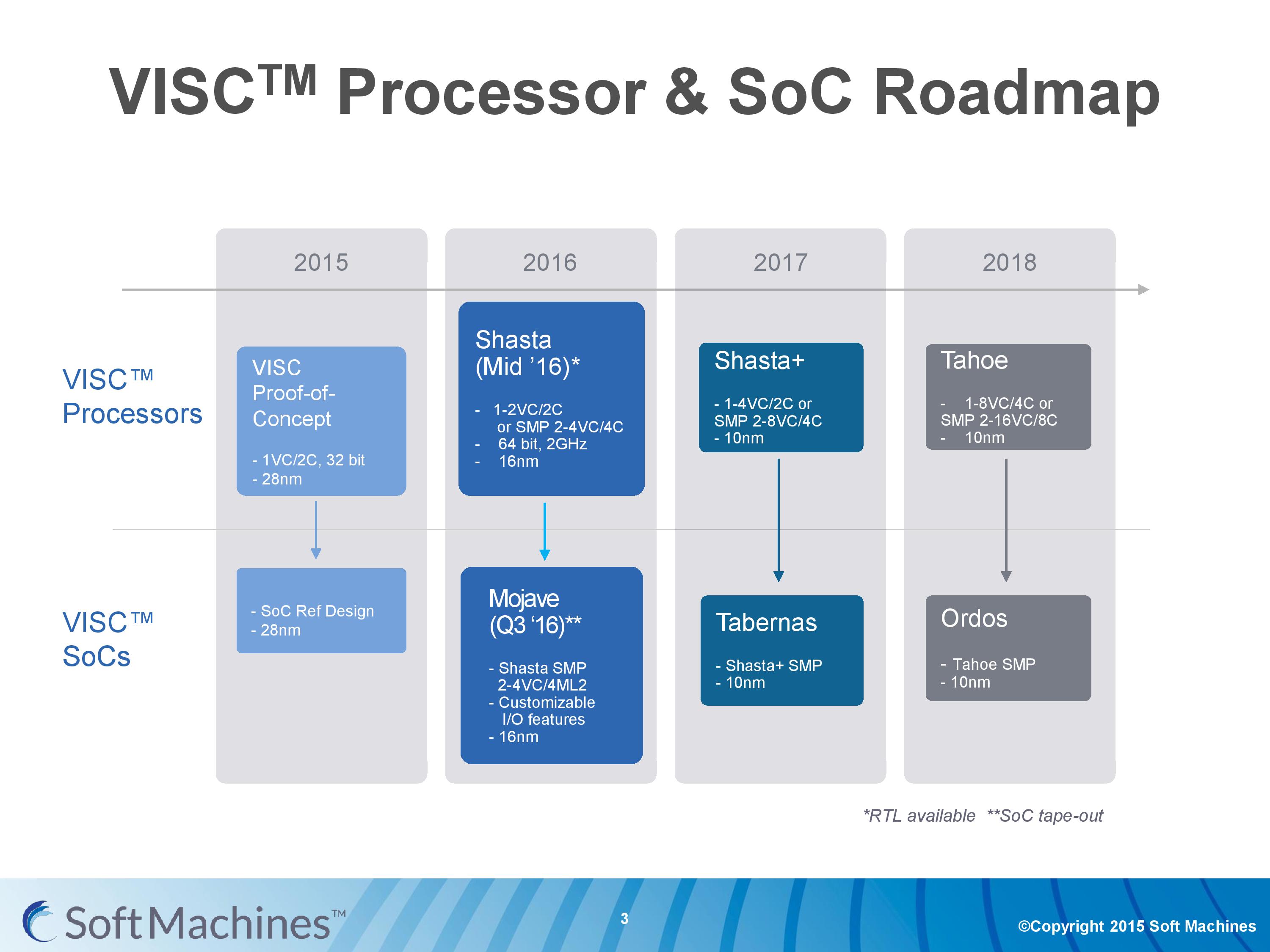
The roadmap for Soft Machines put their second generation VISC core, Shasta, in line for 2016. It was formally announced at the 2015 Linley Conference, with this month’s announcement being more about availability for licensing on 16FF+. The Shasta core on this node is designed as a 2C/2VC design, or two of these can be put together using a custom protocol interconnect to form a dual 2C/2VC design.
The custom interconnect fabric here is capable of over 200 GB/s, although in current designs only a single interface is present, allowing only two chips to be connected.
The dual processor design is going to be part of the Mojave IP as a fully integrated SoC.
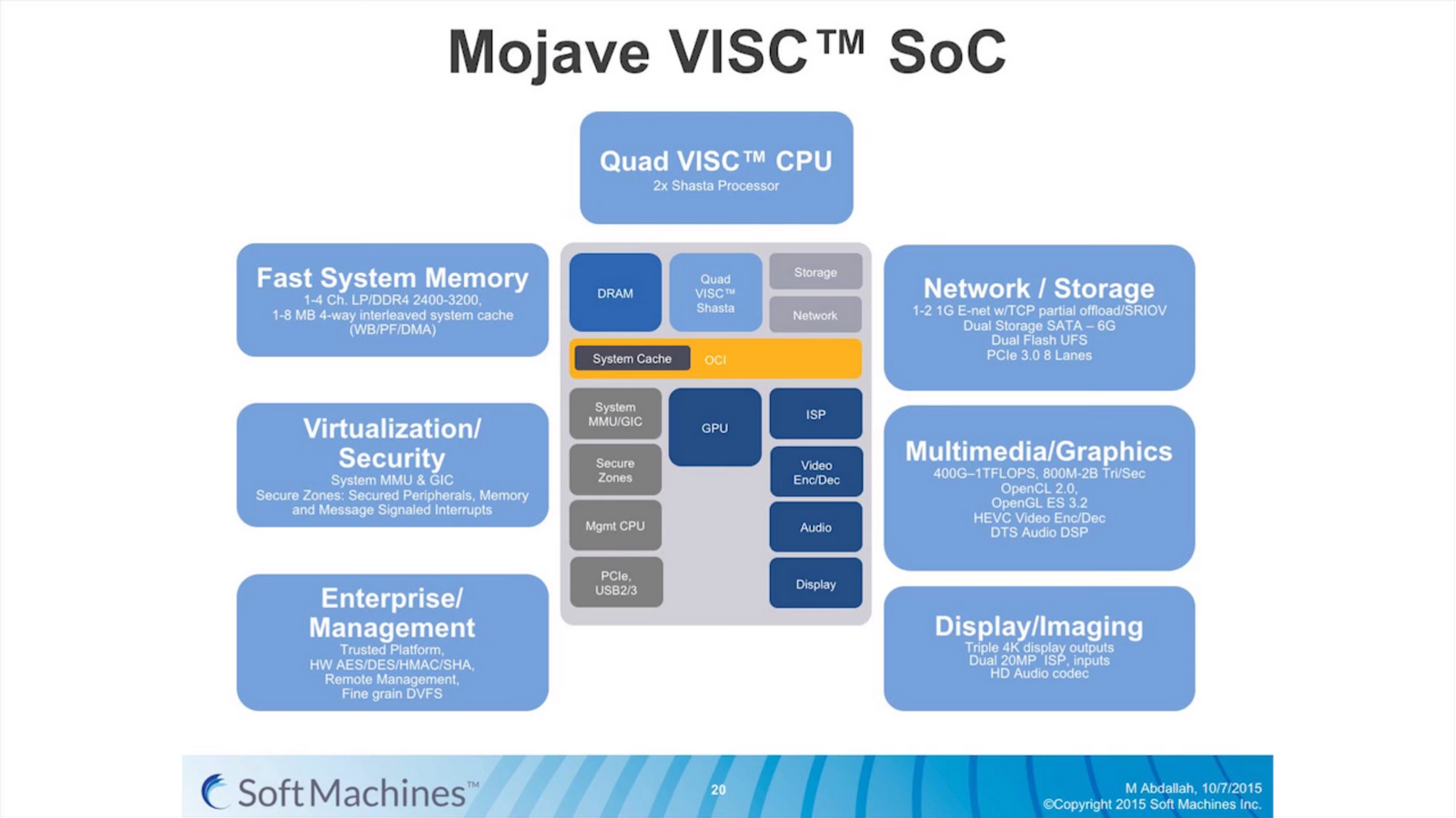
Along with the requisite VISC cores, the Mojave SoC includes PowerVR graphics, a DDR4 memory controller, virtualization management, a PCIe root complex capable of eight lanes of PCIe 3.0, USB ports, support for SATA, UFS, OpenCL 2.0 and other standards.
Looking forward, Soft Machines would like to see production move to 10nm in 2017 to take advantage of further power and area scaling. Meanwhile along that same timeframe they also want to expand the Shasta design to allow for four virtual cores per two physical cores, essentially allowing more threads to be in flight at one time and fully use the resources better. 2018 sees the move to four physical cores and eight virtual cores per design, while still supporting SMP and SoC designs as well.








97 Comments
View All Comments
xdrol - Saturday, February 13, 2016 - link
I somehow fail to see why should be scheduling 2 threads to 2 cores of 4-wide pipelines - including overhead from 'in-thread' cross-core communication - should be more effective than a 2-thread 8-wide SMT core (aka Skylake - it's not 6-wide, and SMT is fine-grained, threads don't 'wait' like the article suggests)Alexvrb - Saturday, February 13, 2016 - link
Right! It's like getting the best of narrow and wide designs at the same time. You can go wide or narrow and more/less threads as needed. It'll probably need a lot of OS support to work well. Still, the concept is interesting, and if their translation layer is fast, it could eventually handle legacy well enough.FunBunny2 - Saturday, February 13, 2016 - link
-- You can go wide or narrow and more/less threads as needed.but no known processor (or design algorithm) can create parallelism in serial code. just because a cpu wants to implement ILP to a greater extent than extant processors, it can't make parallel from nothing; it can only discover "hidden" parallel that extant processors are missing. not something I'd bet on.
Alexvrb - Sunday, February 14, 2016 - link
I was talking about the processor itself. The CPU can act like a wide or narrow design on demand. Whether or not a particular piece of code will benefit was not something I was discussing. My point is that where it helps, it can go wider than current designs. Where it doesn't help it can scale back and go narrow, leaving more cores available for other threads.In other words this doesn't displace multi-threading. A single piece of demanding software may still want to run multiple threads concurrently, to indirectly extract more parallel performance - such as a game splitting up AI, physics, audio, rendering, networking, etc into their own threads. I don't think their design eliminates the necessity of doing this sort of thing.
However they can boost average efficiency with a narrow design and lots of cores (similar to mobile ARM designs), without losing performance vs high-power designs (and in some cases gaining performance) because they can act as a wide pipeline by combining cores It's a flexible form of virtual cores that people will tend to just simplify as "reverse HyperThreading".
This is all just in theory of course, their implementation has to prove itself. Not to mention the difficulties they'll face with ISA translation, at least in the near term. If their technology takes off and gets licensed out, there will be ports of modern OS and APIs, and thus apps will be ported to run native (in the case of Windows, cloud compilation would handle the majority of RunTime apps).
Samus - Monday, February 15, 2016 - link
If the translation layer does what they say it does, that is exactly what this processor can do. It can break up serial code for parallel processing. I don't know how, or how efficient, it can do this. To analyze serial code and say ohh, so there's this complex part in the middle and the rest is simple, and send the complex part to one core and the rest to another, and somehow reassemble it after its processed, seems impossible. We have all seen promising tech flop before, Cyrix and Transmetta had some radical ideas for the way x86 worked, in the end neither could trump Intel or AMD.Alexvrb - Monday, February 15, 2016 - link
What he was saying is that some code can NOT be made parallel. They CAN take single threads and break them up, and when it's possible they can find parallel processing opportunities. But some tasks are inherently serial. Neither the programmer, nor the compiler, nor the VISC processor can make inherently serial tasks parallel. For example, if A has to happen before you can work on B.Uh, at least not with a conventional binary architecture. I don't know much about quantum processors.
easp - Friday, February 12, 2016 - link
I think uninformed pundits/press/commenters will miss the limits imposed by Amdahl's law.Its still plausible to me though that this approach will allow more efficient use of silicon and power by allowing better allocation of processor resources at runtime than is possible with traditional compilers, operating system scheduling, hardware scheduling and organization of execution resources.
Whether they can establish a viable foothold in todays competitive landscape is another issue.
Sufiyan - Saturday, February 13, 2016 - link
If anything this shows that Amdahls law is still true.Bleakwise - Tuesday, March 14, 2017 - link
They never said it violates Amdahl's law.I fact they said that 2 cores gives a speedup of 53%.
Amdahl's law says it would be a 100% speedup maximum.
Since when is 53% > 100%?
Bleakwise - Tuesday, March 14, 2017 - link
Of course, it does beg the question...Why don't we just make 24 wide CPU pipelines and allow for 3-way SMT and fatten the cores up with more units instead?