AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
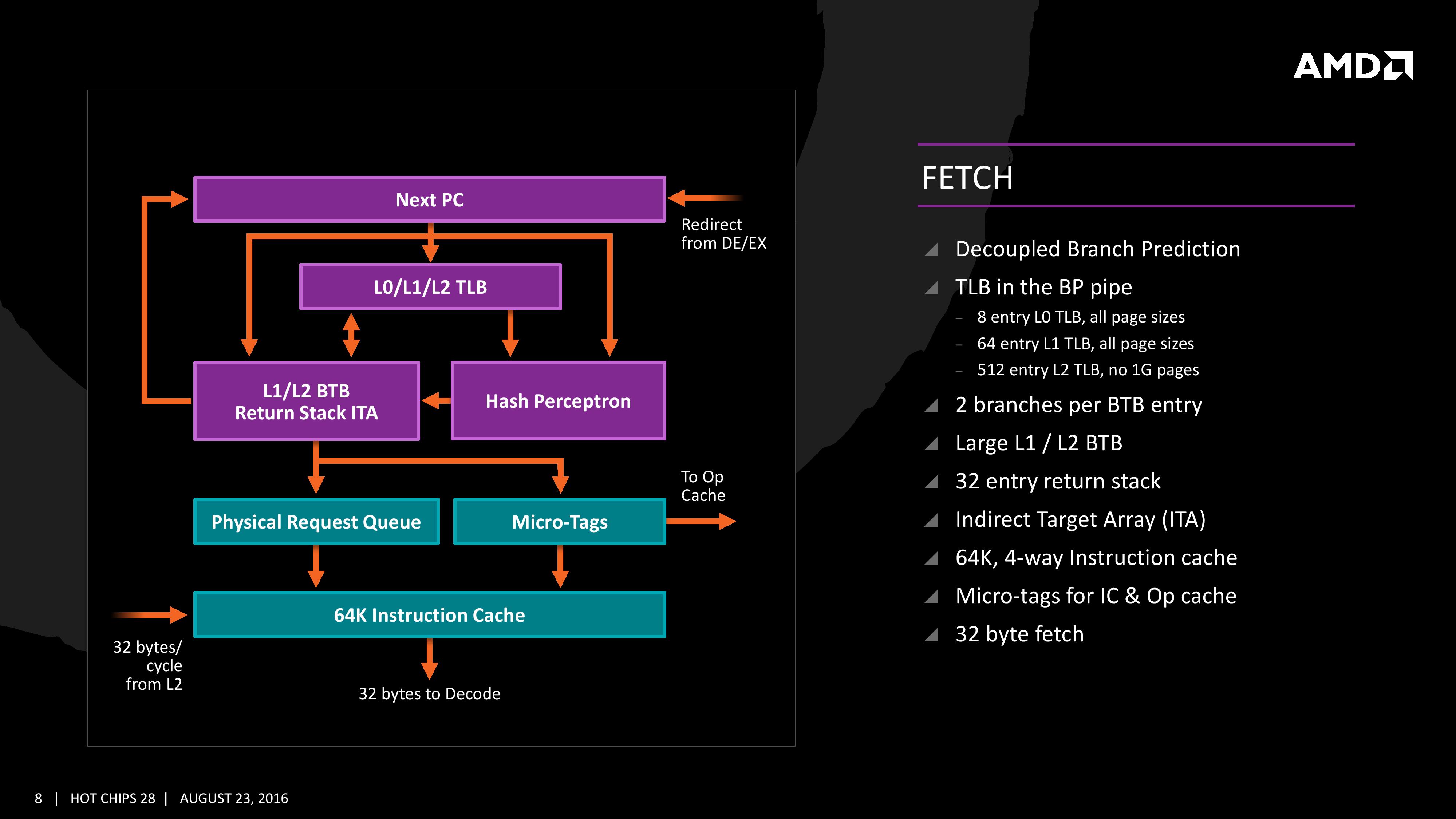
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
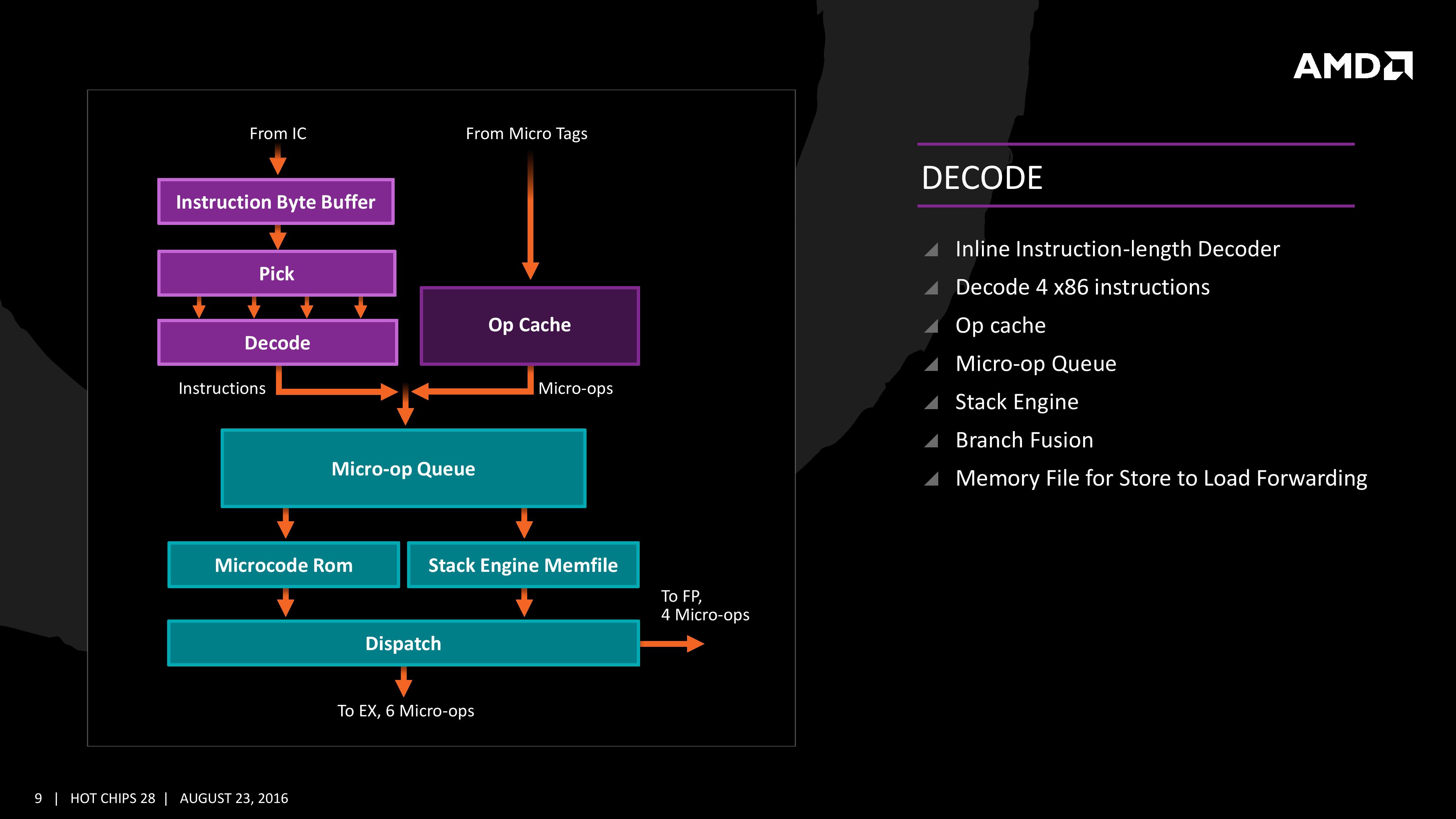
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
CrazyElf - Tuesday, August 23, 2016 - link
If they can really get a 40% improvement over Excavator, and I mean 40% on average, not on a few select benchmarks, then AMD has a serious chance of being a compelling option once again.I'm hoping to see more improvements on Floating Point, which was comically bad in Bulldozer.
A big part of the problem is that we don't know how well Zen will clock or the power consumption. Still, this should be a major leap in performance overall. We'll have to wait for the launch day benchmarks to see the true story.
Another big concern is the platform. CPU performance is only part of the story. We need a good platform that can rival the Z170 and Intel HEDT platforms for this to be compelling on the desktop. For mobile, there will have to be good dual channel Zen APUs (Carrizo, as Anandtech noted was heavily gimped by poor quality OEM designs obsessed with cost cutting).
jabber - Wednesday, August 24, 2016 - link
Yeah I don't think OEMs and others are that worried about supporting AMD. AMD have withered away so much, making AMD CPU capable gear must have become a very minor part of say ASUS/Gigabyte/MSI etc. revenue stream. Making AMD based graphics cards is okay but motherboards? Not so much.teuast - Wednesday, August 24, 2016 - link
I wouldn't speak so soon. Just this year MSI and Gigabyte (at least) have introduced new AM3+ boards with USB 3.1 and PCIe 3.0. Why, I'm not sure, but if they're doing that for something as old and deprecated as the FX chips, it would defy logic for Zen to come out and for them to only release a few token efforts.I will say, if the CPUs are good but you're right about OEMs not being concerned with support, then the first OEM to say "hey, why don't we make some actually good AM4 boards?" is going to make an absolute killing.
h4rm0ny - Thursday, August 25, 2016 - link
Are you sure about the PCI-E v3 on AM3+ motherboards? I can find recent releases that have USB3.1 and M.2, but none that support PCI-Ev3. Can you link me or provide a model number? I didn't think 3rd generation PCI-E was possible on the Bulldozer line.SKD007 - Thursday, August 25, 2016 - link
SABERTOOTH 990FX/GEN3 R2.0SKD007 - Thursday, August 25, 2016 - link
https://www.asus.com/Motherboards/SABERTOOTH_990FX...Outlander_04 - Thursday, August 25, 2016 - link
A little misleading . The Graphics pci-e controller is built in to an FX processor so adding a pci-e 3 standard slot to a motherboard will make no difference to actual bandwidth.Not an issue though since x16 pci-e 2 has the same bandwidth as x8 pci-e 3 and intel boards with SLI/crossfire ability running at x8/x8 do not choke any current graphics card
h4rm0ny - Thursday, August 25, 2016 - link
What about PCI-E SSDs? Can I get full bandwidth on those? I agree about the graphics cards but that's not so important to me. If I can get full PCI-Ev3 x4 performance for an SSD then I'll pribably buy this as a hold-over until Zen. Thanks fir the link!fanofanand - Friday, August 26, 2016 - link
Pci-e 3.0 x4 should be the same as 2.0 x 8. So long as you have a vacant x8 it should theoretically work the same.extide - Wednesday, September 7, 2016 - link
I think they use a PLX chip and turn the 32 2.0 lanes from the FX chip into 16 3.0 lanes.