The AMD Radeon R9 Fury X Review: Aiming For the Top
by Ryan Smith on July 2, 2015 11:15 AM ESTHigh Bandwidth Memory: Wide & Slow Makes It Fast
Architecturally, the single most notable addition to AMD’s collection of technologies for Fiji is High Bandwidth Memory (HBM). HBM is a next-generation memory standard that will ultimately come to many (if not all) GPUs as the successor to GDDR5. HBM promises a significant increase in memory bandwidth through the use of an ultra-wide, relatively low-clocked memory bus, with die stacked DRAM used to efficiently place the many DRAM dies needed to drive the wide bus.
As part of their pre-Fury X launch activities, AMD briefed the press on HBM back in May, offering virtually every detail one could want on HBM, how it worked, and the benefits of the technology. So for today’s launch there’s relatively little that’s new to say on the subject, but I wanted to quickly recap what we have seen so far.
After several years of GDDR5 – first used on the Radeon HD 4870 in 2008 – HBM comes at a time where GDDR5 is reaching its limits, and companies have been working on its successors. As awesome as GDDR5 is (and it delivers quite a bit of memory bandwidth compared to just about anything else), GDDR5 is already a bit of a power hog and rather complex to implement. GDDR5’s immediate successors would deliver more bandwidth, but they would also exacerbate this problem by drawing even more power and introducing all of the complexity inherent in differential I/O.

So to succeed GDDR5, AMD, Hynix, and the JEDEC as a whole have taken a very different path. Rather than attempting to push a very high bandwidth, narrow(ish) memory bus standard even higher, they have opted to go in the opposite direction with HBM. HBM would significantly back off of the clockspeeds used, but in return it would go wider than GDDR5. Much, much wider.
The ultimate direction that HBM takes us is with a very wide memory bus clocked at a low frequency. For Fiji, AMD has a 4096-bit memory bus clocked at 1000MHz (500MHz DDR). The use of such a wide bus more than offsets the reduction in clockspeed, allowing R9 Fury X to deliver 60% more memory bandwidth than the R9 290X’s GDDR5 implementation.

On the technical side of things, creating HBM has required a few different technologies to be created/improved in order to assemble the final product. The memory bus itself is rather simple (which is in and of itself a benefit), but a 4096-bit wide memory bus is by conventional standards absurdly wide. It requires thousands of contacts and traces, many times more than even 512-bit GDDR5 required (and that was already a lot).
To solve this problem HBM introduces the concept of a silicon interposer. With traditional packaging not up to the challenge of routing so many traces, the one material/package that is capable of hitting the necessary density is fabbed silicon, and thus the silicon interposer. Essentially a partially fabbed chip with just the metal layers but no logic, the interposer is a large chip whose purpose is to allow the ultra-wide 4096-bit memory bus to be created between a GPU and its VRAM, implemented as traces in the metal layers. The interposer itself is not especially complex, however because of the sheer size of the interposer (it needs to be large enough to hold the GPU and VRAM) the interposer brings with it its own challenges.
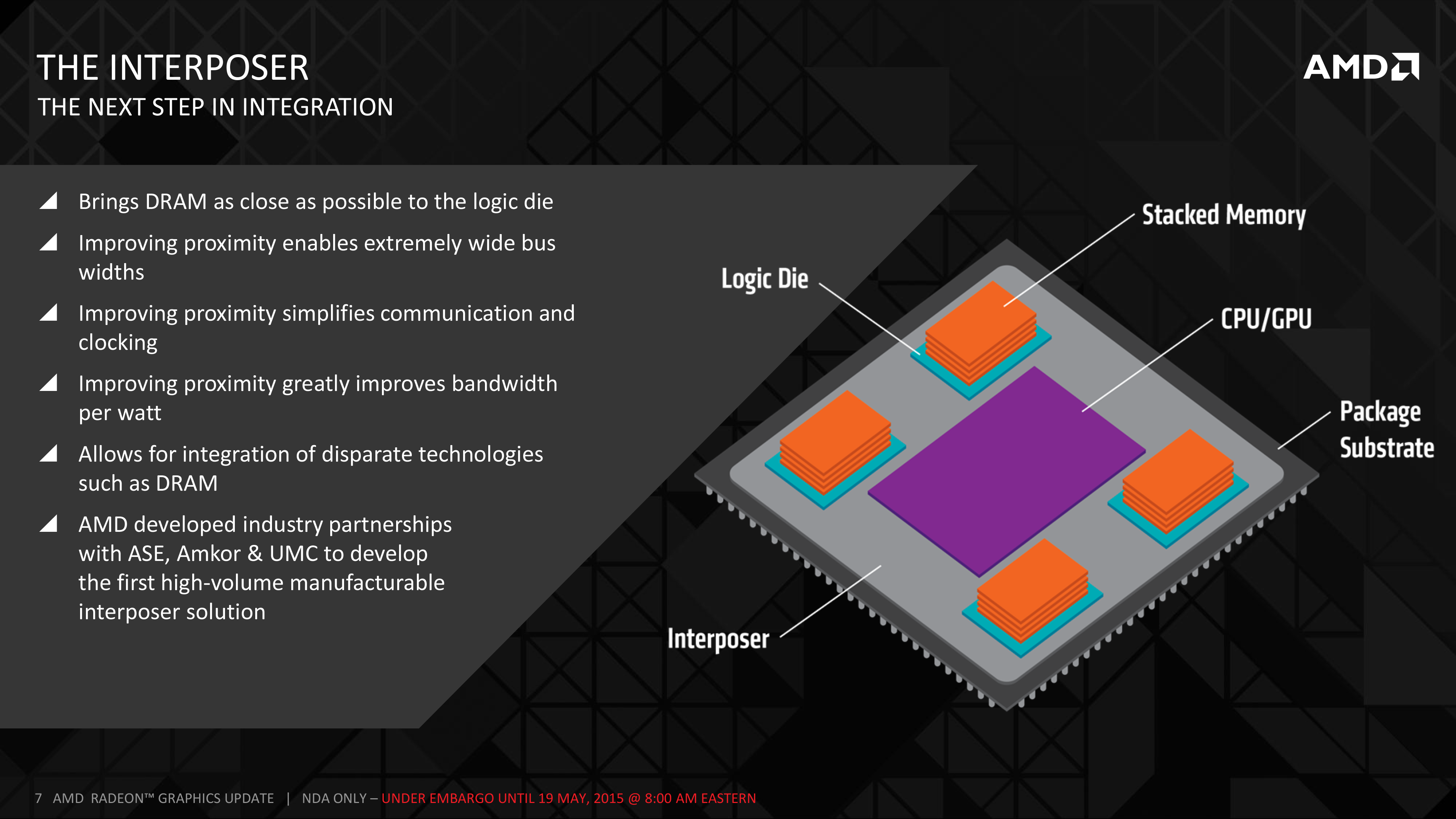
Meanwhile even though the interposer solves the immediate challenges of implementing a 4096-bit memory bus, the next issue that crops up is where to put the necessary DRAM dies. It takes 16 dies at 256-bits wide each to create the 4096-bit memory bus, and even at its largest size the interposer is still a fraction of the size of the PCB space that traditional GDDR5 chips occupy. As a result the DRAM required for an HBM solution needed to be denser than ever before in a 2D sense.
The solution to that problem was the creation of die-stacking the DRAM. If you can’t go wider, go taller, which is exactly what has happened with HBM. In HBM1 the stacks can go up to 4 dies high, allowing the necessary 16 dies to be reduced to a far more easily managed 4 stacks. With a base logic die at the bottom of each stack to serve as the PHY between the DRAM and the GPU (technically making the complete stack 5 dies), stacking the DRAM is what makes it practical to put so much RAM so close to the GPU.
The final new piece of technology in HBM comes in the die stacks themselves. With the need to route a 1024-bit memory bus through 4 memory dies, traditional package-on-package wire bonding is no longer sufficient. To connect up the memory dies, much like the interposer itself, a newer, denser connectivity method is required.
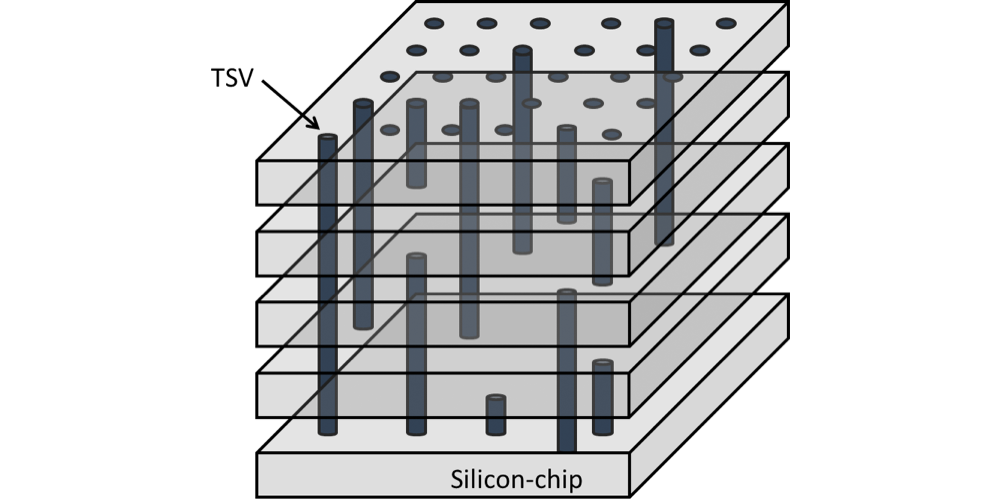
TSVs. Image Courtesy The International Center for Materials Nanoarchitectonics
To solve that problem, the HBM memory stacks implement Through-Silicon Vias, which involves running the vias straight through silicon devices in order to connect layers. The end result is something vaguely akin to DRAM dies surface mounted on top of each other via microbumps, but with the ability to communicate through the layers. From a manufacturing standpoint, between the silicon interposer and TSVs, TSVs are the more difficult technology to master as it essentially combines all the challenges of DRAM fabbing with the challenges of stacking those DRAM dies on top of each other.
Combined together as a single product, HBM is the next generation of GPU memory technology thanks to the fact that it offers multiple benefits over GDDR5. Memory bandwidth of course is a big part, but of similar significance is the power savings from HBM. The greatly simplified memory bus requires far less power be spent on the bus itself, and as a result the amount of power spent on VRAM is reduced. As we discussed earlier AMD is looking at a 20-30W VRAM power savings on R9 Fury X over R9 290X.
The third major benefit of HBM over GDDR5 goes back to the size benefits discussed earlier. Because all of the VRAM in an HBM setup fits on-chip, this frees up a significant amount of space. The R9 Fury X PCB is 3” shorter than the R9 290X PCB, and the bulk of these savings come from the space savings enjoyed by using HBM. Along with the immediate space savings of 4 small HBM stacks as opposed to 16 GDDR5 memory chips, AMD also gets to cut down on the amount of power delivery circuitry needed to support the VRAM, further saving space and some bill of material costs in the process.
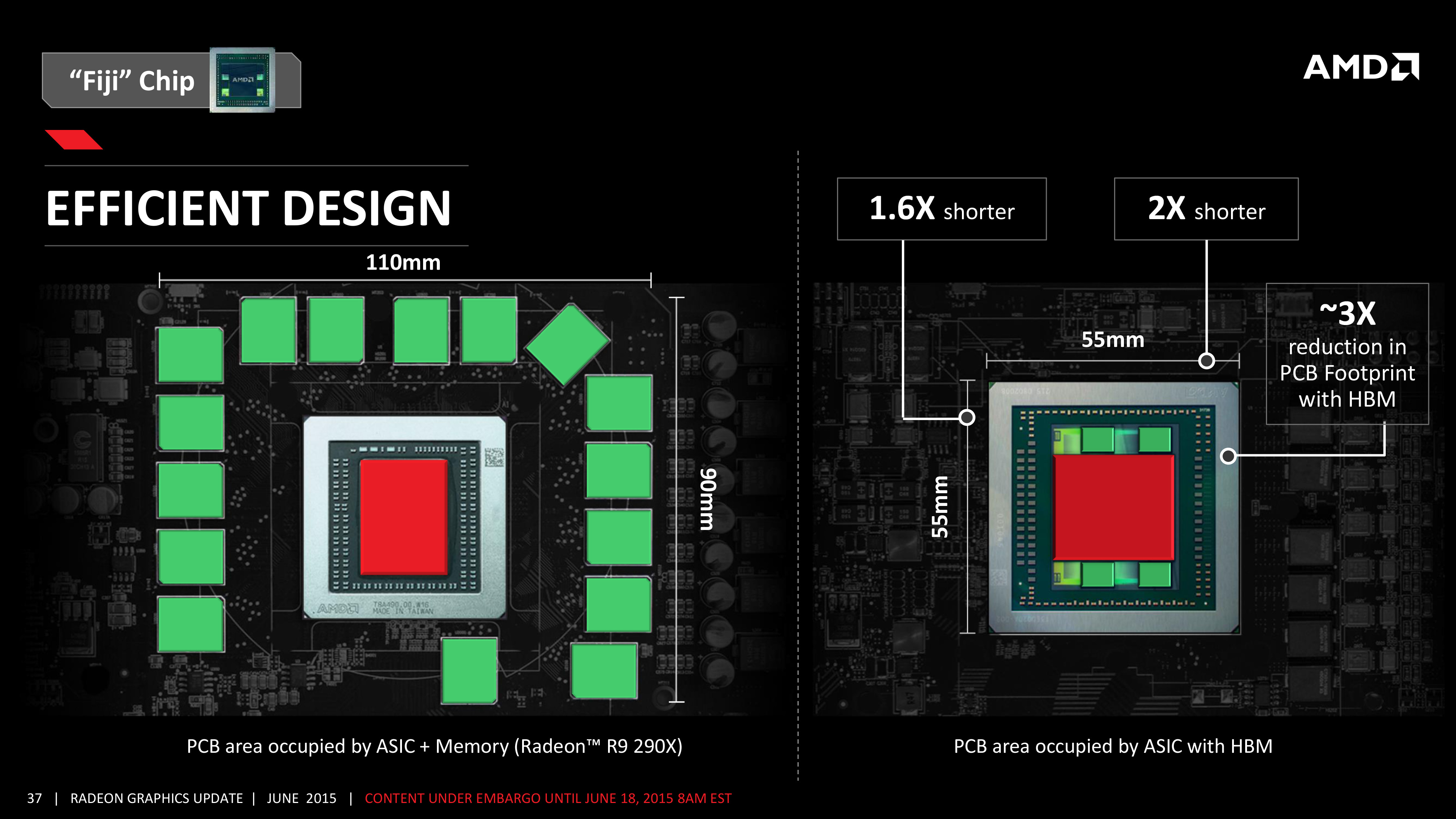
On the downside though, it is the bill of materials that is the biggest question hanging over HBM. Since HBM introduces several new technologies there are any number of things that can go wrong, all of which can drive up the costs. Of particular concern is the yield on the HBM memory stacks, as the TSV technology is especially intricate and said to be difficult to master. The interposer on the other hand is simpler, but it still represents something that has never been done before, and AMD admits upfront that the manufacturing facilities being used to create the interposer are old 65nm lines originally used for full chip production. So while the interposer does not approach the cost of a full logic chip, there is still the matter of the existing manufacturing lines being sub-optimal for high-volume low-cost production. Meanwhile AMD does get to enjoy some cost savings as well – the HBM PHYs are certainly much easier to implement than GDDR5 PHYs on Fiji itself, and the overall package is cheaper since it doesn't have GDDR5 memory running through it – though it's unlikely that these savings outweigh the other costs of implementing HBM at this time.
Ultimately AMD Is not willing to discuss HBM costs or yields at this time. Practically speaking it’s not a consumer matter – what matters to video card buyers is the $650 price tag on the R9 Fury X – and from a trade secrets perspective AMD is loath to share too much about what they have learned since they are the first HBM customer and want to enjoy as much of that advantage as is possible. At this point I feel it’s a safe bet that the 4GB HBM implementation on Fiji is costing AMD more than the 4GB (or even 8GB) GDDR5 implementations on Hawaii cards, but beyond that it’s difficult to say much more on costs.
That said, regardless of what the costs are now, HBM will be the future for AMD, and for the GPU industry as a whole. NVIDIA has already committed to using HBM technology for their high-end Pascal GPU in 2016, so AMD will be joined by other parties next year. Meanwhile AMD has much grander plans for HBM, intending to bring it to other products as costs allow. HBM on lower-priced GPUs is practically a given, meanwhile equipping AMD’s APUs with HBM would solve one of the greatest problems AMD faces today on the iGPU performance front, which is that 128-bit DDR3 bottlenecks the iGPU on their Kaveri APUs. AMD could build a better iGPU, if only they had more bandwidth to feed it with. This is a problem HBM is well positioned to solve.
Finally, at the end of the day what can’t be perfectly captured in words is AMD’s pride in being the first to roll out HBM. AMD was the first (and only) company to support GDDR4, they were the first company to support GDDR5, and now they are the first company to support HBM. The company has put significant resources into helping to develop the technology alongside Hynix, UMC, ASE, Amkor, and the JEDEC, and they see the launch of the technology as a testament to their engineering capabilities.
Furthermore they also see the fact that they are first as being a significant advantage going forward, as it means they have a generational advantage on arch-rival NVIDIA in implementing the technology. Case in point, NVIDIA’s first GDDR5 memory controller was by all accounts an underperformer, and it wasn’t until their second generation GDDR5 controller for Kepler that NVIDIA was able to hit (and even exceed) their aimed for memory clockspeeds. Admittedly this comes down to AMD hoping NVIDIA is going to stumble here, but at the end of the day the company is optimistic that all of their work is going to allow them to get more out of HBM than NVIDIA will be able to.








458 Comments
View All Comments
TallestJon96 - Saturday, July 4, 2015 - link
This card is not the disappointment people make it out to be. One month ago this card would have been a MASSIVE success. What is strange to me is that they didn't reduce price, even slightly to compete with the new 980 ti. I suspect it was to avoid a price war, but I would say at $600 this card is attractive, but at $650 you only really want it for water cooling. I suspect the price will drop more quickly than the 980 ti.mccoy3 - Saturday, July 4, 2015 - link
So it is as expensive as the 980Ti by delivering less performance and requires watercooling. Once Nvidia settles for a TITAN Y including HBM, its all over for the red guys.just4U - Saturday, July 4, 2015 - link
Well that would be great news for AMD though wouldn't it since Nvidia would have to pay for the use of HBM in some form or another..Oxford Guy - Saturday, July 4, 2015 - link
AMD could have released a hot leaf blower like the GTX 480 and chose not to.chizow - Monday, July 6, 2015 - link
No, they couldn't have. Fury X is already a 275W and that's with the benefit of low temp leakage using a WC *AND* the benefit of a self-professed 15-20W TDP surplus from HBM. That means in order for Fury X to still fall 10% short of 980Ti, it is already using 25+20W, so 45W more power.Their CUSTOM cooled 7/8th cut Fury is going to be 275W typical board power as well and its cut down, so yeah the difference in functional unit power is most likely going to be the same as the difference in thermal leakage due to operating temperatures between water and custom air cooling. A hot leaf blower, especially one as poor as AMD's reference would only be able to cool a 6/8 cut Fiji or lower, but at that point you might as well get a Hawaii based card.
Oxford Guy - Thursday, July 9, 2015 - link
Your posts don't even try to sound sane. I wrote about the GTX 480, which was designed to run hot and loud. Nvidia also couldn't release a fully-enabled chip.Ignore the point about the low-grade cooler on the 480 which ran hot and was very loud.
Ignore the point about the card being set to run hot, which hurt performance per watt (see this article if you don't get it).
How much is Nvidia paying you to astroturf? Whatever it is, it's too much.
Margalus - Monday, July 6, 2015 - link
this AMD card pumps out more heat than any NVidia card. Just because it runs a tad cooler with water cooling doesn't mean the heat is not there. It's just removed faster with water cooling, but the heat is still generated and the card will blow out a lot more hot air into the room than any NVidia card.Oxford Guy - Friday, July 10, 2015 - link
If you can't afford AC then stick with something like a 750 Ti. Otherwise the extra heat is hardly a big deal.zodiacfml - Saturday, July 4, 2015 - link
My excitement with HBM has subsided as I realized that this is too costly to be implemented in AMD's APUs even next year. Yet, I hope they do as soon as possible even if it would mean HBM on a narrower bus.jburns - Saturday, July 4, 2015 - link
Probably the best graphics card review I've ever read! Detailed and balanced... Thanks Ryan for an excellent review.