Intel Core i9-13900K and i5-13600K Review: Raptor Lake Brings More Bite
by Gavin Bonshor on October 20, 2022 9:00 AM ESTSPEC2017 Single-Threaded Results
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing it is good enough. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates on our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-source compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labeled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
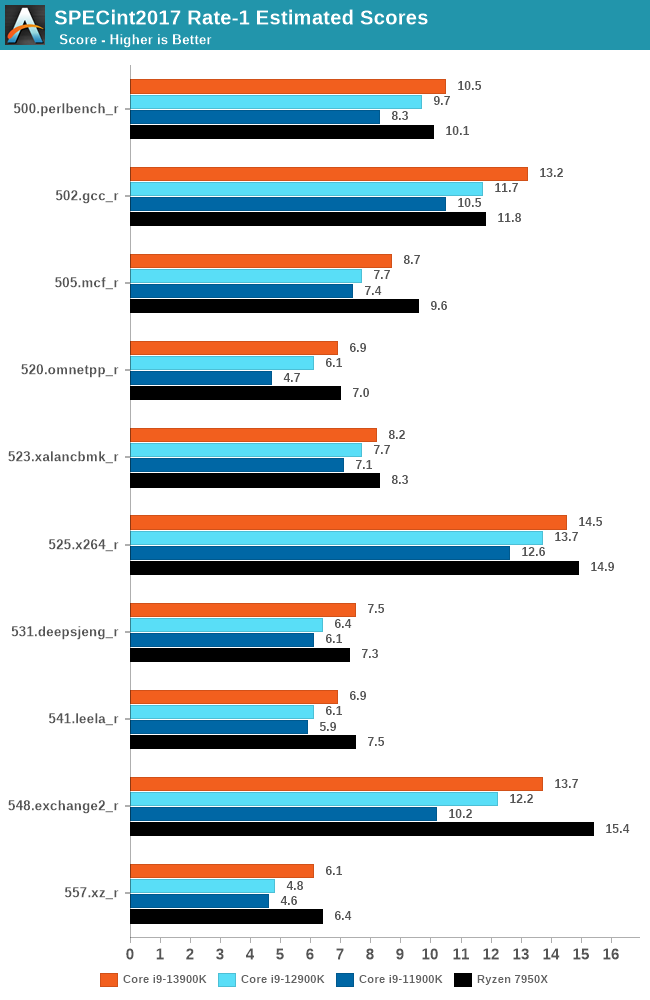
Opening things up with SPECint2017 single-threaded performance, it's clear that Intel has improved ST performance for Raptor Lake on generation-upon-generation basis. Because the Raptor Cove P-cores used here don't deliver significant IPC gains, these performance gains are primarily being driven by the chip's higher frequency. In particular, Intel has made notable progress in improving their v/f curve, which allows Intel to squeeze out more raw frequency.
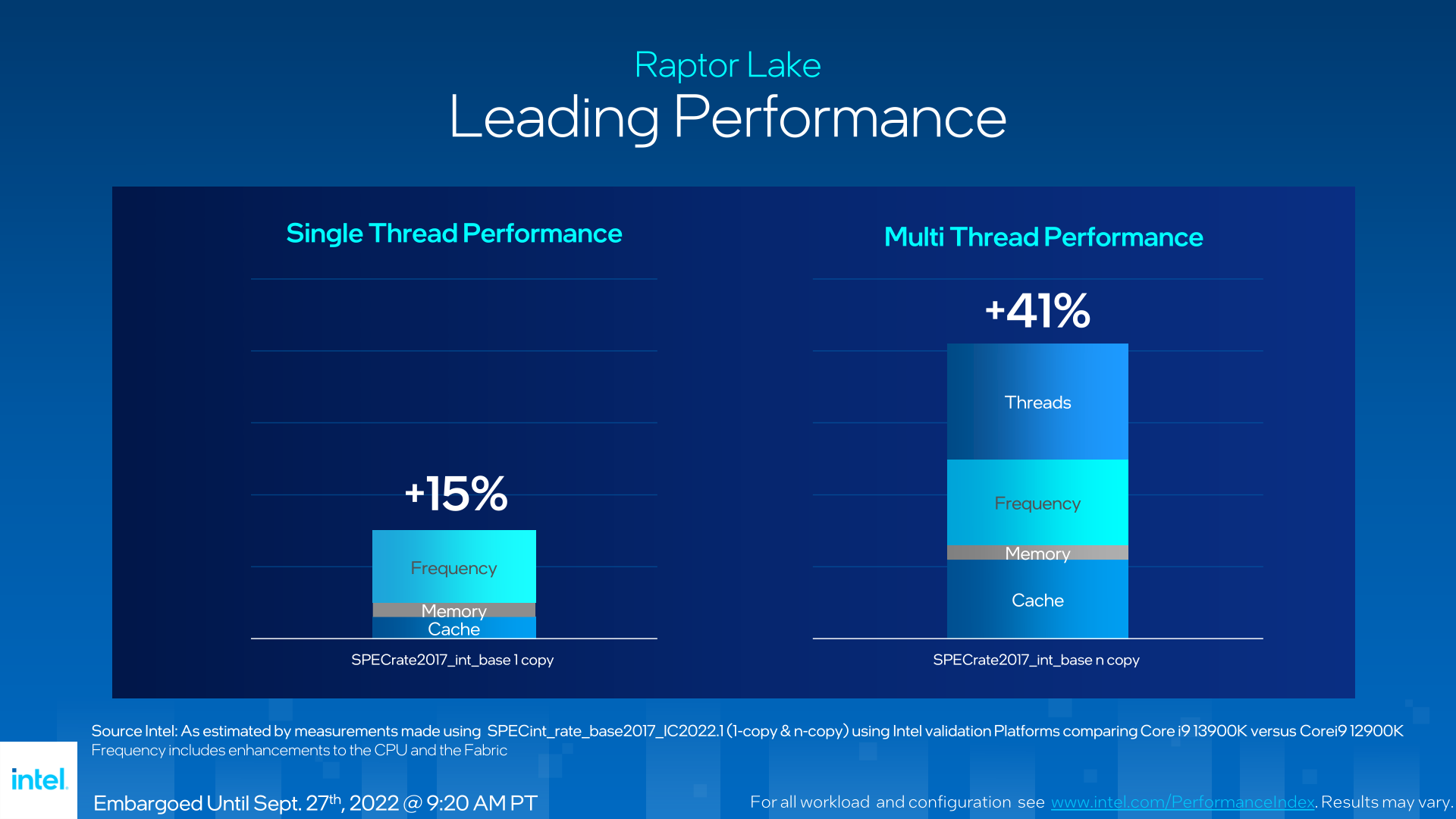
And this is something Intel's own data backs up, with one of Intel's performance breakdown slides showing that the bulk of the gains are due to frequency, while improved memory speeds and the larger caches only making small contributions.
The ST performance itself in SPECint2017 is marginally better going from Alder Lake to Raptor Lake, but these differences can certainly be explained by the improvements as highlighted above. What's interesting is the performance gap between the Core i9-13900K and the Ryzen 9 7950X isn't as far apart as it was with Alder Lake vs. Ryzen 9 5950X. In 500.perlbench_r, the Raptor Lake chip actually outperforms the Zen 4 variant by just under 4%, while Ryzen 9 7950X is a smidgen over 10% better in the 505.mcf_r test.
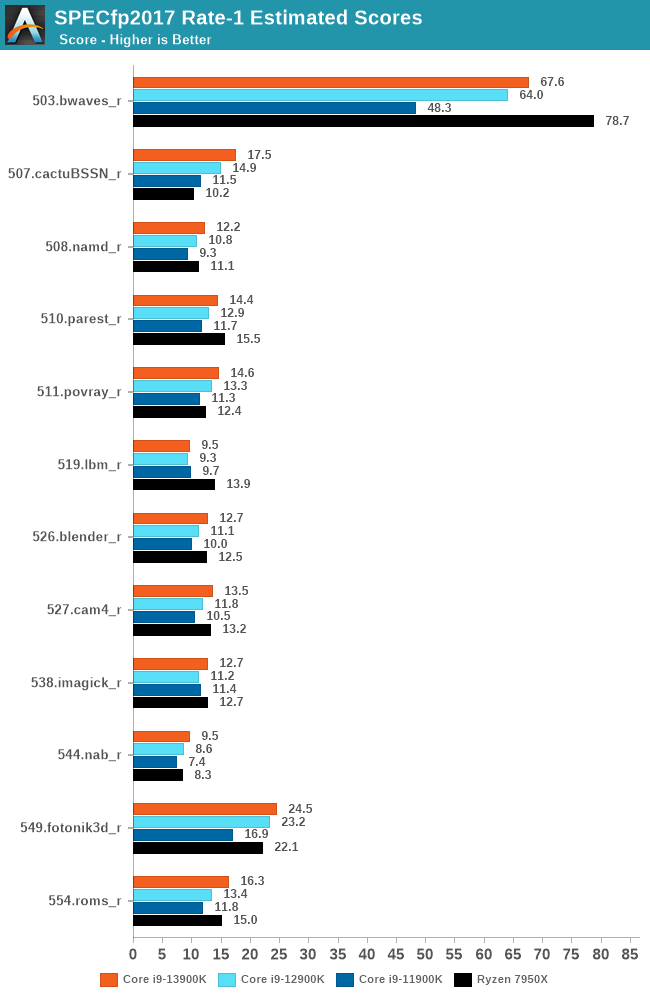
Looking at the second set of SPEC2017 results (fp), the Ryzen 9 7950X is ahead of the Core i9-13900K by 16% in the 503.bwaves_r test, while the Raptor Lake chip is just under 10% better off in the 508.namd_r test. The key points to digest here is that Intel has done well to bridge the gap in single-threaded performance to Ryzen 7000 in most of the tests, and overall, it's a consistent trade-off between which test favors which mixture of architecture, frequency, and most importantly of all, IPC performance.
While we highlighted in our AMD Ryzen 9 7950X processor review, which at the time of publishing was the clear leader in single-core performance, it seems as though Intel's Raptor Lake is biting at the heels of the new Zen 4-core. In some instances, it's actually ahead, but stiff competition from elsewhere is always good as competition creates innovation.
With Raptor Lake being more of a transitional and enhanced core design that Intel's worked with before (Alder Lake), it remains to be seen what the future of 2023 holds for Intel's advancement in IPC and single-threaded performance. Right now, however SPEC paints a picture where it's pretty much neck and neck between Raptor Cove and Zen 4.








169 Comments
View All Comments
Nero3000 - Thursday, October 20, 2022 - link
Correction: the 12600k is 6P+4E - table on first page ReplyHixbot - Thursday, October 20, 2022 - link
I am hoping for an high frequency 8 core i5 with zero ecores and high cache. It's would be a gamer sweet spot, and could counter the inevitable 3d cache Zen 4. Replynandnandnand - Friday, October 21, 2022 - link
big.LITTLE isn't going away. It's in a billion smartphones, and it will be in most of Intel's consumer CPUs going forward.Just grab your 7800X3D, before AMD does its own big/small implementation with Zen 5. Reply
HarryVoyager - Friday, October 21, 2022 - link
Honestly, I'm underwhelmed by Intel's current big.LITTLE setup. As near as I can tell, under load the E cores are considerably less efficient than the P cores are, and currently just seem to be there so Intel can claim multi-threading victories with less die space.And with the CPU's heat limits, it just seems to be pushing the chip into thermal throttling even faster.
Hopefully future big.LITTLE implementations are better. Reply
nandnandnand - Friday, October 21, 2022 - link
Meteor Lake will bring Redwood Cove to replace Golden/Raptor Cove, and Crestmont to replace Gracemont. Gracemont in Raptor Lake is the same as in Alder Lake except for more cache, IIRC. All of this will be on "Intel 4" instead of "Intel 7", and the core count might be 8+16 again.Put it all together and it should have a lot of breathing room compared to the 13900K(S).
8+32 will be the ultimate test of small cores, but they're already migrating on down to the cheaper chips like the 13400/13500. Reply
Hixbot - Saturday, October 22, 2022 - link
Yes it does seem backwards that the more efficient architecture is in the P core. Reducing power consumption for light tasks seems better to keep it on the P core and downclock. I don't see the point of the "e" cores as effiency, but rather academic multithreaded benchmark war. Which isn't serving the consumer at all. Replydeil - Monday, October 24, 2022 - link
E is still useful, as you get 8/8 cores in space where you could cram 2/4. I agree E for efficiency should be B as background to make it clearer what's the point. They are good for consumers as they offer all the high speed cores for main process, so OS and other things dont slow down.I am not sure if you followed, but intel cpu's literally doubled in power since they appeared, and at ~25% utilization, cpu's halved power usage. What you should complain about is bad software support, as this is not something that happens in the background. Reply
TEAMSWITCHER - Monday, October 24, 2022 - link
I don't think you are fully grasping the results of the benchmarks. Compute/Rendering scores prove that e-cores can tackle heavy work loads. Often trading blows with AMD's all P-Core 7950X, and costing less at the same time. AMD needs to lower all prices immediately. Replyhaoyangw - Monday, October 24, 2022 - link
That's an oversimplification actually, P-cores and E-cores are both efficient, just for different tasks. The main efficiency gain of P-cores is it's much much faster than E-cores for larger tasks. Between 3 and 4GHz, P-cores are so fast they finish tasks much earlier than e-cores so total energy drawn is lower. But E-cores are efficient too, just for simple tasks(at low clockspeeds). Below 3GHz and above 1GHz, e-cores are much more efficient, beating P-cores in performance while drawing less power.Source: https://chipsandcheese.com/2022/01/28/alder-lakes-... Reply
Great_Scott - Friday, November 25, 2022 - link
Big.LITTLE is hard to do, and ARM took ages and a lot of optimization before phone CPUs got much benefit from it.The problem of the LITTLE cores not adding anything in the way of power efficiency is well-known.
I'm saddened that Intel is dropping their own winning formula of "race-to-sleep" that they've successfully used for decades for aping something objectivly worse because they're a little behind in die shrinking. Reply