NVIDIA’s Maximus Technology: Quadro + Tesla, Launching Today
by Ryan Smith on November 14, 2011 9:00 AM ESTNVIDIA’s Maximus Technology – Quadro + Tesla, Launching Today
Back at SIGGRAPH 2011 NVIDIA announced Project Maximus, an interesting technology initiative to allow customers to combine Tesla and Quadro products together in a single workstation and to use their respective strengths. At the time NVIDIA didn’t have a launch date to announce, but as this is a software technology rather than a hardware product, the assumption has always been that it would be a quick turnaround. And a quick turnaround it has been: just over 3 months later NVIDIA is officially launching Project Maximus as NVIDIA Maximus Technology.

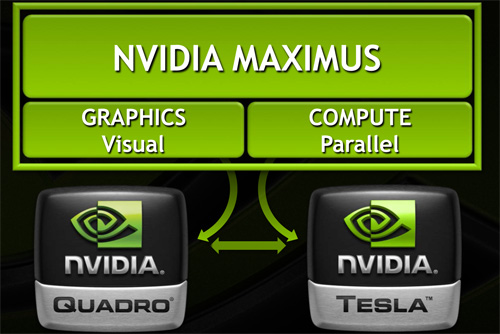
So what is Maximus Technology? As NVIDIA likes to reiterate to their customers it’s not a new product, it’s a new technology – a new way to use NVIDIA’s existing Quadro and Tesla products together. There’s no new hardware involved, just new features in NVIDIAs drivers and new hooks exposed to application developers. Or put more succinctly, in the same vein that Optimus was a driver technology to allow the transparent combination of NVIDIA mobile GPUs with Intel IGPs, Maximus is a driver technology to allow the transparent combination of NVIDIA’s Quadro and Tesla products.
With Maximus NVIDIA is seeking to do a few different things, all of which come back to a single concept: utilizing Quadro and Tesla cards together at the tasks they’re best suited at. This means using Quadro cards for graphical tasks while using Tesla for compute tasks where direct graphical rendering isn’t necessary. Ultimately this seems like an odd concept at first – high end Quadros are fully compute capable too – but it’s something that makes more sense once we look at the current technical limitations of NVIDIA’s hardware, and what use cases they’re proposing.
Combining Quadro & Tesla: The Technical Details
The fundamental base of Maximus is NVIDIA’s drivers. For Maximus NVIDIA needed to bring Quadro and Tesla together under a single driver, as they previously used separate drivers. NVIDIA has used a shared code base for many years now, so Tesla and Quadro (and GeForce) were both forks of the same drivers, but those forks needed to be brought together. This is harder than it sounds as while Quadro drivers are rather straightforward – graphical rendering without all the performance shortcuts and with support for more esoteric features like external synchronization sources – Tesla has a number of unique optimizations, primarily the Tesla Compute Cluster driver, which moved Tesla out from under Windows’ control as a graphical device.
The issue with the forks had to be resolved, and the result was that NVIDIA was finally able to merge the codebase back into a single Quadro/Tesla driver as of July with the 275.xx driver series.
But this isn’t just about combining driver codebases. Making Tesla and Quadro work in a single workstation resolves the hardware issues but it leaves the software side untouched. For some time now CUDA developers have been able to select what device to send a compute task to in a system with multiple CUDA devices, but this is by definition an extra development step. Developers had to work in support for multiple CUDA devices, and in most cases needed to expose controls to the user so that users could make the final allocations. This works well enough in the hands of knowledgeable users, but NVIDIA’s CUDA strategy has always been about pushing CUDA farther and deeper in the world in order to make it more ubiquitous, and this means it always needs to become easier to use.
This brings us back to Optimus. With Optimus NVIDIA’s goal was to replace manual GPU muxing with a fully transparent system so that users never needed to take any extra steps to use a mobile GeForce GPU alongside Intel’s IGPs, or for that matter concern themselves with what GPU was being used. Optimus would – and did – take care of it all by sending lightweight workloads to the IGP while games and certain other significant workloads were sent to the NVIDIA GPU.
Maximus embodies a concept very similar to this, except with Maximus it’s about transparently allocating compute workloads to the appropriate GPU. With a unified driver base for Tesla and Quadro, NVIDIA’s drivers can present both devices to an application as usable CUDA devices. Maximus takes this to its logical conclusion by taking the initiative to direct compute workloads to the Tesla device; CUDA device allocation becomes a transparent operation to users and developers alike, just like GPU muxing under Optimus. Workloads can of course still be manually controlled, but at the end of the day NVIDIA wants developers to sit back and do nothing, and leave device allocation up to NVIDIA.
As with Optimus, NVIDIA’s desires here are rather straightforward: the harder something is to use, the slower the adoption. Optimus made it easier to get NVIDIA GPUs in laptops, and Maximus will make it easier to get CUDA adopted by more programs. Requiring developers to do any extra work to use CUDA is just one more thing that can go wrong and keep CUDA from being implemented, which in turn removes a reason for hardware buyers to purchase a high-end NVIDIA product.








29 Comments
View All Comments
chandan1014 - Monday, November 14, 2011 - link
Can NVIDIA give us at least a timeline when to expect optimus for desktops? Current sandy bridge processors have powerful enough graphics unit for general computing and I really would like to see, let's say, a GTX 580 to power down when I'm surfing the web.GoodBytes - Monday, November 14, 2011 - link
You don't want Optimus.Optimus uses the system bus (which you only have 1 from the CPU to memory), to send rendered frame from the GPU to the Intel memory reserved space. As the bus can only be used by 1 at a time.. this means you'll get a large reduction in CPU power. Basically creating bottleneck. The more demanding the game, the less CPU power you have.. which will slow down the game, unless you kill anything from the game that uses the CPU.
This the major downside of Optimus.
If you want to control your GPU performance (which already does via Nvidia PowerMizer technology, which clocks the GPU based on it's work load), you can install Nvidia System Tools, and have look at Nvidia Control Panel. A new section"Performance" will appear and you can create profiles to switch form by double click on them, which has the performance specification set by you.
Or
you can use many overclock tools out there for your GPU, but instead of overclocking, you switch between normal default speed (let's say you don't want to overclock), and minimum speed, and switch between mode via keyboard shortcuts or something.
tipoo - Monday, November 14, 2011 - link
I've never seen any benchmarks indicating Optimus slows down the CPU when using the IGP, sauce pleaseGuspaz - Monday, November 14, 2011 - link
Sandy bridge has 21.2GB/s of memory bandwidth. It's a dual-channel system, not single-channel as you imply (both the PCIe and memory controllers are on-die on the CPU). Sending a 1080p image at 60Hz over that bus, uncompressed, would require ~0.35 GB/s of memory bandwidth (Double that, I suppose, to actually display it). I'm not seeing how this would have a major impact on a system that isn't anywhere near being memory bandwidth limited at the moment.MrSpadge - Monday, November 14, 2011 - link
Totally agree with Guspaz.And you'Ve got even more facts wrong: the amount of bandwidth needed for the frame buffer depends on display refresh rate and resolution, but not on game complexity.
MrS
Roland00Address - Monday, November 14, 2011 - link
And it was supposedly close to release in April, but then it wasn't heard from again.know of fence - Tuesday, November 15, 2011 - link
"Optimus for Desktops" headline made its rounds in April 2011, 6 month ago. Maybe after the next gen of cards or maybe after the holidays? It's time desktops get some cool tech instead of "super-size" technology (OC, SLI, multi monitor. 3D).Scalable noise & power has the potential to make Geforce Desktop PCs viable for general purposes again, instead of being a vacuum / jet engine.
Seriously with equal power consumption heat pumps are three to four times as efficient when it comes to room heating.
euler007 - Monday, November 14, 2011 - link
How about some Autocad 2012 Quadro drivers Nvidia?GTVic - Monday, November 14, 2011 - link
I believe Autodesk is moving away from vendor specific drivers. The preferred option for hardware driver in the performance tuner is just "Autodesk". If you have an issue with a Quadro driver on an older release of AutoCAD, Autodesk's official response will be to use the Autodesk driver instead. Autodesk certifies the Quadro and AMD FirePro drivers as well as drivers for consumer video cards.In the past, 2D users didn't generally turn on the Autodesk hardware acceleration, especially if you had a consumer level video card. With 2012 you almost have to turn on hardware acceleration because almost everything is now accelerated. You will see significant flickering in the user interface without acceleration. As a result Autodesk now needs to supports most consumer graphics cards out of the box and can't rely on a vendor specific driver.
With FirePro and Quadro what you are paying for is hopefully increased reliability and increased testing to ensure that the entire graphics pipeline supports the Autodesk requirements for hardware acceleration. In addition, Autodesk is more likely to certify Quadro/FirePro hardware with newer graphics drivers than if you purchase a high-end consumer card.
Filiprino - Monday, November 14, 2011 - link
How about some GNU/Linux support? You know, there's lot of compute power being used on GNU/Linux systems, and video rendering too.And finally, what about Optimus on GNU/Linux? NVIDIA drivers are ok on Linux based systems, but they're not complete as now there's no Optimus at all.