What Went Wrong with NV3x: A Moratorium
by Derek Wilson on April 19, 2004 4:12 PM EST- Posted in
- GPUs
The Pixel Pipe Performance Picture
The ultimate goal of graphics hardware is to determine the color of every visible pixel. From this unassuming end extend a vast array of operations that need to be performed to get the job done. As the demand for ever increasing graphics quality asserts itself on the industry, more and more work needs to be done in graphics hardware rather than in software on the CPU. All the work that ends up needing to be done on a per pixel basis translates to what is known as the pixel pipeline. To draw on an oft used analogy in computer engineering, this is basically the assembly line of a pixel.One of the more fortunate aspects of computer graphics is that determining the color of one pixel can be done completely independently of any other pixels (though NVIDIA chooses to work on four pixel units internally called "quads"), so computer graphics is infinitely parallelizable. If we had enough processing power, we could actually process every single pixel on the screen at the same time. Even though going to such extremes is currently not an option (I wonder where we'll be in another decade or two), currently graphics cards are able to process multiple pixels at a time. Just how many pixels can be rendered in parallel is described by the "width" of the architecture.
Behind NV3x is a 4x2 pixel pipe (though there was some confusion over this we will get to later). This means that NV3x based cards could draw 4 pixels with 2 textures per pixel at a time (texturing a pixel involves mapping a position on a surface to (usually) a color in a texture map -- in a two texture per pixel architecture this lookup operation can be performed with two different textures at the same time). In contrast, ATI's R300 architecture is 8x1 meaning that 8 pixels with 1 texture per pixel can be drawn at a time. Unfortunately, in single texture environments, NVIDIA could still only draw four pixels per clock at a maximum.
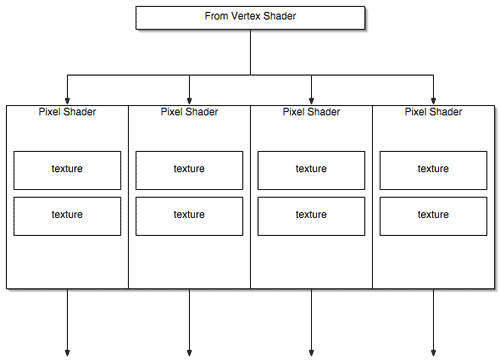
The layout of the architecture (in as much as it appears to software) is 4 pixel shader units each with two texture units. Maximum texture fill rate is twice the maximum number of pixels per second the card can draw, which means that a lot of power is going to waste when only one texture is being used per surface.
The decision NVIDIA made for NV3x makes sense considering that many effects in fixed function and early programmable hardware (the DirectX 7 and 8 timeframe) were better suited to creating and applying multiple textures to a surface (this is called multitextureing for obvious reasons). Implementing Light maps, environment maps and cube maps (reflections), and bump maps, in addition to the traditional color map, are all examples of ways developers can exploit multitextureing to add realism to their environment.
Most multitextureing effects can be done using vertex and pixel shader programs. Shader programs are able to offer a higher degree of control to developers and artists and can eliminate the need for multitextureing at the same time. While this is fortunate for developers, artists, end users, and ATI, the NV3x architecture is not suited to the current climate and thus its real world performance falls much shorter than its theoretical max than NVIDIA would like.
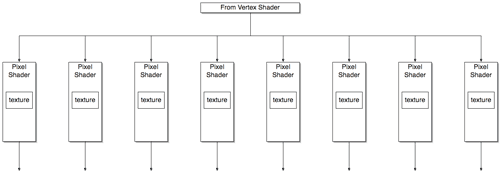
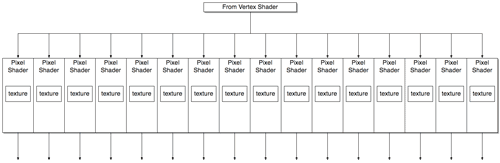
When moving to NV40 from the NV3x architecture, more of a focus was placed on single texturing while enhancing the internal performance of the vertex and pixel shaders. This was done by essentially quadrupling the number of pixel shader pipelines while only doubling the capacity of the GPU to handle textures (making it a 16x1 architecture). On NV40, maximum pixel and texture fill rates are the same leading to a more balanced use of hardware in real world conditions. When handling multitextureing, NV40 can also run in an 8x2 mode where half of the pipeline is dedicated to each texture. In this multitexture mode, NV40's texture fill rate is the same as its single texture mode while its pixel fill rate is halved.
Aside from color and texturing, 3D graphics cards also need to deal with the third dimension: depth "into" the screen. This depth, or z, value keeps track of how near or far a pixel on a surface is from the viewer. If at any point in the pipeline something is determined to be "behind" another thing, it can be thrown out or turned off (this is known as occlusion culling). One of the best ways to enhance performance in 3D graphics is to do less work, and the key is knowing what not to do. Calculating and tracking z values is a key part of eliminating work. NVIDIA's architectures can handle stenciling in the same bit of hardware that handles z operations. Stenciling is difficult to explain, but it may be easier to grasp by looking at a simplified explanation of a common application: shadowing. Shadows can be implemented by "rendering" z values as viewed from a light source. Anything that gets turned off (is behind something) from the perspective of the light source is shadowed, and can remain off when rendering the scene from the perspective of the viewer (who will see a shadow due to the light where pixels were turned off). Doing "good" shadowing is much more complicated than this, but that's the general idea.
In both NV3x and NV40 architectures, z and color can be calculated per pixel at the same time. In addition, rather than coloring a pixel, a z or stencil operation can be performed in the color unit. This allows NV3x to perform 8 z or stencil ops per clock and NV40 to perform 32 z or stencil ops per clock. NVIDIA has started to call this "8x0" and "32x0", respectively, as no new pixels are drawn. This mode is very useful if a z only pass is performed first, or if stencil shadows are used (as is the case with Doom 3).
Of course, there is more to graphics performance than how many pixel pipes are under the hood. There were other reasons NV3x performance wasn't what it could have been, not the least of which was the internal layout of the vertex and pixel shaders.








18 Comments
View All Comments
WizzBall - Tuesday, May 4, 2004 - link
Nice article... sooo, when are we going to see the follow-up to this now that ATI came forward with their cards ? May I suggest 'What went wrong with NV4.x' ? :DTrogdorJW - Tuesday, April 27, 2004 - link
Hey... anyone else having password issues, or is that something my company network admins f'ed up? I keep entering my password, but it doesn't get remembered. Ugh....TrogdorJW - Tuesday, April 27, 2004 - link
Personally, I think it's all about the alliteration: "The Pixel Pipe Performance Picture!" :)Anyway, I imagine the moratorium will end once the R420 is released and we can talk about all four chips (R3xx, R4xx, NV3x, and NV4x), right? Yeah, that's it....
On a side note, I wonder how much going from FP24 to FP32 would cost ATI in terms of transistors, not to mention the Shader Model 3.0 stuff. It's not that we really need it, but going from 24-bit to 32-bit color basically makes everthing that operates on the data 25% larger in terms of transistor usage. Add in the other missing SM3.0 features, and I think a 160-180 million transistor R420 would suddenly become a 222 million transistor NV40. Basically, I think performance from the next generation cards will be about the same given the same GPU/VPU and RAM speeds. The only difference will be that NV4x has SM3.0 support, which looks to be a marketing point more than anything.
greendonuts3 - Thursday, April 22, 2004 - link
that's "Post-Mortem", as in "Post-Mortem Analysis" as in "Autopsy," not "Moratorium," as in "banzored."Thank you very much.
And DON'T forget to hyphenate "Post-Mortem."
"Post Mortem" means "dead letter" or some such.
ianmills - Thursday, April 22, 2004 - link
this article is crap. The real reason NV30 sucked is because nvidia slept with 3Dfx and got caught pixel herpes.TauCeti - Wednesday, April 21, 2004 - link
Moratorium:> We have stopped -- we are done with NV3x analysis.
Well, if you have _stopped_ writing NV3X-content, it is _not_ a moratorium.
After a moratorium ends, you are obliged to continue with your _suspended_ activity.
Besides that: good article ;)
DerekWilson - Wednesday, April 21, 2004 - link
#11:We have stopped -- we are done with NV3x analysis. I'll admit that the title could have been phrased a bit better, but we did mean moratorium... Of all the articles I have written I think I've gotten the highest volume of emails on this one -- to tell me that I don't know what moratorium means ;-)
But on topic ... The big problem with an article like this (or any architectural or deeply technical article) is balancing depth, clarity, and length.
If you guys have any suggestions on balancing these aspects in another way, please let us know. We want to write the articles that you want to read!
GomezAddams - Wednesday, April 21, 2004 - link
"Can it not be a moratorium on NV3x articles?"It will be when you stop writing them. ;)
I thought it was a pretty decent article too. I am looking forward to one that compares ATIs next contestant on these issues.
Personally, I can handle a lot more detail but I would prefer not to spend so much time reading articles. :)
Phiro - Wednesday, April 21, 2004 - link
My earlier outburst aside, it's a very good article.DerekWilson - Wednesday, April 21, 2004 - link
Can it not be a moratorium on NV3x articles? I thought it was funny ;-)fp16 vs fp32 and image quality is a very tough nut to crack. there are a lot of things going on on the side of compiler optimizations that we really need to look into in order to understand what's going on.
also, rotated vs. ordered grid has no performance difference. or it shouldn't anyway. we wanted to focus on performance in this article.