Setting up the Google Mini
When you first login to the Google Mini, you are presented with a web-based interface to configure the general parameters. These settings include the device IP Address, DNS Server, Admin E-mail address, Time zone, etc. Nothing fancy here, although we did have to configure an internal DNS server due to some firewall routing issues.Configuring your first Collection
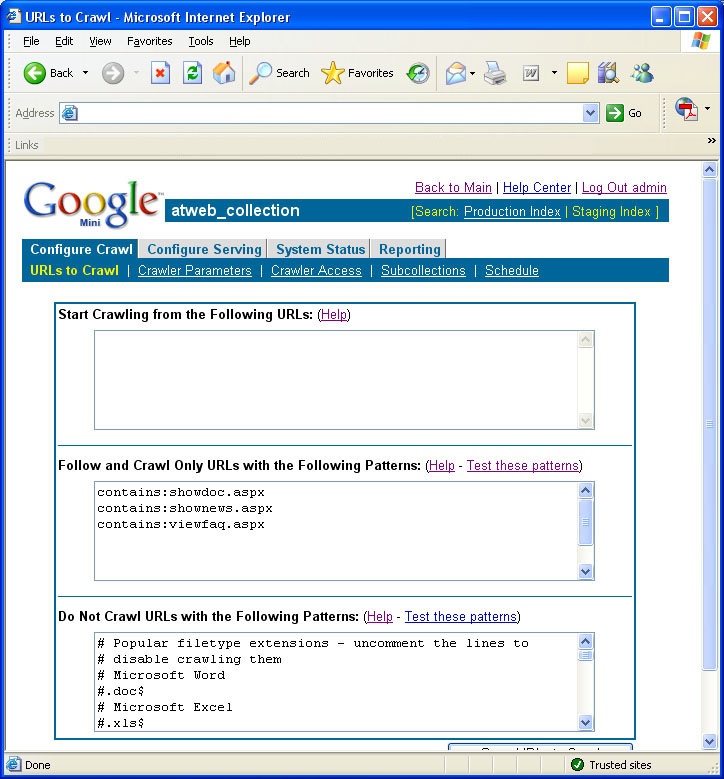
Like most any search product, the first task is to create a collection of what you want searched. The Google Mini supports one collection while its larger brother, the “Google Search Appliance, supports an unlimited number of collections. Collections can contain sub-collections (which I’ll explain a bit later).Once you’ve created your first collection, the first step is to edit the collection parameters and set it up for indexing. URLs to Crawl was where we started, which contains a few parameters, Starting URLs from which to crawl, Follow and Crawl certain URLs or parts thereof and Do Not Crawl URLs matching certain patterns. This was probably where we spent 99% of our time configuring the Mini. The mini allows for 100,000 documents/URLs to be stored in a collection, and AnandTech contains approximately 40,000 articles, news and blog entries.
When we first set up the Mini, we told it to start in each of the website’s sections (for example, http://www.anandtech.com/it/) and in the web news area. The Mini considers any unique URL string to be a unique document, which makes sense (but is a bit surprising the first time that you run an index).
After four hours of indexing, the Mini had managed to reach its document limit and we had to improvise. After several attempts at filtering out various URL patterns and restricting the crawling as much as we could, we ended up writing some code. We created a file to which a link to every article, news post and blog post that have been published on the site would be dumped. That file is cached for a few hours as we update the index 3 times a week. We then configured the Mini to start at those URLs and restricted it only to URLs ending in showdoc.aspx, shownews.aspx and a few others. It worked - the next index was around 38,000 documents. A word to the wise: don’t let the Mini crawl your entire site without keeping a close eye on it.
Sub-collections
Before you let the Google Mini go off and crawl to its hearts content, consider creating some sub-collections if they are required. Sub-collections are simply small collections containing specific fragments of your site. For instance, on AnandTech, we have Articles, News, Blogs and FAQs as sub-collections. Each of these can be searched separately within the collection to allow us to have targeted searches within the various sections of the web site.KeyMatch/Synonyms
Like the google.com search, the Google Mini supports key matches that allow you to have links appear at the top of your search results, which match keywords that you enter in the Google Mini interface. Another useful feature that is included is Synonyms, which allow you to enter synonyms for various search terms. We have a few created. Try typing “ iram” into our search, and you’ll notice that it suggests “i-ram” as a possible search.Look and feel integration
The last thing that we worked on was making the Mini look like it is part of AnandTech.com. There are two ways to go about this in the Mini admin. One is to use their built-in page layout helper, which allows you to wrap the search screens with a custom header and footer. The other way (which we prefer) is to use the XSLT Stylesheet editor and modify the stylesheet to meet your needs.All in all, our integration went fairly smoothly, and the Mini has made it exponentially easier to find content on AnandTech.com.
Screen Shots
 Settings |
 Collection |
 Output |
 Subcollections |








48 Comments
View All Comments
bellwether - Thursday, November 29, 2007 - link
This is a great starting point for search for small businesses. Google's algorithm is effective, but the problem is that the result page sends the user to the Google Mini itself (so they leave your website), and it is in Google's format. XSLT is supposed to help you modify this, but doesn't do that good of a job.This http://www.components4asp.net/GoogleMini/">custom google mini website search page has something for ASP.NET that lets you add in image thumbnails to the search result and integrate the search into a regular ASPX page that's part of your website. Plus, there's a 30 day free trial. Definitely worth taking a look at.
fzkl - Saturday, September 10, 2005 - link
The dell memory is probably used because it has life time warranty.mini - Friday, September 9, 2005 - link
What is the OS used in the Google Mini?Could you please post more administration snapshots?
Tks
Eirikur - Friday, September 9, 2005 - link
I suspect some of your problems with the Full Text Search feature of SQL server might be related to how it breaks text into words and sentences. The word breaker will break by punctuation which is horrendous when it comes to version numbers. The word breaker will look at a version number like "2.0" and decide that "2" and "0" are two separate words in different sentences. Then it will throw both away since it ignores single letter words. In a version number like "2.82.1" only "82" will get indexed.jberry - Wednesday, September 7, 2005 - link
Does anyone know how the Google mini counts the 100K page limit with dynamic websites??fishy - Wednesday, September 7, 2005 - link
So...When are going to overclock this thing?
ok, just k/d....
PassMark - Tuesday, September 6, 2005 - link
There are much cheaper solutions around that you can run on your existing hardware and have similar performance without a limit of 100,000 pages.e.g.
The http://www.wrensoft.com/zoom/">Zoom Search Engine for $99
http://www.wrensoft.com/zoom/">http://www.wrensoft.com/zoom/
Brickster - Tuesday, September 6, 2005 - link
I imagine there are certain documents that you would want only certain users to have access to. How do you control access to the documents that Google has indexed? Does it just return everything despite and document-specific, access security policy?Verdant - Tuesday, September 6, 2005 - link
hence why the pricetag on the big brother is next to useless imho...i can't see anyone using anything besides the mini for indexing something like a website, for knowledgebases and the like you need a lot more than just a way to search.
Brickster - Wednesday, September 7, 2005 - link
Dude, you should see our company. A full featured search engine alone based on Google would do wonders for our cess pool of organization that is our intranet and file servers. For some, that is enough.