The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
TSX
TSX or Transactional Synchronization Extensions is Intel's cache-based transactional memory system. Intel launched TSX with Haswell, but a bug threw a spanner in the works. Broadwell in turn got it right. The chicken is finally there, now it's time to enjoy the eggs.
Faster Virtualization
Virtualization overhead is (for most people) a thing of the past. The performance overhead with bare metal hypervisors (ESXi, Hyper-V, Xen, KVM..) is less than a few percent. There is one exception however: applications where I/O dominates. And of course, the packet switching telco applications are the prime examples. Intel, VMware and the server vendors really want to convert the telcos from their Firewall/Router/VPN "black boxes" to virtual ones using Software Defined Networking (SDN) infrastructure. To that end, Intel has continued to work on reducing the virtualization performance overhead. Virtualization overhead can be described as the number of VM exits (VM stops and hypervisor takes over) times the VM exit latency. In IO intensive application, VM exits happen frequently, which in turn leads to hard to predict and high IO latency, exactly what the telco people hate.
Intel wants to conquer the telco's datacenter by turning it into a SDN
So Intel worked on both factors. So Broadwell-DP VM exit latency is once again reduced from 500 cycles to 400.
It seems that the "ticks" also get a VM exit reduction. This slide of the Ivy Bride EP presentation gives you a very good overview of the VM exits in a network intensive application; in this case a networkd bandwidth benchmark application.
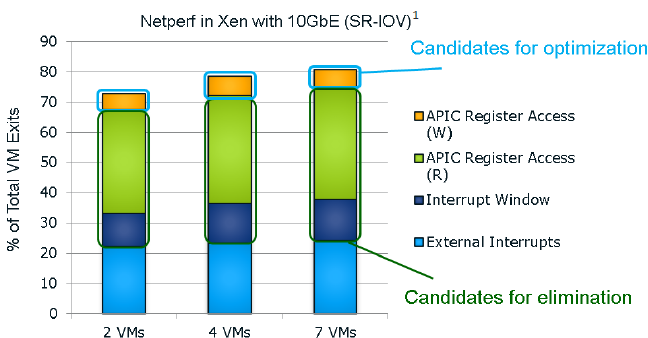
I quote from our Ivy Bridge-EP review:
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparently, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
In summary, Intel eliminated the green and dark blue components of the VM exit overhead with APICv. Broadwell now takes on the VM exits due to the external interrupts.
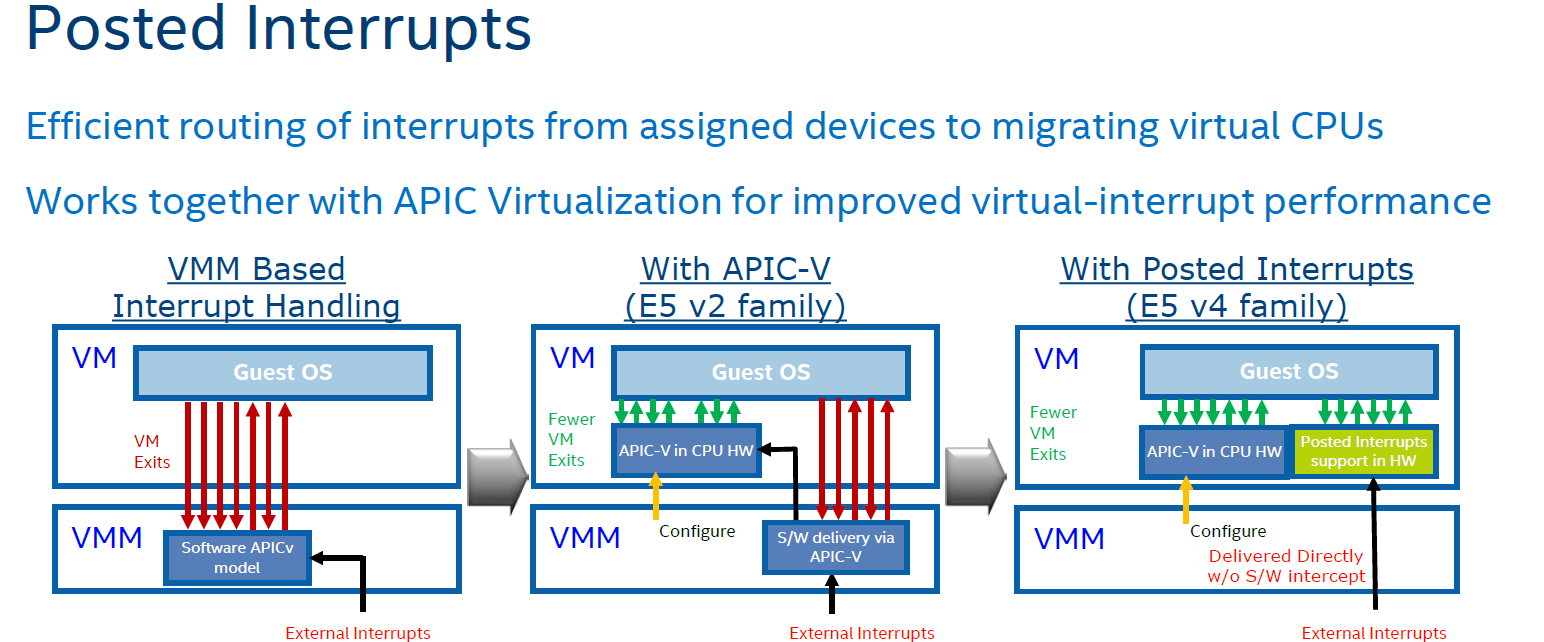
The technology on Broadwell-EP to do this is called posted interrupt. Essentially, posted interrupts enables direct interrupt delivery to the virtual machine without incurring a VM exit, courtesy of an interrupt remapping table. It is very similar to VT-D, which allowed DMA remapping thanks to the physical to virtual memory mapping table. Telco applications - among others - are very latency sensitive. Intel's Edwin Verplancke gave us one such example: before posted interrupts, a telco application had a latency varying from 4 to 47 (!) µsec, depending on the load. Posted interrupts made this a lot less variable, and latency varied from 2.4 to 5.2 µsecs.
As far as we are aware, KVM and Xen seem to have already implemented support for posted interrupts.








112 Comments
View All Comments
iwod - Thursday, March 31, 2016 - link
Maximum memory still 768GB?What happen to the 5.1Ghz Xeon E5?
Ian Cutress - Thursday, March 31, 2016 - link
I never saw anyone with a confirmed source for that, making me think it's a faked rumor. I'll happily be proved wrong, but nothing like a 5.1 GHz part was announced today.Brutalizer - Saturday, April 2, 2016 - link
It would have been interesting to bench to the best cpu today, the SPARC M7. For instance:-SAP: two M7 cpu scores 169.000 saps vs 109.000 saps for two of this Broadwell-EP cpus
-Hadoop, sort 10TB data: one SPARC M7 server with four cpus, finishes the sort in 4,260 seconds. Whereas a cluster of 32 PCs equipped with dual E5-2680v2 finishes in 1,054 seconds, i.e. 64 Intel Xeon cpus vs four SPARC M7 cpus.
-TPC-C: one SPARC M7 server with one cpu gets 5,000,000 tpm, whereas one server with two E5-2699v3 cpus gets 3.600.000 tpm
-Memory bandwidth, Stream triad: one SPARC M7 reaches 145 GB/sec, whereas two of these Broadwell-EP cpus reaches 119GB/sec
-etc. All these benchmarks can be found here, and another 25ish benchmarks where SPARC M7 is 2-3x faster than E5-2699v3 or POWER8 (all the way up to 11x faster):
https://blogs.oracle.com/BestPerf/entry/20151025_s...
Brutalizer - Saturday, April 2, 2016 - link
BTW, all these SPARC M7 benchmarks are almost unaffected if encryption is turned on, maybe 2-5% slower. Whereas if you turn on encryption for x86 and POWER8, expect performance to halve or even less. Just check the benchmarks on the link above, and you will see that SPARC M7 benchmarks are almost unaffected encrypted or not.JohanAnandtech - Saturday, April 2, 2016 - link
"if you turn on encryption for x86 and POWER8, expect performance to halve or even less". And this is based upon what measurement? from my measurements, both x86 and POWER8 loose like 1-3% when AES encryption is on. RSA might be a bit worse (2-10%), but asymetric encryption is mostly used to open connections.Brutalizer - Wednesday, April 6, 2016 - link
If we talk about how encryption affects performance, lets look at this benchmark below. Never mind the x86 is slower than the SPARC M7, let us instead look at how encryption affects the cpus. What performance hit has encryption?https://blogs.oracle.com/BestPerf/entry/20160315_t...
-For x86 we see that two E5-2699v3 cpus utilization goes from 40% without crypto, up to 80% with crypto. This leaves the x86 server with very little headroom to do anything else than executing one query. At the same time, the x86 server took 25-30% longer time to process the query. This shows that encryption has a huge impact on x86. You can not do useful work with two x86 cpus, except executing a query. If you need to do additional work, get four x86 xeons instead.
-If we look at how SPARC M7 gets affected by encryption, we see that cpu utilization went up from 30% up to 40%. So you have lot of headroom to do additional work while processing the query. At the same time, the SPARC cpu took 2% longer time to process the query.
It is not really interesting that this single SPARC M7 cpu is 30% faster than two E5-2699v3 in absolute numbers. No, we are looking at how much worse the performance gets affected when we turn on encryption. In case of x86, we see that the cpus gets twice the load, so they are almost fully loaded, only by turning on encryption. At the same time taking longer time to process the work. Ergo, you can not do any additional work with x86 with crypto. With SPARC, it ends up with 40% cpu utilization so you can do additional work on SPARC, and process time does not increase at all (2%). This proves that x86 encryption halves performance or worse.
For your own AES encryption benchmark, you should also see how much cpu utilization goes up. If it gets fully loaded, you can not do any useful work except handling encryption. So you need an additional cpu to do the actual work.
JohanAnandtech - Saturday, April 2, 2016 - link
Two M7 machines start at 90k, while a dual Xeon is around 20k. And most of those Oracle are very intellectually dishonest: complicated configurations to get the best out of the M7 machines, midrange older x86 configurations (10-core E5 v2, really???)Brutalizer - Wednesday, April 6, 2016 - link
The "dishonest" benchmarks from Oracle, are often (always?) using what is published. If for instance, IBM only has one published benchmark, then Oracle has no other choice than use it, right? Of course when there are faster IBM benchmarks out there, Oracle use that. Same with x86. In all these 25ish cases we see that SPARC M7 is 2-3x faster, all the way up to 11x faster. The benhcmarks vary very much, raw compute power, databases, deep learning, SAP, etc etcPhil_Oracle - Thursday, May 12, 2016 - link
I disagree Johan! You don't appear to know much about the new SPARC M7 systems and suggest you do a full evaluation before making such remarks. A SPARC T7-1 with 32-cores has a list price of about $39K outperforms a 2-socket 36-core E5-2699v3 anywhere from 38% (OLTP HammerDB) to over 8x faster (OLTP w/ in-memory analytics). A similarly configured *enterprise* class 2-socket 36-core E5-2699v3 from HPE or Cisco lists for $25K+, so in terms of price/performance, the SPARC T7-1 beats the 2-socket E5-2699v3. And if you take into account SW that’s licensed per core, the SPARC M7 is 60% to 2.6x faster/core, dramatically lowering licensing costs. With the new E5-2699v4, providing ~20% more cores at roughly the same price, gets closer, but with performance/core not changing much with E5 v4, SPARC M7 still has a huge lead. And the difference is while the E5 v3/v4 chips don't scale beyond 2-socket, you can get an SPARC M7 system up to 16-sockets with the almost identical price/performance of the 1-socket system.adamod - Friday, June 3, 2016 - link
BUT CAN IT PLAY CRYSIS?????