The AMD Radeon R9 Fury Review, Feat. Sapphire & ASUS
by Ryan Smith on July 10, 2015 9:00 AM ESTCompute
Shifting gears, we have our look at compute performance. As compute performance will be more significantly impacted by the reduction in CUs than most other tests, we’re expecting the performance hit for the R9 Fury relative to the R9 Fury X to be more significant here than under our gaming tests.
Starting us off for our look at compute is LuxMark3.0, the latest version of the official benchmark of LuxRender 2.0. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
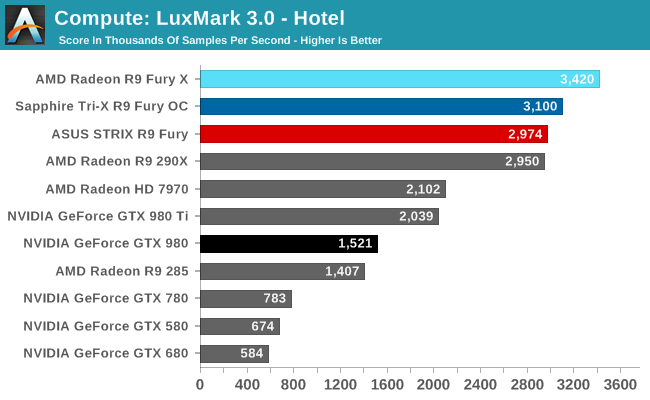
For LuxMark with the R9 Fury X already holding the top spot, the R9 Fury cards easily take the next two spots. One interesting artifact of this is that the R9 Fury’s advantage over the GTX 980 is actually greater than the R9 Fury X’s over the GTX 980 Ti’s, both on an absolute and relative basis. This despite the fact that the R9 Fury is some 13% slower than its fully enabled sibling.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.

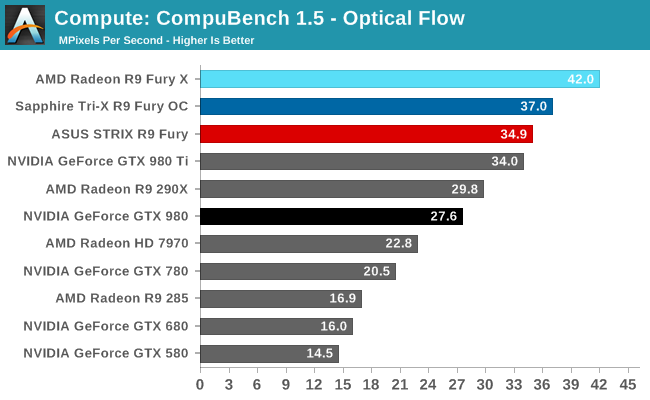
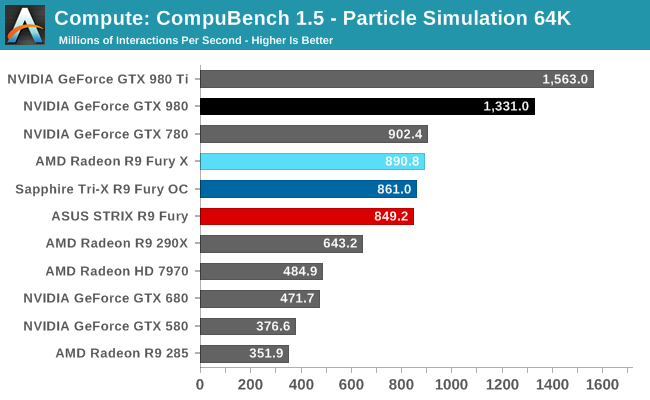
Not unlike LuxMark, tests where the R9 Fury X did well have the R9 Fury doing well too, particularly the optical flow sub-benchmark. The drop-off in that benchmark and face detection is about what we’d expect for losing 1/8th of Fiji’s CUs. On the other hand the particle simulation benchmark is hardly fazed beyond the clockspeed drop, indicating that the bottleneck lies elsewhere.
Our 3rd compute benchmark is Sony Vegas Pro 13, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
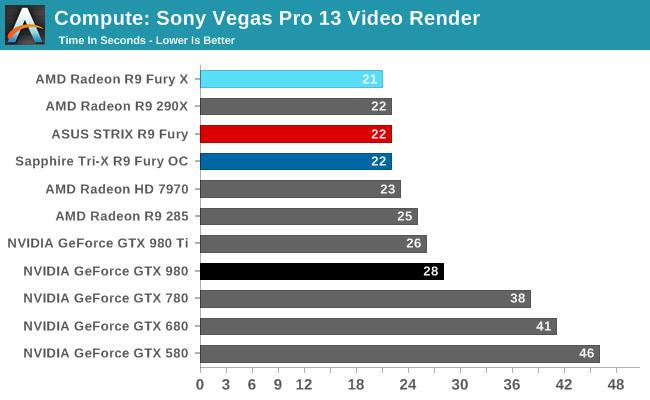
At this point Vegas is becoming increasingly CPU-bound and will be due for replacement. The R9 Fury comes in one second behind the chart-topping R9 Fury X, at 22 seconds.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.



Overall while the R9 Fury doesn’t have to aim quite as high given its weaker GTX 980 competition, FAHBench still stresses the Radeon cards. Under single precision tests the GTX 980 pulls ahead, only surpassed under double precision thanks to NVIDIA’s weaker FP64 performance.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

As with our other tests the R9 Fury loses some performance on our C++ AMP benchmark relative to the R9 Fury X, but only around 8%. As a result it’s competitive with the GTX 980 Ti here, blowing well past the GTX 980.








288 Comments
View All Comments
bill.rookard - Friday, July 10, 2015 - link
Impressive results, especially by the Sapphire card. The thing I'm glad to see is that it's such a -quiet- card overall. That bodes well for some of the next releases (I'm dying to see the results of the Nano) and bodes well for AMD overall.Two things I'd like to see:
1) HBM on APU. Even if it were only 1GB or 2GB with an appropriate interface (imaging keeping the 4096 bit interface and either dual or quad-pumping the bus?). The close location of being on-die and high speed of the DRAM would be a very, VERY interesting graphics solution.
2) One would expect that with the cut down on resources, there would have been more of a loss in performance. On average, you see a 7-8% drop in speed after a loss of 13-14% cut in hardware resources and a slight drop in clock speeds. So - where does that mean the bottleneck in the card is? It's possible that something is a bit lopsided internally (it does however perform exceptionally well), so it would be very interesting to tease out the differences to see whats going on inside the card.
mr_tawan - Friday, July 10, 2015 - link
It would be very interesting to run HBM as the system ram instead of DDR on APU. 4GB (for the 1) wouldn't be a lot and may choke on heavy work load, but for casual user (and tablet uses) that's probably enough.It would also allow smaller machine than NUC form factor, I think.
looncraz - Friday, July 10, 2015 - link
HBM wouldn't be terribly well suited for system RAM due to its comparatively low small-read performance and physical form factor. On an APU, for example, it would probably be best used as a single HBM[2] chip on a 1024-bit bus. Probably just 1 or 2GB, largely dedicated to graphics. That is 128GB/s with HBM1 (but 1GB max), 256GB/s with HBM2 (with, IIRC, 4GB max).For a SoC, though, such as the NUC form factor, as you mentioned, it is potentially a game changer only AMD can deliver on x86. Problem is that the net profit margins in that category are quite small, and AMD needs to be chasing higher net margin markets (net margin being a simple result of market volume, share, and product margin).
I'd love to see it, though, for laptops. And with Apple and AMD being friendly, we may end up seeing it. As well as probably seeing it find its way into the next generation of consoles.
Oxford Guy - Saturday, July 11, 2015 - link
Given the high prices Intel is charging for its NUC systems are you really certain it's not profitable? Perhaps sales aren't good because they're overpriced.Stuka87 - Friday, July 10, 2015 - link
The only way to keep the 4096bit bus would be to use four HBM chips, and I highly doubt this would be the case. I am thinking an APU would use either a single HBM chip, or possibly two. The performance boost would still be huge.ajlueke - Friday, July 10, 2015 - link
1) I can't imagine we won't see this. APU scaling with RAM speed was pretty well documented, I would be surprised if there were socket AM4 motherboards that incorporated some amount of HBM directly. Also, AMD performs best against NVidia at 4K, suggesting that Maxwell may be running into a memory bandwidth bottleneck itself. It will be interesting to see how Pascal performs when you couple a die-shrink with the AMD developed HBM2.2) It does suggest that Fiji derives far more benefit from faster clocks versus more resources. That makes the locked down voltages for the Fury X even more glaring. You supply a card that is massively overpowered, with 500W of heat dissipation but no way to increase voltages to really push the clock speed? I hope we get custom BIOS for that card soon.
silverblue - Saturday, July 11, 2015 - link
As regards APU scaling, it's a tough one. More bandwidth is good, however scaling drops above 2133MHz which shows you'd need more hardware to consume it. Would you put in more shaders, or ROPs? I'd go for the latter - don't APUs usually top out at 8 ROPs? Sure, add in more bandwidth, but at the very least, increase how much the APU can actually draw. The HD 4850 had 32 TMUs (like the 7850K) but 16 ROPs, which is double that on offer here.I keep seeing complaints about AMD's ROP count, so perhaps there's some merit to them.
Nagorak - Sunday, July 12, 2015 - link
It's hard to say what the bottleneck is with memory scaling on APUs. It could be something related to the memory controller built into the CPU rather than the GPU not having the resources to benefit.silverblue - Monday, July 13, 2015 - link
Isn't there a 256-bit Radeon Memory Bus link between memory and the GPU? Just a question.Stuka87 - Friday, July 10, 2015 - link
Is it just me, or is the 290X faster now than it used to be when compared to the 980? Perhaps the 15.7 drivers offered some more performance?