The AMD Radeon R9 Fury Review, Feat. Sapphire & ASUS
by Ryan Smith on July 10, 2015 9:00 AM ESTCompute
Shifting gears, we have our look at compute performance. As compute performance will be more significantly impacted by the reduction in CUs than most other tests, we’re expecting the performance hit for the R9 Fury relative to the R9 Fury X to be more significant here than under our gaming tests.
Starting us off for our look at compute is LuxMark3.0, the latest version of the official benchmark of LuxRender 2.0. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
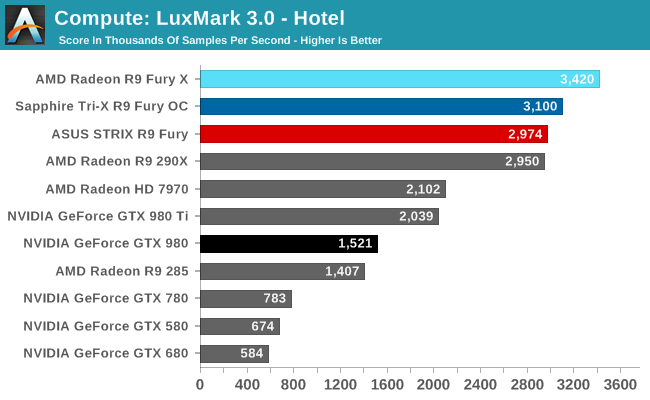
For LuxMark with the R9 Fury X already holding the top spot, the R9 Fury cards easily take the next two spots. One interesting artifact of this is that the R9 Fury’s advantage over the GTX 980 is actually greater than the R9 Fury X’s over the GTX 980 Ti’s, both on an absolute and relative basis. This despite the fact that the R9 Fury is some 13% slower than its fully enabled sibling.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.

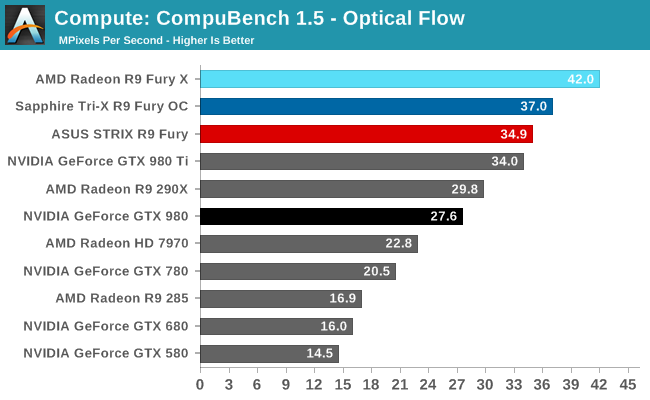
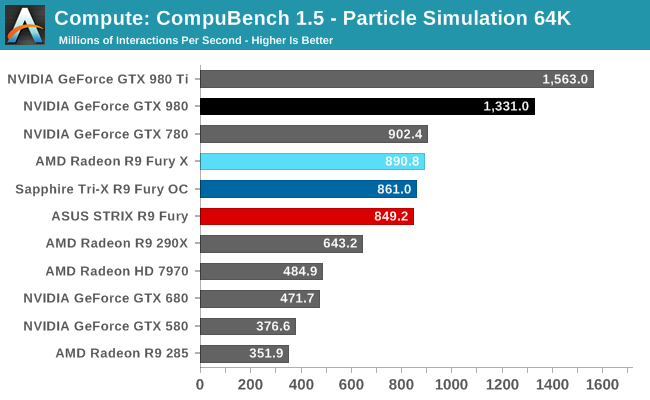
Not unlike LuxMark, tests where the R9 Fury X did well have the R9 Fury doing well too, particularly the optical flow sub-benchmark. The drop-off in that benchmark and face detection is about what we’d expect for losing 1/8th of Fiji’s CUs. On the other hand the particle simulation benchmark is hardly fazed beyond the clockspeed drop, indicating that the bottleneck lies elsewhere.
Our 3rd compute benchmark is Sony Vegas Pro 13, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
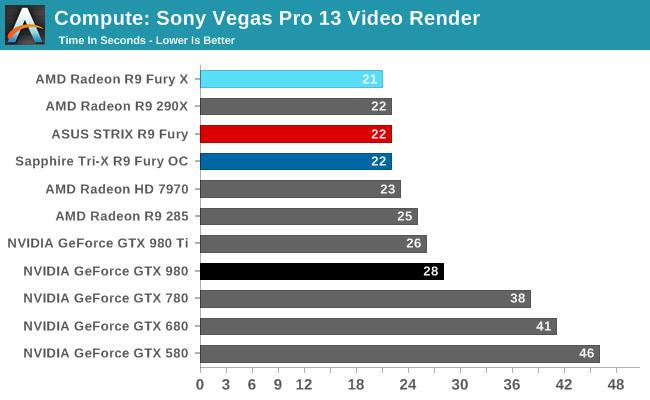
At this point Vegas is becoming increasingly CPU-bound and will be due for replacement. The R9 Fury comes in one second behind the chart-topping R9 Fury X, at 22 seconds.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.



Overall while the R9 Fury doesn’t have to aim quite as high given its weaker GTX 980 competition, FAHBench still stresses the Radeon cards. Under single precision tests the GTX 980 pulls ahead, only surpassed under double precision thanks to NVIDIA’s weaker FP64 performance.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

As with our other tests the R9 Fury loses some performance on our C++ AMP benchmark relative to the R9 Fury X, but only around 8%. As a result it’s competitive with the GTX 980 Ti here, blowing well past the GTX 980.








288 Comments
View All Comments
nightbringer57 - Friday, July 10, 2015 - link
Intel kept it in stock for a while but it didn't sell. So the management decided to get rid of it, gave it away to a few colleagues (dell, HP, many OEMs used BTX for quite a while, both because it was a good user lock-down solution and because the inconvenients of BTX didn't matter in OEM computers, while the advantages were still here) and noone ever heard of it on the retail market again?nightbringer57 - Friday, July 10, 2015 - link
Damn those not-editable comments...I forgot to add: with the switch from the netburst.prescott architecture to Conroe (and its followers), CPU cooling became much less of a hassle for mainstream models so Intel did not have anything left to gain from the effort put into BTX.
xenol - Friday, July 10, 2015 - link
It survived in OEMs. I remember cracking open Dell computers in the later half of 2000 and finding out they were BTX.yuhong - Friday, July 10, 2015 - link
I wonder if a BTX2 standard that fixes the problems of original BTX is a good idea.onewingedangel - Friday, July 10, 2015 - link
With the introduction of HBM, perhaps it's time to move to socketed GPUs.It seems ridiculous for the industry standard spec to devote so much space to the comparatively low-power CPU whilst the high-power GPU has to fit within the confines of (multiple) pci-e expansion slots.
Is it not time to move beyond the confines of ATX?
DanNeely - Friday, July 10, 2015 - link
Even with the smaller PCB footprint allowed by HBM; filling up the area currently taken by expansion cards would only give you room for a single GPU + support components in an mATX sized board (most of the space between the PCIe slots and edge of the mobo is used for other stuff that would need to be kept not replaced with GPU bits); and the tower cooler on top of it would be a major obstruction for any non-GPU PCIe cards you might want to put into the system.soccerballtux - Friday, July 10, 2015 - link
man, the convenience of the socketed GPU is great, but just think of how much power we could have if it had it's own dedicated card!meacupla - Friday, July 10, 2015 - link
The clever design trend, or at least what I think is clever, is where the GPU+CPU heatsinks are connected together, so that, instead of many smaller heatsinks trying to cool one chip each, you can have one giant heatsink doing all the work, which can result in less space, as opposed to volume, being occupied by the heatsink.You can see this sort of design on high end gaming laptops, Mac Pro, and custom water cooling builds. The only catch is, they're all expensive. Laptops and Mac Pro are, pretty much, completely proprietary, while custom water cooling requires time and effort.
If all ATX mobos and GPUs had their core and heatsink mounting holes in the exact same spot, it would be much easier to design a 'universal multi-core heatsink' that you could just attach to everything that needs it.
Peichen - Saturday, July 11, 2015 - link
That's quite a good idea. With heat-pipes, distance doesn't really matter so if there is a CPU heatsink that can extend 4x 8mm/10mm heatpipes over the videocard to cooled the GPU, it would be far quieter than the 3x 90mm can cooler on videocard now.FlushedBubblyJock - Wednesday, July 15, 2015 - link
330 watts transferred to the low lying motherboard, with PINS attached to amd's core failure next...Slap that monster heat onto the motherboard, then you can have a giant green plastic enclosure like Dell towers to try to move that heat outside the case... oh, plus a whole 'nother giant VRM setup on the motherboard... yeah they sure will be doing that soon ... just lay down that extra 50 bucks on every motherboard with some 6X VRM's just incase amd fanboy decides he wants to buy the megawatter amd rebranded chip...
Yep, NOT HAPPENING !