AMD Carrizo Part 2: A Generational Deep Dive into the Athlon X4 845 at $70
by Ian Cutress on July 14, 2016 9:00 AM ESTLegacy Benchmarks at 3 GHz
Some of our legacy benchmarks have followed AnandTech for over a decade, showing how performance changes when the code bases stay the same in that period. Some of this software is still in common use today.
All of our benchmark results can also be found in our benchmark engine, Bench.
3D Particle Movement v1
3DPM is a self-penned benchmark, taking basic 3D movement algorithms used in Brownian Motion simulations and testing them for speed. High floating point performance, MHz and IPC wins in the single thread version, whereas the multithread version has to handle the threads and loves more cores. This is the original version, written in the style of a typical non-computer science student coding up an algorithm for their theoretical problem, and comes without any non-obvious optimizations not already performed by the compiler, such as false sharing.
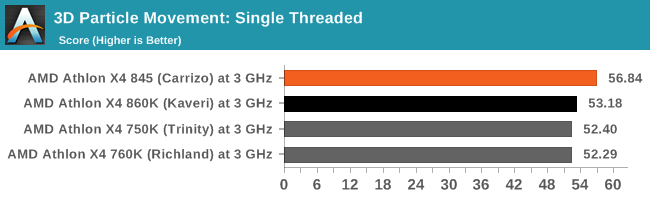
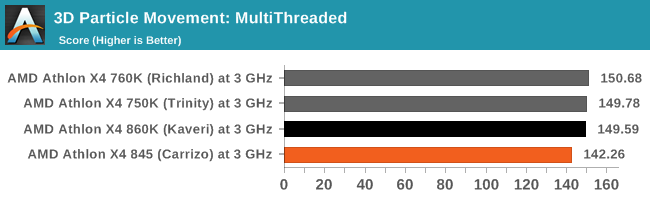
We ran 3DPM v2 earlier in the review, and it showed significant gains for Carrizo when running software that is not competing for data in shared cache lines. This older version of that benchmark still has those 'base CS' flaws that a non-CompSci science student might make, and while Carrizo has a small gain in single threaded mode, moving to multithreaded puts some strain on the caches, resulting in lower performance.
Cinebench 11.5 and 10
Cinebench is a widely known benchmarking tool for measuring performance relative to MAXON's animation software Cinema 4D. Cinebench has been optimized over a decade and focuses on purely CPU horsepower, meaning if there is a discrepancy in pure throughput characteristics, Cinebench is likely to show that discrepancy. Arguably other software doesn't make use of all the tools available, so the real world relevance might purely be academic, but given our large database of data for Cinebench it seems difficult to ignore a small five minute test. We run the modern version 15 in this test, as well as the older 11.5 and 10 due to our back data.
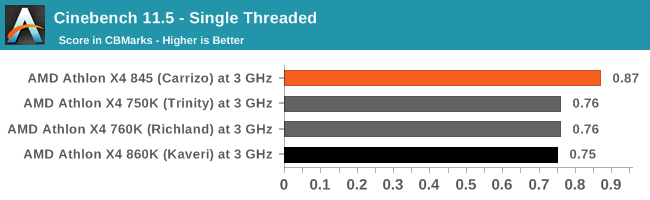
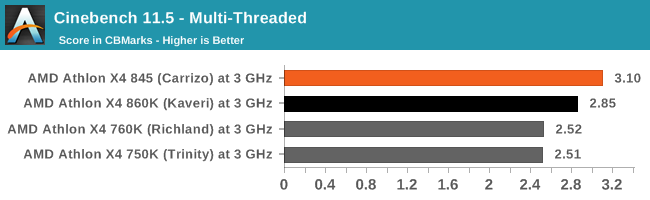
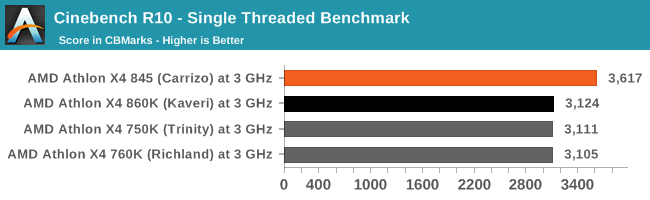
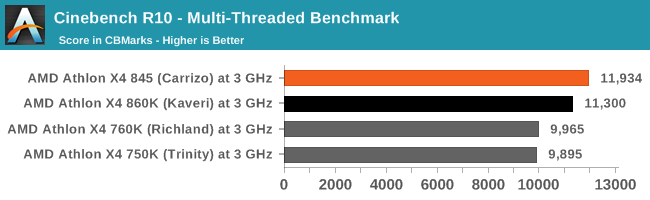
On the older versions of CineBench, like the newer ones, Carrizo has some notable microarchitectural advantages over Kaveri and previous versions of the Bulldozer microarchitecture.
POV-Ray 3.7
POV-Ray is a common ray-tracing tool used to generate realistic looking scenes. We've used POV-Ray in its various guises over the years as a good benchmark for performance, as well as a tool on the march to ray-tracing limited immersive environments. We use the built-in multithreaded benchmark.
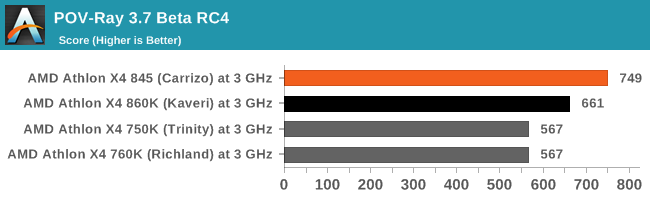
For our base ray tracing benchmark in Windows, again Carrizo pulls out a lead. This time it's around 13% over Kaveri or 32% over Trinity/Richland.
TrueCrypt 7.1
Before its discontinuation, TrueCrypt was a popular tool for WindowsXP to offer software encryption to a file system. The version we use for our tests, 7.1, is still widely used however the developers have stopped supporting it since the introduction of encrypted disk support in Windows 8/7/Vista from 5/2014, and as such any new security issues are unfixed. The benchmark itself is a good representation of microarchitectural advantages for base encryption methods.
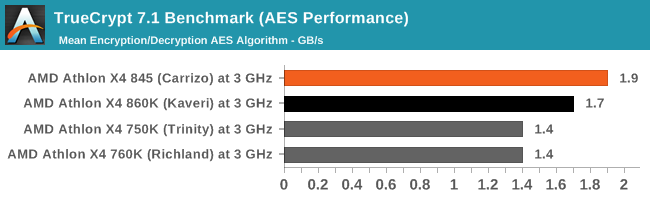
The AES performance for Carrizo is notably above Trinity/Richland, and pulls a 12% gain over Kaveri as well.
x264 HD 3.0
Similarly, the x264 HD 3.0 package we use here is also kept for historic regressional data. The latest version is 5.0.1, and encodes a 1080p video clip into a high quality x264 file. Version 3.0 only performs the same test on a 720p file, and in most circumstances the software performance hits its limit on high end processors, but still works well for mainstream and low-end. Also, this version only takes a few minutes, whereas the latest can take over 90 minutes to run.
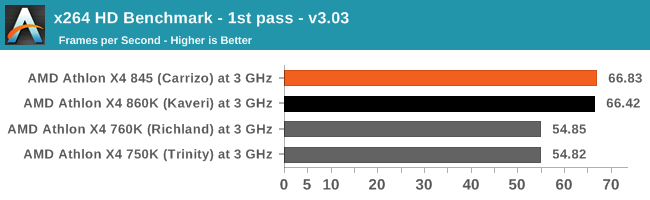
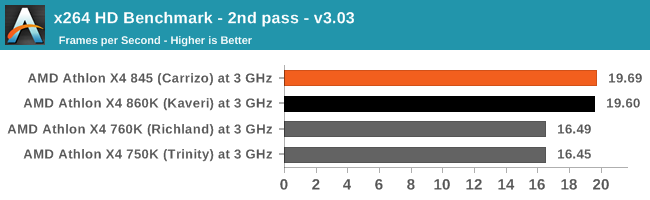
Using slightly older conversion tools shows that Carrizo and Kaveri, when the frames are small, are essentially neck and neck for performance (but still 20% over Trinity/Richland).
7-zip
7-Zip is a freeware compression/decompression tool that is widely deployed across the world. We run the included benchmark tool using a 50MB library and take the average of a set of fixed-time results.
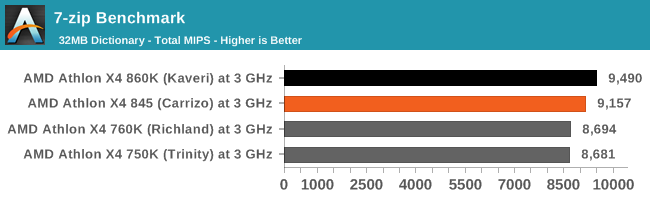
The 2MB of L2 cache for Carrizo hurts here. It makes we wonder how much more performance a 4MB cache would provide.








131 Comments
View All Comments
lefty2 - Thursday, July 14, 2016 - link
I'm predicting Bristol Ridge will be just as bad a failure as Carrizo. I.e. the few design wins will only have single DIMM memory and be universally unavailable, buried somewhere in a dark corner of the OEM's website. It's a pity, because both SoCs are very good in their own right.nandnandnand - Thursday, July 14, 2016 - link
If it's not Zen, it can be thrown straight in the garbage.Samus - Friday, July 15, 2016 - link
I still rock a few Kaveri desktops and they are incredibly powerful for the price. The 860K is half the cost of a comparable Intel chip, which supporting faster memory and a lower cost platform.Carizo on the desktop is an anomaly. I'd like to see what it could do with 4MB cache (would require an entirely new die)
Lolimaster - Saturday, July 16, 2016 - link
They were nice in 2014.We should have a nice 20nm 768SP APU in 2015 with a full L2 cache Excavator and fully mature 896SP 20nm early this year.
Remember the A8 3870K? That APU was a damn monster only hold back from being godly cause of their sub 3Ghz cpu speed, what we had after?
400SP VLIW5 2011 --> 384 VLIW4 2012 --> 384VLIW4 2013 --> 512SP GCN 2015 --> 512SP GCN 2016
Intel improved way faster (non "e" + edram igp's are near A8 level from being utter trash when the A8 3850 was release).
The_Countess - Tuesday, July 19, 2016 - link
yes being able to thrown in a extra billion transistors compared to AMD (1.7 vs 0.75 billion transistors for a quad core with GPU) because of 14nm really does help intel along a lot.but as nobody has been able to make a 20nm class process for anything but flash and ram besides intel, AMD's hands were tied. there is nothing AMD could have done to change that.
BlueBlazer - Friday, July 15, 2016 - link
Formula for failure: FM2 socket (with limited CPU upgradeability), only PCI Express x8 lanes available (which can bottleneck GPUs), and only "4 cores" (which performs more like 2C/4T Core i3 processor).neblogai - Friday, July 15, 2016 - link
Bristol Ridge is not FM2; PCI-E x8 can not bottleneck midrange GPUs; ultra low power mobile APU also sold as desktop chip is not a failure, just additional revenueBlueBlazer - Friday, July 15, 2016 - link
The results in the article shows otherwise, where AMD's Bristol Ridge was slower in most gaming tests, despite having better performance in some applications. Both FM2 and FM2+ are still the same (legacy) socket. AMD will be probably selling these chips at a loss. Note that these are the same (large) dies as Carrizo chips, and at 250mm^2 coupled with low prices typically meant razor thin margins or none at all.silverblue - Friday, July 15, 2016 - link
That L2 cache is probably making more difference than you realise.evolucion8 - Saturday, July 16, 2016 - link
The PCI-E is busted, even at PCI E 2.0 @ 4X, it barely makes a difference on the Fury X and the GTX 980 Ti.