NVIDIA's Scalable Link Interface: The New SLI
by Derek Wilson on June 28, 2004 2:00 PM EST- Posted in
- GPUs
It's Really Not Scanline Interleaving
So, how does this thing actually work? Well, when NVIDIA was designing NV4x, they decided it would be a good idea to include a section on the chip designed specifically to communicate with another GPU in order to share rendering duties. Through a combination of this block of transistors, the connection on the video card, and a bit of software, NVIDIA is able to leverage the power of two GPUs at a time.
NV40 core with SLI section highlighted.
As the title of this section should indicate, NVIDIA SLI is not Scanline Interleaving. The choice of this moniker by NVIDIA is due to ownership and marketing. When they acquired 3dfx, the rights to the SLI name went along with it. In its day, SLI was very well known for combining the power of two 3d accelerators. The technology had to do with rendering even scanlines on one GPU and odd scanlines on another. The analog output of both GPUs was then combined (generally via a network of pass through cables) to produce a final signal to send to the monitor. Love it or hate it, it's a very interesting marketing choice on NVIDIA's part, and the new technology has nothing to do with its namesake. Here's what's really going on.
First, software (presumably in the driver) analyses what's going on in the scene currently being rendered and divides for the GPUs. The goal of this (patent-pending) load balancing software is to split the work 50/50 based on the amount of rendering power it will take. It might not be that each card renders 50% of the final image, but it should be that it takes each card the same amount of time to finish rendering its part of the scene (be it larger or smaller than the part the other GPU tackled). In the presentation that NVIDIA sent us, they diagramed how this might work for one frame of 3dmark's nature scene.
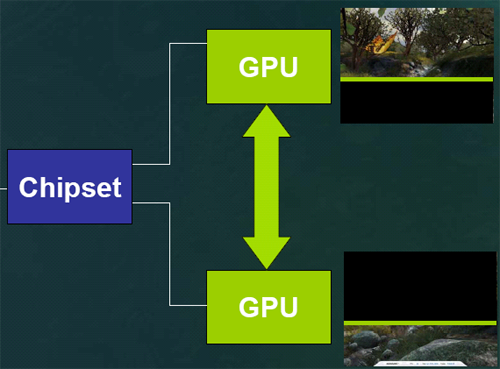
This shows one GPU rendering the majority of the less complex portion of a scene.
Since the work is split on the way from the software to the hardware, everything from geometry and vertex processing to pixel shading and anisotropic filtering is divided between the GPUs. This is a step up from the original SLI, which just split the pixel pushing power of the chips.
If you'll remember, Alienware was working on a multiple graphics card solution that, to this point, resembles what NVIDIA is doing. But rather than scan out and use pass through connections or some sort of signal combiner (as is the impression that we currently have of the Alienware solution), NVIDIA is able to send the rendered data digitally over the SLI (Scalable Link Interface) from the slave GPU to the master for compositing and final scan out.

Here, the master GPU has the data from the slave for rendering.
For now, as we don't have anything to test, this is mostly academic. But unless their SLI has an extremely high bandwidth, half of a 2048x1536 scene rendered into a floating point framebuffer will be tough to handle. More normally used resolutions and pixel formats will most likely not be a problem, especially as scenes increase in complexity and rendering time (rather than the time it takes to move pixels) dominates the time it takes to get from software to the monitor. We are really anxious to get our hands on hardware and see just how it responds to these types of situations. We would also like to learn (though testing may be difficult) whether the load balancing software takes into account the time it would take to transfer data from the slave to the master.








40 Comments
View All Comments
quanta - Monday, July 12, 2004 - link
>> i would be choose "another old card" because from what nv is saying... performance improvements can go up to 90%, and at least 20-30% increase with a twin card and if history repeats itself, the next incarnation of cards would be as fast... like at less 20-30% speed increase. it would be a smarter choice paying $200 for an upgrade instead of another $500 for an upgrade.Even if NVIDIA says is true, it will only be, at best, true for applications supporting current feature sets. If/when tessellation technique get 'standardized', or NVIDIA decide to add new features (eg: 3Dc normal map compression, wider pipes, ray tracing, 64-bit per channel rendering, smarter shader ALUs/instruction scheduler), the old cards are going to be penalized greatly, sometimes even for existing (GeForce 6 generation) applications. Such performance penalties are not going to be compensated easily by adding another GeForce 6800 Ultra Extreme video card, if at all.
CZroe - Saturday, July 3, 2004 - link
<<The last of the SLI Voodoo2s had a dual gpu on a single board for one PCI slot. I cant see why the same couldnt be done for a dual 6800 gpu board on a single x16 PCIe slot which is nowhere near saturation with current gpus.>>No, the Quantum Obsidian X24 Voodoo2 SLI on a single card was two boards. They were stacked on top of eachother with a special connector. This cause overheating problems, but it didn't matter much. It used a PCI bridge chip to connect two PCI cards to the same PCI slot and not a dual GPU design. There were four giant 3Dfx chips on the thing, so I think all Voodoo2's were two-CPU boards. There was a crazy Voodoo1 SLI board created at one time but it was probably using an undocumented method for adding a second CPU like the Voodoo2's had. Also, it was not the last Voodoo2 card by far... Even 3dfx themselves started making the Voodoo2 1000 boards!
gopinathbill - Thursday, July 1, 2004 - link
Yes SLI has come back and everyone knows what and how good it is. The question now is about NVIDIA trying to catch the king of the hill thing. Everytime nvidia has come up a new card the next rival ati spanks back with its latest card, which is now the current king. What nvidia has come up is this SLI thing, combination of two pci-e cards. Here everybody is wooed by the frames rates it may do by this dual card. My feeling is1) This does not prove that nvidia has brought up a new powerful card in its pocket
2) What if ATI does the same double pack (This may beat the nivida double pack)
3) This technology is not new, if any chance a guy with 2 previous nvidia cards can achive the same frame as the current single fastest nvidia cards.(theory)
4) This may bring down the GRAPHICS WAR. Any one wants more power just keep on adding another card
say now we have double pack, next triple so on.....want more power just fix another card..just like expanding your RAM modules
5) Now i have a double pack say Ge 5800, next year I wanna more power to play DOOM 5 ;-). How do i upgrade it buy another Ge 5800 , make a triple pack or what. What if a new GE 7000 card has come up I wanna use this. Then i have buy two of them eh?. We keep this aside for a while
Yes for any gaming freak the graphics card is his heart/soul. No war no Pun. This can be looked in a different way also
1) Wanna more fps add a new card, again lot of questions on this
2) price will come down (nothing is as sweet as this)
The same can be seen here
http://www.hardwareanalysis.com/content/forum/1728...
DigitalDivine - Wednesday, June 30, 2004 - link
>>you will be the one making hard decision on whether to get another old card (if the specific manufacturer still makes it), get one (or two) new card to replace the old one. Considering video cards model get obsoleted rather quickly, neither solutions are very attractive even for performace enthusists.i would be choose "another old card" because from what nv is saying... performance improvements can go up to 90%, and at least 20-30% increase with a twin card and if history repeats itself, the next incarnation of cards would be as fast... like at less 20-30% speed increase. it would be a smarter choice paying $200 for an upgrade instead of another $500 for an upgrade.
i have a gut feeling that nvidia would provide an affordable way for people to get dual pci express x16 motherboards to consumers.
i expect to pay 150 to 200 for a dual pci express motherboards about the same price as the most expensive p4 mobos, and if it could be for less would be perfect. and there is no way in hell i would buy a premade alienware system.
the dual pci-express videocard sounds great with a possibility of dual core athlons / p4. ;)
quanta - Wednesday, June 30, 2004 - link
Actually, #33, NVIDIA's SLI and Alienware's Video Array are not really about cost savings. Both solution not only require all cards using identical (model and clock rate) processors, but the cards have to come from same manufacters. Furthermore, upgrades are not going to be flexible. If NVIDIA decides to make a new GeForce model, you will be the one making hard decision on whether to get another old card (if the specific manufacturer still makes it), get one (or two) new card to replace the old one. Considering video cards model get obsoleted rather quickly, neither solutions are very attractive even for performace enthusists.It is possible that there may be some way to run asymmetric configurations, but it is highly unlikely. After all, SLI and VA's goal is not distributed computing.
Phiro - Wednesday, June 30, 2004 - link
Every pro and con for dual core GPUs vs. daisy-chained like hardware has been debated by the market for the last umpteen years as the single core CPU/SMP vs. multi-core CPUs.You can say "oh but the upfront cost of a multi-core gpu is so high!" and "oh it's so wasteful!!" - Every friend of mine that has a dual-cpu motherboard either a) only has one cpu in them or b) both cpu's are slow-ass crap.
You pay a huge premium on the motherboard, and it never works out. You get out of date too quick, six to 12 months after you put your mega-bucks top of the line dual-cpu rig together your neighbor can spend 1/2 as much on a single CPU and smoke your machine. That's how it *always happens.
Give me a user manageable socket on the video card at the very least, and support multi-core gpus as well. Heck, call multi-core gpus "SLI" for all I care.
Pumpkinierre - Wednesday, June 30, 2004 - link
#33, the beauty of a dual core 6800 card would be that it would work on cheaper ordinary mobos with a single x16 PCIe slot. If it is possible (and I dont see why not) an enterprising OEM is sure to make one unless nVidia puts its foot down (and I dont see why they should, two GPUs- double the profit).True, a single card now and a second card later for extra power makes sense but you gotta have a 2 slot x16 wkstation board which are rare and expensive. However you are right, the single card option would be expensive. Unlike the voodoo2s and ATI Rage FURY MAXXs where half frames are interlaced, the nVidia SLI solution just adds grunt to the processing power of the gpu card. So it is feasible to have more than two gpus eg. 3 or 4 but the heat would be a problem. The single card may also make the driver based load balancing simpler by having dedicated on-board intelligence handling this function. That way the software and system would still see the single card SLI as a single gpu.
DigitalDivine - Wednesday, June 30, 2004 - link
dual core cards does not have the flexibility of actually having 2 physical cards.having the option of upgrading later and practically doubling your performance for cheap is an incentive. pay 300 now and pay maybe 200 or 150 later for the other card, instead of 600 for just one card.
also, dual core cards gets obsolete quickly. look at the voodoo 5 for instance. it's dual core design made it very very expensive, paying the equivilent of 2 cards when you have 1 physical card. takes away the flexibility of separating the card in the future and use them for other purposes and upgradability is abysmal.
also having dual core cards splits your resources in half.
Anemone - Tuesday, June 29, 2004 - link
Why not start up some dual core cards? I'm sure it would be far cheaper and quite effective to just mount two 6800 gpu's on a card and let er rip :)just a thought...
artifex - Tuesday, June 29, 2004 - link
um... doesn't Nvidia now have a single-board design that incorporates this type of thing, just announced by Apple as the "NVIDIA GeForce 6800 Ultra DDL," to drive their 30 inch LCD panel that requires (!) two DVI inputs? (The card has 4 DVI connectors!)Or am I reading this wrong?