The NVIDIA GeForce GTX 1080 Ti Founder's Edition Review: Bigger Pascal for Better Performance
by Ryan Smith on March 9, 2017 9:00 AM ESTCompute
Shifting gears, let’s take a look at compute performance on GTX 1080 Ti.
Starting us off for our look at compute is LuxMark3.1, the latest version of the official benchmark of LuxRender. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
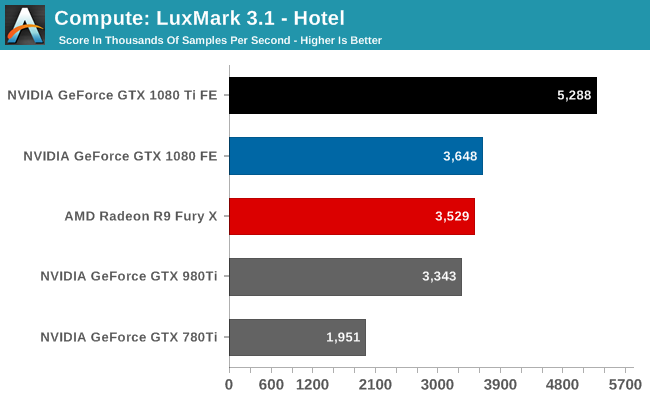
The OpenCL situation for NVIDIA right now is a bit weird. The company is in the middle of rolling out OpenCL 2.0 support to their video cards – something that I had actually given up hope on until it happened – and as a result their OpenCL drivers are in a state of flux as company continues to refine their updated driver. The end result is that OpenCL performance has dipped a bit compared to where the GTX 1080 launched at back in May, with said card dropping from 4138 points to 3648 points. Not that the GTX 1080 Ti is too fazed, mind you – it’s still king of the hill by a good degree – but the point is that once NVIDIA gets their drivers sorted out, there’s every reason to believe that NVIDIA can improve their OpenCL performance.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.
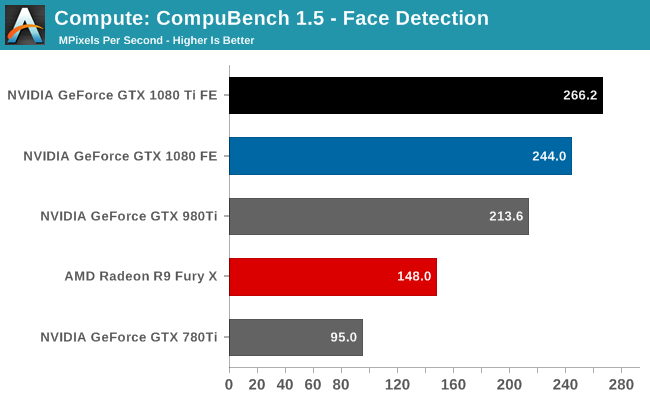
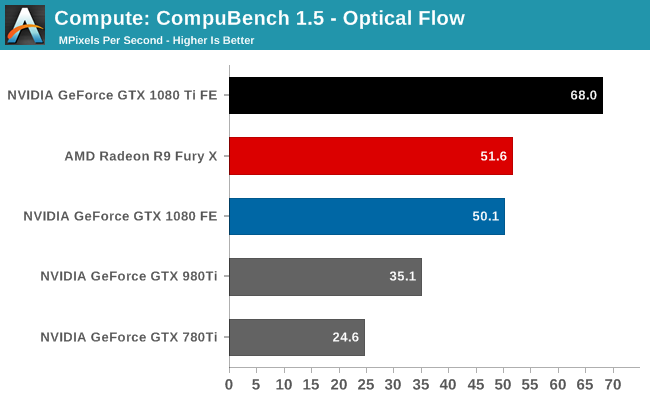
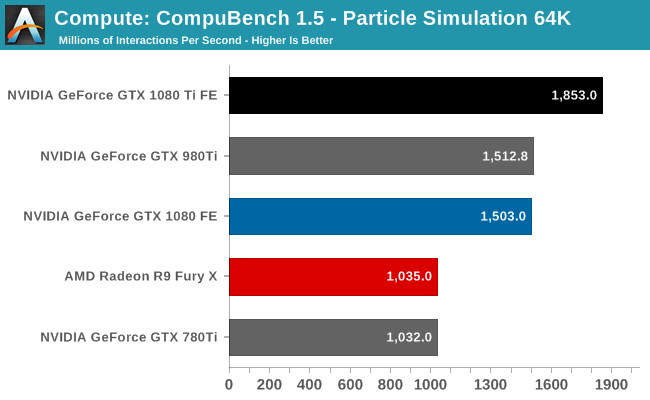
Like LuxMark, CompuBench shows some minor performance regressions on the GTX 1080 as compared to the card’s launch. None the less, this doesn’t do anything to impede the GTX 1080 Ti’s status as the fastest of the GeForce cards. It dominates every sub-benchmark, including Optical Flow, where the original GTX 1080 was unable to pull away from AMD’s last-generation Radeon R9 Fury X.








161 Comments
View All Comments
Jon Tseng - Thursday, March 9, 2017 - link
Launch day Anandtech review?My my wonders never cease! :-)
Ryan Smith - Thursday, March 9, 2017 - link
For my next trick, watch me pull a rabbit out of my hat.blanarahul - Thursday, March 9, 2017 - link
Ooh.YukaKun - Thursday, March 9, 2017 - link
/clapsGood article as usual.
Cheers!
Yaldabaoth - Thursday, March 9, 2017 - link
Rocky: "Again?"Ryan Smith - Thursday, March 9, 2017 - link
No doubt about it. I gotta get another hat.Anonymous Blowhard - Thursday, March 9, 2017 - link
And now here's something we hope you'll really like.close - Friday, March 10, 2017 - link
Quick question: shouldn't the memory clock in the table on the fist page be expressed in Hz instead of bps being a clock and all? Or you could go with throughput but that would be just shy of 500GBps I think...Ryan Smith - Friday, March 10, 2017 - link
Good question. Because of the various clocks within GDDR5(X)*, memory manufacturers prefer that we list the speed as bandwidth per pin instead of frequency. The end result is that the unit is in bps rather than Hz.* http://images.anandtech.com/doci/10325/GDDR5X_Cloc...
close - Friday, March 10, 2017 - link
Probably due to the QDR part that's not obvious from reading a just the frequency. Thanks.