The AMD Radeon R9 Fury X Review: Aiming For the Top
by Ryan Smith on July 2, 2015 11:15 AM ESTCompute
Shifting gears, we have our look at compute performance. As an FP64 card, the R9 Fury X only offers the bare minimum FP64 performance for a GCN product, so we won’t see anything great here. On the other hand with a theoretical FP32 performance of 8.6 TFLOPs, AMD could really clean house on our more regular FP32 workloads.
Starting us off for our look at compute is LuxMark3.0, the latest version of the official benchmark of LuxRender 2.0. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
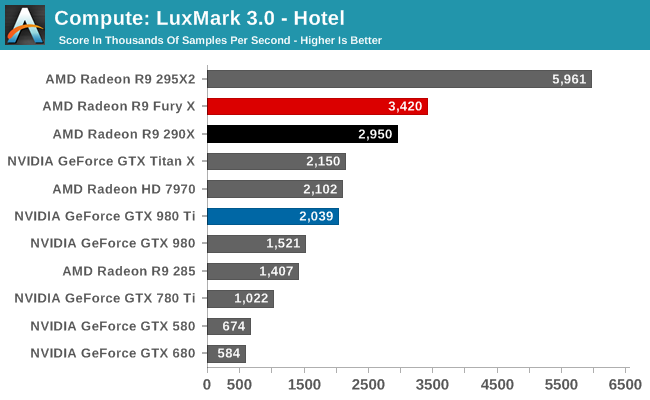
The results with LuxMark ended up being quite a bit of a surprise, and not for a good reason. Compute workloads are shader workloads, and these are workloads that should best illustrate the performance improvements of R9 Fury X over R9 290X. And yet while the R9 Fury X is the fastest single GPU AMD card, it’s only some 16% faster, a far cry from the 50%+ that it should be able to attain.
Right now I have no reason to doubt that the R9 Fury X is capable of utilizing all of its shaders. It just can’t do so very well with LuxMark. Given the fact that the R9 Fury X is first and foremost a gaming card, and OpenCL 1.x traction continues to be low, I am wondering whether we’re seeing a lack of OpenCL driver optimizations for Fiji.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.

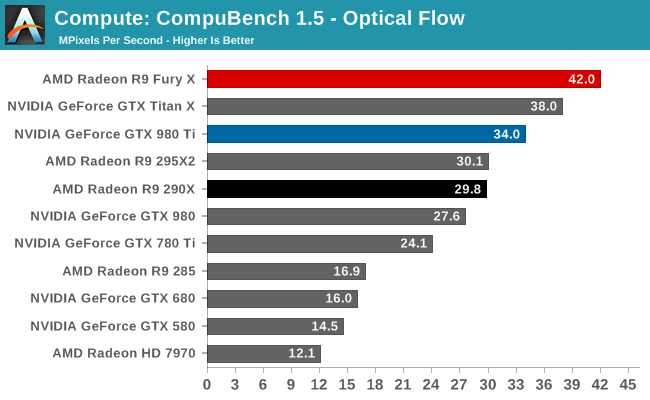
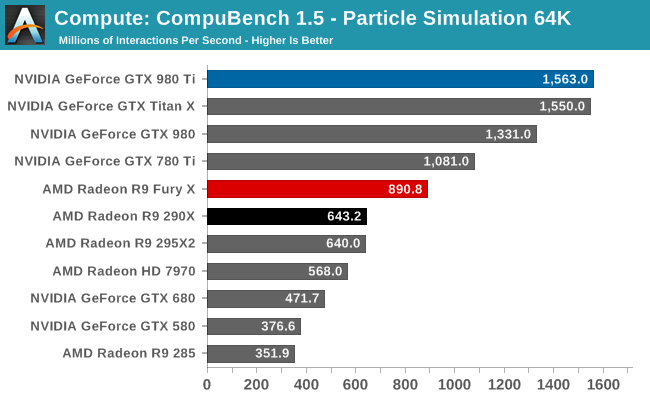
Quickly taking some of the air out of our driver theory, the R9 Fury X’s performance on CompuBench is quite a bit better, and much closer to what we’d expect given the hardware of the R9 Fury X. The Fury X only wins overall at Optical Flow, a somewhat memory-bandwidth heavy test that to no surprise favors AMD’s HBM additions, but otherwise the performance gains across all of these tests are 40-50%. Overall then the outcome over who wins is heavily test dependent, though this is nothing new.
Our 3rd compute benchmark is Sony Vegas Pro 13, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
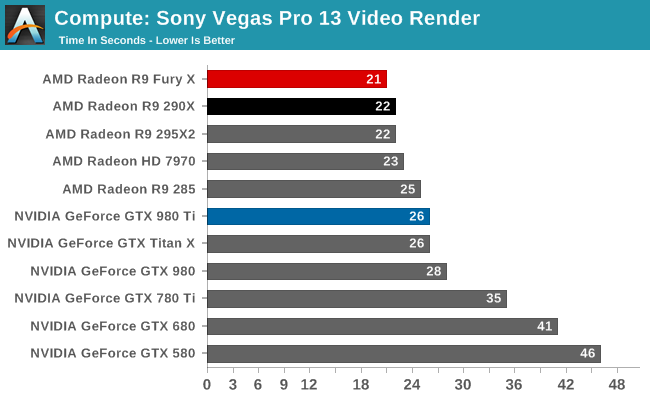
At this point Vegas is becoming increasingly CPU-bound and will be due for replacement. The Fury X none the less shaves off an additional second of rendering time, bringing it down to 21 seconds.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.



Both of the FP32 tests for FAHBench show smaller than expected performance gains given the fact that the R9 Fury X has such a significant increase in compute resources and memory bandwidth. 25% and 34% respectively are still decent gains, but they’re smaller gains than anything we saw on CompuBench. This does lend a bit more support to our theory about driver optimizations, though FAHBench has not always scaled well with compute resources to begin with.
Meanwhile FP64 performance dives as expected. With a 1/16 rate it’s not nearly as bad as the GTX 900 series, but even the Radeon HD 7970 is beating the R9 Fury X here.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
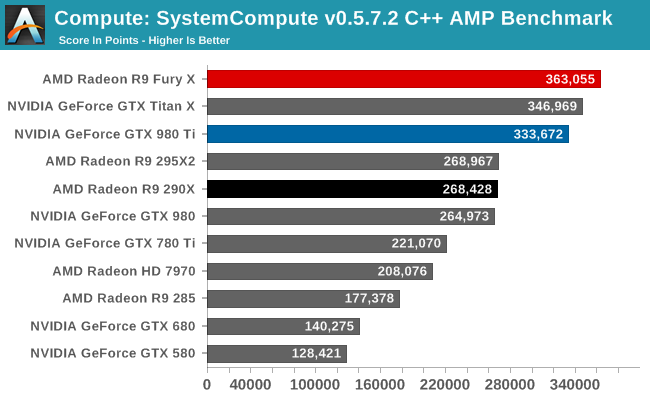
Our C++ AMP benchmark is another case of decent, though not amazing, GPU compute performance gains. The R9 Fury X picks up 35% over the R9 290X. And in fact this is enough to vault it over NVIDIA’s cards to retake the top spot here, though not by a great amount.








458 Comments
View All Comments
mikato - Tuesday, July 7, 2015 - link
Wow very interesting, thanks bugsy. I hope those guys at the various forums can work out the details and maybe a reputable tech reviewer will take a look.OrphanageExplosion - Saturday, July 4, 2015 - link
I'm still a bit perplexed about how AMD gets an absolute roasting for CrossFire frame-pacing - which only impacted a tiny amount of users - while the sub-optimal DirectX 11 driver (which will affect everyone to varying extents in CPU-bound scenarios) doesn't get anything like the same level of attention.I mean, AMD commands a niche when it comes to the value end of the market, but if you're combining a budget CPU with one of their value GPUs, chances are that in many games you're not going to see the same kind of performance you see from benchmarks carried out on mammoth i7 systems.
And here, we've reached a situation where not even the i7 benchmarking scenario can hide the impact of the driver on a $650 part, hence the poor 1440p performance (which is even worse at 1080p). Why invest all that R&D, time, effort and money into this mammoth piece of hardware and not improve the driver so we can actually see what it's capable of? Is AMD just sitting it out until DX12?
harrydr - Saturday, July 4, 2015 - link
With the black screen problem of r9 graphic cards not easy to support amd.Oxford Guy - Saturday, July 4, 2015 - link
Because lying to customers about VRAM performance, ROP count, and cache size is a far better way to conduct business.Oh, and the 970's specs are still false on Nvidia's website (claims 224 GB/s but that is impossible because of the 28 GB/s partition and the XOR contention — the more the slow partition is used the closer the other partition can get to the theoretical speed of 224 but the more it's used the more the faster partition is slowed by the 28 GB/s sloth — so a catch-22).
It's pretty amazing that Anandtech came out with a "Correcting the Specs" article but Nvidia is still claiming false numbers on their website.
Peichen - Monday, July 6, 2015 - link
And yet 970 is still faster. Nvidia is more efficient with resources than they let people on.Oxford Guy - Thursday, July 9, 2015 - link
The XOR contention and 28 GB/s sure is efficiency. If only the 8800 GT could have had VRAM that slow back in 2007.Gunbuster - Saturday, July 4, 2015 - link
Came for the chizow, was not disappointed.chizow - Monday, July 6, 2015 - link
:)madwolfa - Saturday, July 4, 2015 - link
"Throw a couple of these into a Micro-ATX SFF PC, and it will be the PSU, not the video cards, that become your biggest concern".I think the biggest concern here would be to fit a couple of 120mm radiators.
TheinsanegamerN - Saturday, July 4, 2015 - link
My current Micro-ATX case has room for dual 120mm rads and a 240mm rad. plenty of room there